A Tractable Inference Perspective of Offline RL

0
🤯
Sign in to get full access
Overview
- This paper focuses on the challenge of offline Reinforcement Learning (RL), where the agent must learn a policy from a fixed dataset of past interactions, rather than actively exploring the environment.
- The key idea is to first fit a sequence model to the offline trajectories, and then use that model to generate actions that lead to high expected return.
- However, the paper highlights the importance of tractability - the ability to efficiently answer various probabilistic queries - in addition to just having an accurate sequence model.
- This is because the fundamental stochasticity from the offline data-collection policies and environment dynamics requires non-trivial conditional/constrained generation to elicit rewarding actions.
- The paper proposes "Trifle", a method that leverages Tractable Probabilistic Models (TPMs) to bridge the gap between good sequence models and high expected returns at evaluation time.
Plain English Explanation
Offline Reinforcement Learning (RL) is a challenging problem where the agent has to learn a policy from a fixed dataset of past interactions, instead of actively exploring the environment. A common approach is to first build a model that can predict the sequences of actions and states in the dataset, and then use that model to generate new actions that lead to high rewards.
However, this paper points out that having an accurate sequence model is not enough - the model also needs to be "tractable", meaning it can efficiently answer various probabilistic queries. This is important because the original data collection process and the environment itself are fundamentally stochastic, so the agent needs to be able to carefully consider the different possible outcomes when generating new actions.
To address this, the paper proposes a method called "Trifle" that uses a special type of probabilistic model called a "Tractable Probabilistic Model" (TPM). These models are designed to allow for efficient and exact computation of the required probabilistic queries, enabling Trifle to generate actions that lead to high rewards, even in stochastic environments or when there are constraints on the actions.
The key advantage of Trifle is that it can leverage expressive sequence models while still maintaining the necessary tractability, which the paper shows leads to state-of-the-art performance on a range of benchmark tasks.
Technical Explanation
The paper focuses on the problem of offline Reinforcement Learning (RL), where the agent must learn a policy from a fixed dataset of past interactions, rather than actively exploring the environment.
A popular approach is to first fit a sequence model to the offline trajectories, and then use that model to generate actions that lead to high expected return. In addition to obtaining accurate sequence models, the paper highlights that tractability - the ability to exactly and efficiently answer various probabilistic queries - plays a key role in offline RL.
This is because the fundamental stochasticity from the offline data-collection policies and the environment dynamics requires non-trivial conditional/constrained generation to elicit rewarding actions. While it is possible to approximate such queries, the paper observes that crude estimates can significantly undermine the benefits of expressive sequence models.
To overcome this problem, the paper proposes "Trifle" (Tractable Inference for Offline RL), which leverages modern Tractable Probabilistic Models (TPMs) to bridge the gap between good sequence models and high expected returns at evaluation time.
Empirically, the paper shows that Trifle achieves state-of-the-art scores on 9 Gym-MuJoCo benchmarks against strong baselines. Furthermore, due to its tractability, Trifle significantly outperforms prior approaches in stochastic environments and safe RL tasks (e.g., with action constraints) with minimum algorithmic modifications.
Critical Analysis
The paper makes a strong case for the importance of tractability in offline RL, beyond just having accurate sequence models. The proposed Trifle method demonstrates the benefits of leveraging Tractable Probabilistic Models (TPMs) to enable efficient and exact computation of the required probabilistic queries.
One limitation mentioned in the paper is that the current implementation of Trifle relies on a specific type of TPM, which may limit its generalizability. It would be interesting to see if the framework can be extended to a wider range of tractable models, or if there are ways to improve the tractability of more expressive sequence models.
Additionally, the paper focuses on standard benchmark tasks, which may not fully capture the real-world challenges of offline RL. It would be valuable to see how Trifle performs on more complex, realistic scenarios, such as those involving long-term dependencies, sparse rewards, or safety-critical constraints.
Finally, while the paper demonstrates the advantages of Trifle in terms of performance and tractability, it would be helpful to have a more detailed analysis of the computational and memory requirements of the method, as well as its sensitivity to hyperparameter tuning and dataset size.
Conclusion
This paper highlights the importance of tractability, in addition to accurate sequence modeling, for offline Reinforcement Learning (RL) tasks. The proposed Trifle method leverages Tractable Probabilistic Models (TPMs) to bridge the gap between good sequence models and high expected returns at evaluation time, leading to state-of-the-art performance on several benchmark tasks.
The key insight is that the fundamental stochasticity in offline RL requires sophisticated probabilistic reasoning, which can be facilitated by the use of TPMs. This suggests that future work in offline RL should focus not only on improving sequence models, but also on developing more expressive and tractable probabilistic frameworks to better capture the complexities of the problem.
Overall, the paper makes a valuable contribution to the field of offline RL by emphasizing the importance of tractability and demonstrating the effectiveness of the Trifle approach. As offline RL becomes increasingly relevant for real-world applications, the insights from this work could help pave the way for more robust and practical reinforcement learning algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
A Tractable Inference Perspective of Offline RL
Xuejie Liu, Anji Liu, Guy Van den Broeck, Yitao Liang
A popular paradigm for offline Reinforcement Learning (RL) tasks is to first fit the offline trajectories to a sequence model, and then prompt the model for actions that lead to high expected return. In addition to obtaining accurate sequence models, this paper highlights that tractability, the ability to exactly and efficiently answer various probabilistic queries, plays an important role in offline RL. Specifically, due to the fundamental stochasticity from the offline data-collection policies and the environment dynamics, highly non-trivial conditional/constrained generation is required to elicit rewarding actions. it is still possible to approximate such queries, we observe that such crude estimates significantly undermine the benefits brought by expressive sequence models. To overcome this problem, this paper proposes Trifle (Tractable Inference for Offline RL), which leverages modern Tractable Probabilistic Models (TPMs) to bridge the gap between good sequence models and high expected returns at evaluation time. Empirically, Trifle achieves the most state-of-the-art scores in 9 Gym-MuJoCo benchmarks against strong baselines. Further, owing to its tractability, Trifle significantly outperforms prior approaches in stochastic environments and safe RL tasks (e.g. with action constraints) with minimum algorithmic modifications.
Read more5/28/2024

0
Offline Policy Evaluation for Reinforcement Learning with Adaptively Collected Data
Sunil Madhow, Dan Qiao, Ming Yin, Yu-Xiang Wang
Developing theoretical guarantees on the sample complexity of offline RL methods is an important step towards making data-hungry RL algorithms practically viable. Currently, most results hinge on unrealistic assumptions about the data distribution -- namely that it comprises a set of i.i.d. trajectories collected by a single logging policy. We consider a more general setting where the dataset may have been gathered adaptively. We develop theory for the TMIS Offline Policy Evaluation (OPE) estimator in this generalized setting for tabular MDPs, deriving high-probability, instance-dependent bounds on its estimation error. We also recover minimax-optimal offline learning in the adaptive setting. Finally, we conduct simulations to empirically analyze the behavior of these estimators under adaptive and non-adaptive regimes.
Read more5/2/2024
0
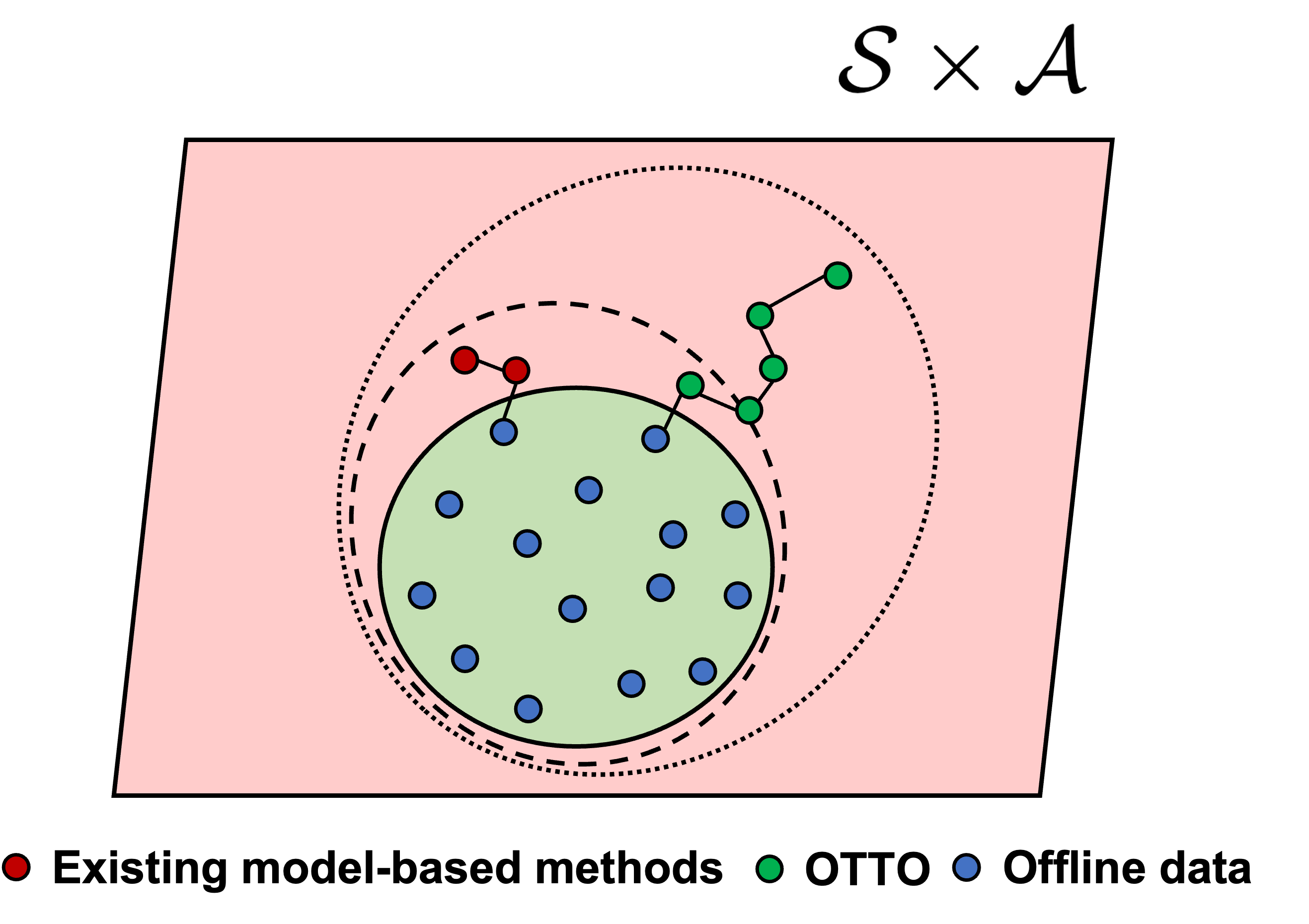
Offline Trajectory Generalization for Offline Reinforcement Learning
Ziqi Zhao, Zhaochun Ren, Liu Yang, Fajie Yuan, Pengjie Ren, Zhumin Chen, jun Ma, Xin Xin
Offline reinforcement learning (RL) aims to learn policies from static datasets of previously collected trajectories. Existing methods for offline RL either constrain the learned policy to the support of offline data or utilize model-based virtual environments to generate simulated rollouts. However, these methods suffer from (i) poor generalization to unseen states; and (ii) trivial improvement from low-qualified rollout simulation. In this paper, we propose offline trajectory generalization through world transformers for offline reinforcement learning (OTTO). Specifically, we use casual Transformers, a.k.a. World Transformers, to predict state dynamics and the immediate reward. Then we propose four strategies to use World Transformers to generate high-rewarded trajectory simulation by perturbing the offline data. Finally, we jointly use offline data with simulated data to train an offline RL algorithm. OTTO serves as a plug-in module and can be integrated with existing offline RL methods to enhance them with better generalization capability of transformers and high-rewarded data augmentation. Conducting extensive experiments on D4RL benchmark datasets, we verify that OTTO significantly outperforms state-of-the-art offline RL methods.
Read more4/17/2024
0
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
Read more6/27/2024