Towards Zero-Shot Multimodal Machine Translation

0

Sign in to get full access
Overview
- This paper explores the challenge of zero-shot multimodal machine translation (ZSMMT), which aims to translate text between languages without any parallel text-image data for those language pairs.
- The authors propose a novel Zero-Shot Multimodal Machine Translation (ZSMMT) framework that leverages multilingual text-image datasets and cross-lingual image-text alignment to enable zero-shot translation.
- The framework includes several key components, such as a text-image encoder, a cross-lingual image-text alignment module, and a multimodal translation decoder.
- Experiments on various benchmarks demonstrate the effectiveness of the proposed approach, outperforming existing ZSMMT methods.
Plain English Explanation
The paper tackles the challenge of zero-shot multimodal machine translation, which means translating text between languages without having any parallel text-image data for those language pairs. This is a difficult problem because machine translation systems typically rely on having lots of parallel text data to learn how to translate between languages.
The authors propose a new framework that can do this zero-shot translation by leveraging existing multilingual text-image datasets and cross-lingual image-text alignment. This means the system can learn how to translate between languages by studying how images are matched with text in different languages, even if it doesn't have direct translations between those languages.
The framework has several key components, including:
- A text-image encoder that can understand the relationship between images and text in different languages
- A cross-lingual image-text alignment module that can match images to their equivalent text in different languages
- A multimodal translation decoder that can use the image and text information to generate translations
Through experiments, the authors show that their proposed approach outperforms existing methods for zero-shot multimodal machine translation. This is an important step towards building translation systems that can work with limited data, which could be very useful for language pairs that don't have a lot of available parallel text-image data.
Technical Explanation
The paper presents a novel Zero-Shot Multimodal Machine Translation (ZSMMT) framework that enables translation between language pairs without any parallel text-image data. The key innovation is the leveraging of multilingual text-image datasets and cross-lingual image-text alignment to facilitate zero-shot translation.
The ZSMMT framework consists of three main components:
- Text-Image Encoder: This module learns joint text-image representations by encoding both modalities into a shared latent space. It builds on recent advancements in multimodal learning.
- Cross-Lingual Image-Text Alignment: This component aligns image-text pairs across different languages by exploiting the shared visual semantics. This is inspired by work on zero-shot context-aware translation.
- Multimodal Translation Decoder: The decoder takes the aligned multimodal representations and generates the translated text, effectively pushing the limits of zero-shot end-to-end translation.
The authors evaluate their ZSMMT framework on several benchmark datasets, including Multi30K and Flickr30K. The results demonstrate the efficacy of the proposed approach, outperforming existing zero-shot multimodal translation methods.
Critical Analysis
The paper presents a compelling solution to the challenging problem of zero-shot multimodal machine translation. By leveraging multilingual text-image datasets and cross-lingual alignment, the authors have developed a framework that can effectively translate between language pairs without requiring parallel text-image data.
One potential limitation of the approach is the reliance on the availability of high-quality multilingual text-image datasets. While the authors demonstrate strong performance on benchmark datasets, the scalability and generalization of the method to real-world scenarios with more diverse language pairs and data distributions remains to be explored.
Additionally, the paper does not provide a comprehensive analysis of the failure cases or edge cases of the proposed ZSMMT framework. Further investigation into the model's robustness and limitations would be valuable for understanding its practical applicability and identifying areas for future improvement.
Another area for future research could be the exploration of alternative cross-lingual alignment strategies or the integration of the ZSMMT framework with advanced multimodal translation models to further enhance the translation quality and flexibility.
Conclusion
This paper presents a significant advancement in the field of zero-shot multimodal machine translation. By introducing a novel framework that leverages multilingual text-image datasets and cross-lingual image-text alignment, the authors have demonstrated the feasibility of translating between language pairs without requiring parallel text-image data.
The proposed ZSMMT approach outperforms existing methods and paves the way for more flexible and accessible multimodal translation systems. As machine translation continues to evolve, this work highlights the importance of exploring multimodal and zero-shot strategies to overcome the limitations of traditional text-only translation models.
The insights and techniques developed in this paper could have far-reaching implications, enabling more inclusive and effective communication across language barriers, particularly in domains where visual information is crucial, such as in education, business, and cultural exchange.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Zero-Shot Multimodal Machine Translation
Matthieu Futeral, Cordelia Schmid, Beno^it Sagot, Rachel Bawden
Current multimodal machine translation (MMT) systems rely on fully supervised data (i.e models are trained on sentences with their translations and accompanying images). However, this type of data is costly to collect, limiting the extension of MMT to other language pairs for which such data does not exist. In this work, we propose a method to bypass the need for fully supervised data to train MMT systems, using multimodal English data only. Our method, called ZeroMMT, consists in adapting a strong text-only machine translation (MT) model by training it on a mixture of two objectives: visually conditioned masked language modelling and the Kullback-Leibler divergence between the original and new MMT outputs. We evaluate on standard MMT benchmarks and the recently released CoMMuTE, a contrastive benchmark aiming to evaluate how well models use images to disambiguate English sentences. We obtain disambiguation performance close to state-of-the-art MMT models trained additionally on fully supervised examples. To prove that our method generalizes to languages with no fully supervised training data available, we extend the CoMMuTE evaluation dataset to three new languages: Arabic, Russian and Chinese. We further show that we can control the trade-off between disambiguation capabilities and translation fidelity at inference time using classifier-free guidance and without any additional data. Our code, data and trained models are publicly accessible.
Read more7/19/2024
0
3AM: An Ambiguity-Aware Multi-Modal Machine Translation Dataset
Xinyu Ma, Xuebo Liu, Derek F. Wong, Jun Rao, Bei Li, Liang Ding, Lidia S. Chao, Dacheng Tao, Min Zhang
Multimodal machine translation (MMT) is a challenging task that seeks to improve translation quality by incorporating visual information. However, recent studies have indicated that the visual information provided by existing MMT datasets is insufficient, causing models to disregard it and overestimate their capabilities. This issue presents a significant obstacle to the development of MMT research. This paper presents a novel solution to this issue by introducing 3AM, an ambiguity-aware MMT dataset comprising 26,000 parallel sentence pairs in English and Chinese, each with corresponding images. Our dataset is specifically designed to include more ambiguity and a greater variety of both captions and images than other MMT datasets. We utilize a word sense disambiguation model to select ambiguous data from vision-and-language datasets, resulting in a more challenging dataset. We further benchmark several state-of-the-art MMT models on our proposed dataset. Experimental results show that MMT models trained on our dataset exhibit a greater ability to exploit visual information than those trained on other MMT datasets. Our work provides a valuable resource for researchers in the field of multimodal learning and encourages further exploration in this area. The data, code and scripts are freely available at https://github.com/MaxyLee/3AM.
Read more4/30/2024
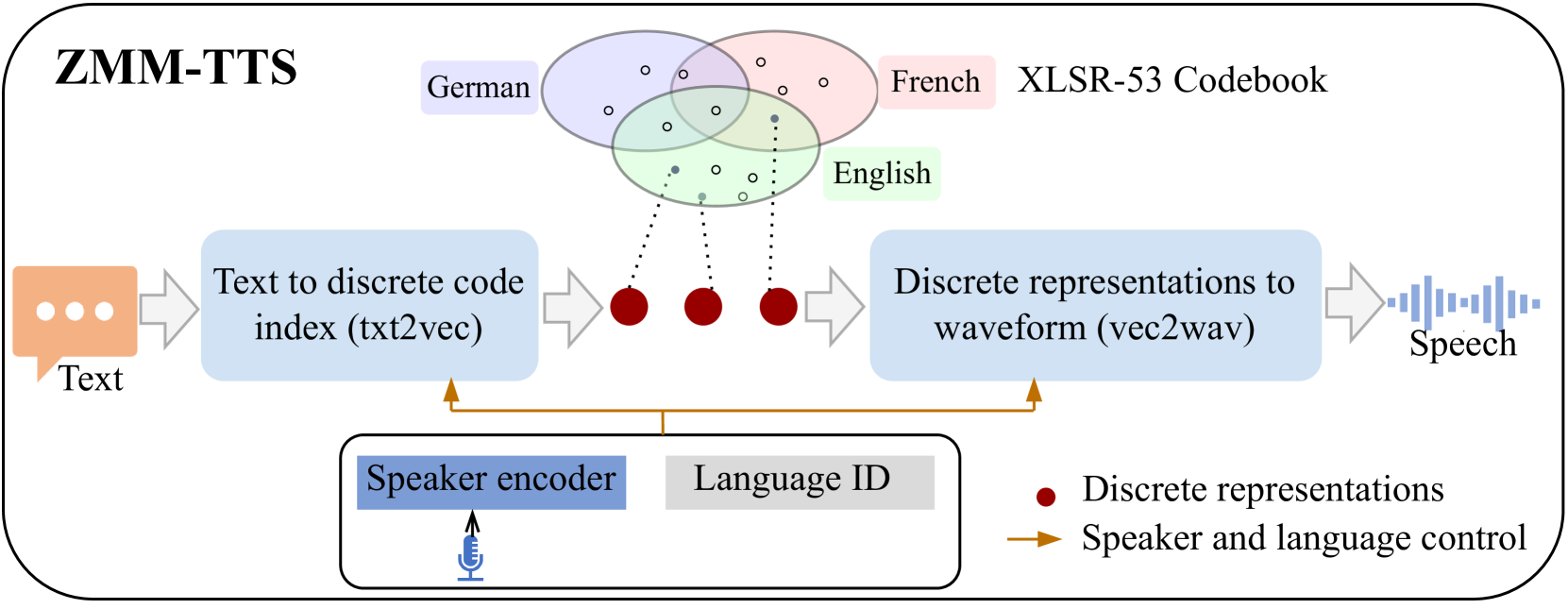
0
ZMM-TTS: Zero-shot Multilingual and Multispeaker Speech Synthesis Conditioned on Self-supervised Discrete Speech Representations
Cheng Gong, Xin Wang, Erica Cooper, Dan Wells, Longbiao Wang, Jianwu Dang, Korin Richmond, Junichi Yamagishi
Neural text-to-speech (TTS) has achieved human-like synthetic speech for single-speaker, single-language synthesis. Multilingual TTS systems are limited to resource-rich languages due to the lack of large paired text and studio-quality audio data. TTS systems are typically built using a single speaker's voices, but there is growing interest in developing systems that can synthesize voices for new speakers using only a few seconds of their speech. This paper presents ZMM-TTS, a multilingual and multispeaker framework utilizing quantized latent speech representations from a large-scale, pre-trained, self-supervised model. Our paper combines text-based and speech-based self-supervised learning models for multilingual speech synthesis. Our proposed model has zero-shot generalization ability not only for unseen speakers but also for unseen languages. We have conducted comprehensive subjective and objective evaluations through a series of experiments. Our model has proven effective in terms of speech naturalness and similarity for both seen and unseen speakers in six high-resource languages. We also tested the efficiency of our method on two hypothetically low-resource languages. The results are promising, indicating that our proposed approach can synthesize audio that is intelligible and has a high degree of similarity to the target speaker's voice, even without any training data for the new, unseen language.
Read more8/28/2024

0
Exploring the Necessity of Visual Modality in Multimodal Machine Translation using Authentic Datasets
Zi Long, Zhenhao Tang, Xianghua Fu, Jian Chen, Shilong Hou, Jinze Lyu
Recent research in the field of multimodal machine translation (MMT) has indicated that the visual modality is either dispensable or offers only marginal advantages. However, most of these conclusions are drawn from the analysis of experimental results based on a limited set of bilingual sentence-image pairs, such as Multi30k. In these kinds of datasets, the content of one bilingual parallel sentence pair must be well represented by a manually annotated image, which is different from the real-world translation scenario. In this work, we adhere to the universal multimodal machine translation framework proposed by Tang et al. (2022). This approach allows us to delve into the impact of the visual modality on translation efficacy by leveraging real-world translation datasets. Through a comprehensive exploration via probing tasks, we find that the visual modality proves advantageous for the majority of authentic translation datasets. Notably, the translation performance primarily hinges on the alignment and coherence between textual and visual contents. Furthermore, our results suggest that visual information serves a supplementary role in multimodal translation and can be substituted.
Read more4/10/2024