Scene-aware Human Motion Forecasting via Mutual Distance Prediction
2310.00615
0
0
🔮
Abstract
In this paper, we tackle the problem of scene-aware 3D human motion forecasting. A key challenge of this task is to predict future human motions that are consistent with the scene by modeling the human-scene interactions. While recent works have demonstrated that explicit constraints on human-scene interactions can prevent the occurrence of ghost motion, they only provide constraints on partial human motion e.g., the global motion of the human or a few joints contacting the scene, leaving the rest of the motion unconstrained. To address this limitation, we propose to model the human-scene interaction with the mutual distance between the human body and the scene. Such mutual distances constrain both the local and global human motion, resulting in a whole-body motion constrained prediction. In particular, mutual distance constraints consist of two components, the signed distance of each vertex on the human mesh to the scene surface and the distance of basis scene points to the human mesh. We further introduce a global scene representation learned from a signed distance function (SDF) volume to ensure coherence between the global scene representation and the explicit constraint from the mutual distance. We develop a pipeline with two sequential steps: predicting the future mutual distances first, followed by forecasting future human motion. During training, we explicitly encourage consistency between predicted poses and mutual distances. Extensive evaluations on the existing synthetic and real datasets demonstrate that our approach consistently outperforms the state-of-the-art methods.
Create account to get full access
Overview
- The paper presents a novel approach to predicting future 3D human motions that are consistent with the surrounding scene.
- The key challenge is to model the interactions between the human body and the scene to generate realistic future motions.
- The proposed method uses mutual distance constraints between the human body and the scene to capture both local and global human-scene interactions.
- A global scene representation is learned from a signed distance function (SDF) volume to ensure coherence between the scene and the mutual distance constraints.
- The method outperforms state-of-the-art techniques on both synthetic and real-world datasets.
Plain English Explanation
When predicting future human movements, it's important to make sure those movements are realistic and fit with the surrounding environment. This paper tackles the challenge of creating 3D human motion forecasts that are "scene-aware" - meaning they take into account the details of the physical scene the person is moving in.
Previous approaches have tried to constrain the human motion by explicitly modeling certain interactions with the scene, like the global position of the person or a few body parts touching objects. However, this only partially addresses the problem, leaving the rest of the body's motion unconstrained.
The researchers propose a new way to model the interaction between the human and the scene. They look at the mutual distance between the human body and the surfaces in the scene. This mutual distance constraint applies to the whole body, both globally and locally, ensuring the predicted motion is consistent with the scene.
They also introduce a global representation of the scene, learned from a signed distance function (SDF), to help maintain coherence between the scene and the mutual distance constraints. This is similar to other work on scene-aware human motion prediction.
The method works in two steps: first, it predicts the future mutual distances between the body and the scene, and then it uses that to forecast the future human motion. During training, the system is encouraged to keep the predicted poses consistent with the mutual distance constraints.
Evaluations on both synthetic and real-world datasets show that this approach outperforms existing state-of-the-art techniques for 3D human motion forecasting. This suggests it is an effective way to generate human motions that are grounded in the physical reality of the scene, which is an important capability for applications like generating co-speech gestures or modeling dynamic surface-based motions.
Technical Explanation
The paper presents a novel approach to the problem of scene-aware 3D human motion forecasting. The key innovation is the use of mutual distance constraints between the human body and the scene to model their interactions and generate future motions that are consistent with the environment.
Previous works have shown that explicitly constraining certain aspects of human-scene interaction, like the global position or a few contacting joints, can help prevent unrealistic "ghost" motions. However, these partial constraints leave the rest of the body's motion unconstrained.
To address this, the proposed method models the human-scene interaction using the mutual distance between the human mesh and the scene surfaces. This mutual distance constraint applies to all vertices on the human body, capturing both local and global interactions. Two components make up the mutual distance: the signed distance of each vertex to the scene, and the distance of key scene points to the human mesh.
Additionally, the researchers introduce a global scene representation learned from a signed distance function (SDF) volume. This helps maintain coherence between the scene and the mutual distance constraints during motion forecasting.
The pipeline works in two steps: first, it predicts the future mutual distances between the human and the scene. Then, it uses these predicted mutual distances to forecast the future human motion. During training, the system is explicitly encouraged to keep the predicted poses consistent with the mutual distance constraints.
Extensive evaluations on both synthetic and real-world datasets demonstrate that this approach consistently outperforms state-of-the-art methods for 3D human motion forecasting.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of scene-aware 3D human motion forecasting. By modeling the mutual distance between the human body and the scene surfaces, the method is able to generate future motions that are tightly coupled with the physical environment.
One potential limitation is that the mutual distance constraints may not fully capture all the nuances of human-scene interaction. For example, the approach does not explicitly model contact forces or friction between the body and scene elements. Incorporating such additional physical properties could further improve the realism of the predicted motions.
Additionally, the paper focuses on forecasting future motions given a known scene. An interesting extension would be to explore how the method could handle dynamic or partially observed scenes, where the future scene geometry is not fully known in advance.
Overall, this research represents an important step forward in the field of scene-aware human motion prediction. By grounding the motion forecasts in the physical properties of the environment, the approach has the potential to enable more realistic and faithful simulations of human behavior in various applications.
Conclusion
This paper presents a novel approach to 3D human motion forecasting that takes into account the surrounding scene. By modeling the mutual distance between the human body and the scene surfaces, the method is able to generate future motions that are consistent with the physical environment.
The key innovations are the use of mutual distance constraints to capture both local and global human-scene interactions, and the introduction of a global scene representation learned from a signed distance function (SDF) to maintain coherence between the scene and the constraints.
Extensive evaluations show that this scene-aware motion forecasting approach outperforms existing state-of-the-art techniques. This suggests it could be a valuable tool for applications that require realistic simulations of human behavior, such as co-speech gesture generation or dynamic surface-based motion modeling.
While the method has shown promising results, there are opportunities for further improvements, such as incorporating additional physical properties of the human-scene interaction. Overall, this research represents an important step forward in the field of scene-aware human motion prediction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
Multimodal Sense-Informed Prediction of 3D Human Motions
Zhenyu Lou, Qiongjie Cui, Haofan Wang, Xu Tang, Hong Zhou
0
0
Predicting future human pose is a fundamental application for machine intelligence, which drives robots to plan their behavior and paths ahead of time to seamlessly accomplish human-robot collaboration in real-world 3D scenarios. Despite encouraging results, existing approaches rarely consider the effects of the external scene on the motion sequence, leading to pronounced artifacts and physical implausibilities in the predictions. To address this limitation, this work introduces a novel multi-modal sense-informed motion prediction approach, which conditions high-fidelity generation on two modal information: external 3D scene, and internal human gaze, and is able to recognize their salience for future human activity. Furthermore, the gaze information is regarded as the human intention, and combined with both motion and scene features, we construct a ternary intention-aware attention to supervise the generation to match where the human wants to reach. Meanwhile, we introduce semantic coherence-aware attention to explicitly distinguish the salient point clouds and the underlying ones, to ensure a reasonable interaction of the generated sequence with the 3D scene. On two real-world benchmarks, the proposed method achieves state-of-the-art performance both in 3D human pose and trajectory prediction.
5/7/2024

Expressive Forecasting of 3D Whole-body Human Motions
Pengxiang Ding, Qiongjie Cui, Min Zhang, Mengyuan Liu, Haofan Wang, Donglin Wang
0
0
Human motion forecasting, with the goal of estimating future human behavior over a period of time, is a fundamental task in many real-world applications. However, existing works typically concentrate on predicting the major joints of the human body without considering the delicate movements of the human hands. In practical applications, hand gesture plays an important role in human communication with the real world, and expresses the primary intention of human beings. In this work, we are the first to formulate a whole-body human pose forecasting task, which jointly predicts the future body and hand activities. Correspondingly, we propose a novel Encoding-Alignment-Interaction (EAI) framework that aims to predict both coarse (body joints) and fine-grained (gestures) activities collaboratively, enabling expressive and cross-facilitated forecasting of 3D whole-body human motions. Specifically, our model involves two key constituents: cross-context alignment (XCA) and cross-context interaction (XCI). Considering the heterogeneous information within the whole-body, XCA aims to align the latent features of various human components, while XCI focuses on effectively capturing the context interaction among the human components. We conduct extensive experiments on a newly-introduced large-scale benchmark and achieve state-of-the-art performance. The code is public for research purposes at https://github.com/Dingpx/EAI.
4/5/2024
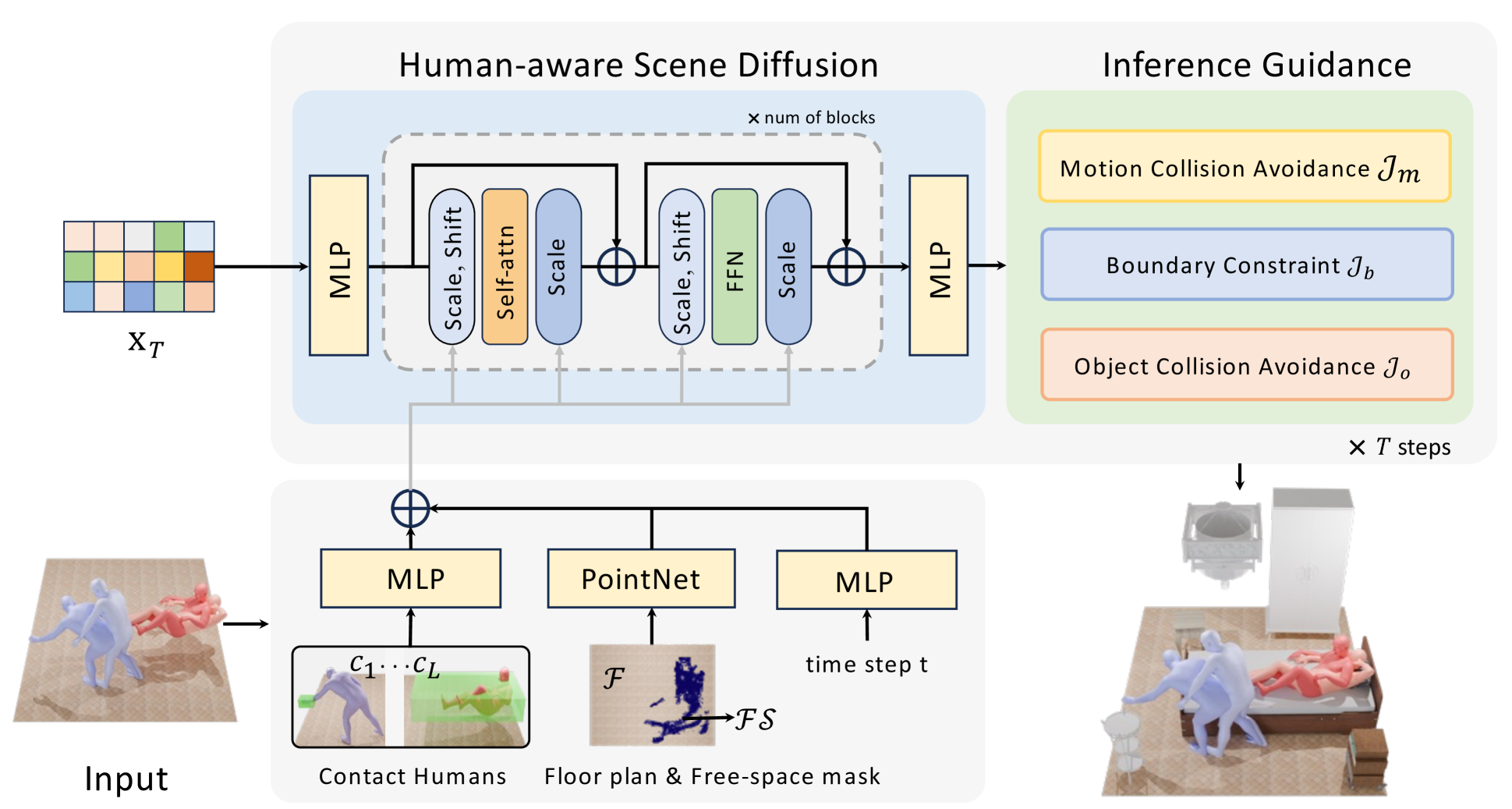
Human-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
Xiaolin Hong, Hongwei Yi, Fazhi He, Qiong Cao
0
0
Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
6/27/2024

A Unified Diffusion Framework for Scene-aware Human Motion Estimation from Sparse Signals
Jiangnan Tang, Jingya Wang, Kaiyang Ji, Lan Xu, Jingyi Yu, Ye Shi
0
0
Estimating full-body human motion via sparse tracking signals from head-mounted displays and hand controllers in 3D scenes is crucial to applications in AR/VR. One of the biggest challenges to this task is the one-to-many mapping from sparse observations to dense full-body motions, which endowed inherent ambiguities. To help resolve this ambiguous problem, we introduce a new framework to combine rich contextual information provided by scenes to benefit full-body motion tracking from sparse observations. To estimate plausible human motions given sparse tracking signals and 3D scenes, we develop $text{S}^2$Fusion, a unified framework fusing underline{S}cene and sparse underline{S}ignals with a conditional difunderline{Fusion} model. $text{S}^2$Fusion first extracts the spatial-temporal relations residing in the sparse signals via a periodic autoencoder, and then produces time-alignment feature embedding as additional inputs. Subsequently, by drawing initial noisy motion from a pre-trained prior, $text{S}^2$Fusion utilizes conditional diffusion to fuse scene geometry and sparse tracking signals to generate full-body scene-aware motions. The sampling procedure of $text{S}^2$Fusion is further guided by a specially designed scene-penetration loss and phase-matching loss, which effectively regularizes the motion of the lower body even in the absence of any tracking signals, making the generated motion much more plausible and coherent. Extensive experimental results have demonstrated that our $text{S}^2$Fusion outperforms the state-of-the-art in terms of estimation quality and smoothness.
4/9/2024