Training-Free Point Cloud Recognition Based on Geometric and Semantic Information Fusion

0

Sign in to get full access
Overview
- A training-free approach for point cloud recognition that fuses geometric and semantic information
- Aims to achieve high accuracy with few training samples, suitable for few-shot learning scenarios
- Key aspects include a geometry-aware feature encoder, semantic feature aggregation, and an efficient classification module
Plain English Explanation
This research paper presents a training-free point cloud recognition method that combines geometric and semantic information. The goal is to achieve high accuracy even when limited training data is available, making it suitable for few-shot learning scenarios.
The core idea is to use a geometry-aware feature encoder to extract relevant features from the point cloud, then aggregate these features in a semantically meaningful way. This fused representation is then passed to an efficient classification module to make the final predictions.
By leveraging both the geometric structure and semantic information of the point cloud, the method can recognize objects accurately even with a small number of training examples. This is particularly useful for applications where collecting large-scale labeled data is challenging, such as in indoor scene understanding or non-rigid point cloud matching.
Technical Explanation
The proposed method consists of three main components:
-
Geometry-aware Feature Encoder: This module takes the raw point cloud as input and learns a feature representation that preserves the underlying geometric structure. It uses a set of learnable geometric primitives (e.g., planes, spheres) to capture the local shape of the point cloud.
-
Semantic Feature Aggregation: The encoded geometric features are then aggregated based on their semantic information, which is obtained from a pre-trained language model. This step allows the system to group features with similar semantic meanings, enhancing the discriminative power of the final representation.
-
Efficient Classification Module: The fused geometric and semantic features are passed to a lightweight classification network, which outputs the final object predictions. This module is designed to be efficient, enabling fast inference even on resource-constrained devices.
The key novelty of this approach is the seamless integration of geometric and semantic information, without the need for any training data. By leveraging pre-trained models and knowledge distillation techniques, the method can learn robust feature representations and achieve high accuracy in few-shot learning scenarios.
Critical Analysis
The main strength of this approach is its ability to perform point cloud recognition without requiring any training data, making it suitable for applications with limited labeled data. The fusion of geometric and semantic information appears to be a clever strategy for enhancing the discriminative power of the learned features.
However, the paper does not discuss the potential limitations or drawbacks of this method. For example, it is unclear how the method would scale to more complex or diverse point cloud datasets, or how it would perform compared to supervised learning approaches with larger training sets.
Additionally, the authors do not provide a comprehensive analysis of the method's sensitivity to hyperparameters or the robustness of the results across different experimental settings. Further research is needed to better understand the broader applicability and limitations of this training-free point cloud recognition approach.
Conclusion
This research paper presents a novel training-free point cloud recognition method that leverages the fusion of geometric and semantic information. By avoiding the need for large-scale labeled training data, the proposed approach shows promise for few-shot learning scenarios where data collection is challenging.
The key contributions of this work include the geometry-aware feature encoder, the semantic feature aggregation strategy, and the efficient classification module. These components work together to enable high-accuracy point cloud recognition without any model training.
While the paper demonstrates the potential of this approach, further research is needed to fully understand its limitations and explore its broader applicability in real-world applications. Nonetheless, this work represents an important step towards more flexible and data-efficient point cloud recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Training-Free Point Cloud Recognition Based on Geometric and Semantic Information Fusion
Yan Chen, Di Huang, Zhichao Liao, Xi Cheng, Xinghui Li, Lone Zeng
The trend of employing training-free methods for point cloud recognition is becoming increasingly popular due to its significant reduction in computational resources and time costs. However, existing approaches are limited as they typically extract either geometric or semantic features. To address this limitation, we are the first to propose a novel training-free method that integrates both geometric and semantic features. For the geometric branch, we adopt a non-parametric strategy to extract geometric features. In the semantic branch, we leverage a model aligned with text features to obtain semantic features. Additionally, we introduce the GFE module to complement the geometric information of point clouds and the MFF module to improve performance in few-shot settings. Experimental results demonstrate that our method outperforms existing state-of-the-art training-free approaches on mainstream benchmark datasets, including ModelNet and ScanObiectNN.
Read more9/12/2024

0
Unsupervised Non-Rigid Point Cloud Matching through Large Vision Models
Zhangquan Chen, Puhua Jiang, Ruqi Huang
In this paper, we propose a novel learning-based framework for non-rigid point cloud matching, which can be trained purely on point clouds without any correspondence annotation but also be extended naturally to partial-to-full matching. Our key insight is to incorporate semantic features derived from large vision models (LVMs) to geometry-based shape feature learning. Our framework effectively leverages the structural information contained in the semantic features to address ambiguities arise from self-similarities among local geometries. Furthermore, our framework also enjoys the strong generalizability and robustness regarding partial observations of LVMs, leading to improvements in the regarding point cloud matching tasks. In order to achieve the above, we propose a pixel-to-point feature aggregation module, a local and global attention network as well as a geometrical similarity loss function. Experimental results show that our method achieves state-of-the-art results in matching non-rigid point clouds in both near-isometric and heterogeneous shape collection as well as more realistic partial and noisy data.
Read more8/19/2024
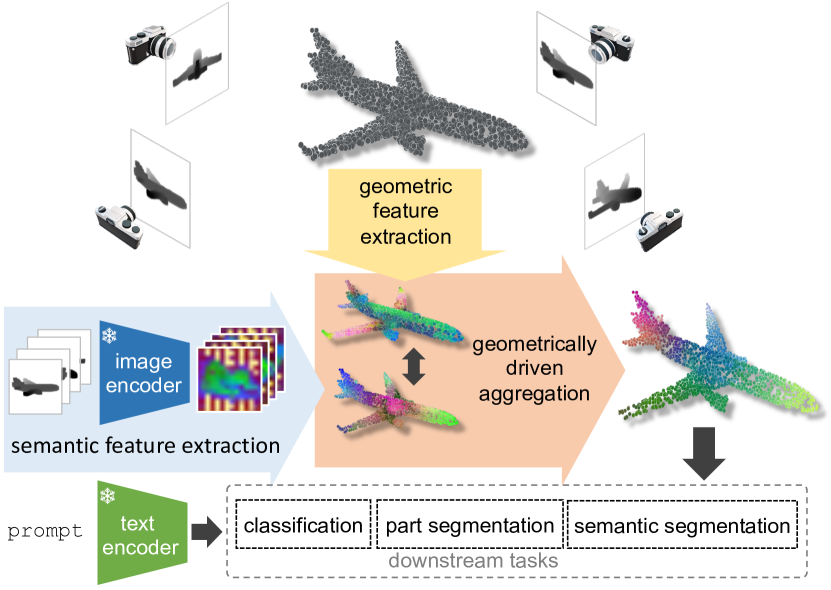
0
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at https://luigiriz.github.io/geoze-website/
Read more4/16/2024

0
CP-VoteNet: Contrastive Prototypical VoteNet for Few-Shot Point Cloud Object Detection
Xuejing Li, Weijia Zhang, Chao Ma
Few-shot point cloud 3D object detection (FS3D) aims to identify and localise objects of novel classes from point clouds, using knowledge learnt from annotated base classes and novel classes with very few annotations. Thus far, this challenging task has been approached using prototype learning, but the performance remains far from satisfactory. We find that in existing methods, the prototypes are only loosely constrained and lack of fine-grained awareness of the semantic and geometrical correlation embedded within the point cloud space. To mitigate these issues, we propose to leverage the inherent contrastive relationship within the semantic and geometrical subspaces to learn more refined and generalisable prototypical representations. To this end, we first introduce contrastive semantics mining, which enables the network to extract discriminative categorical features by constructing positive and negative pairs within training batches. Meanwhile, since point features representing local patterns can be clustered into geometric components, we further propose to impose contrastive relationship at the primitive level. Through refined primitive geometric structures, the transferability of feature encoding from base to novel classes is significantly enhanced. The above designs and insights lead to our novel Contrastive Prototypical VoteNet (CP-VoteNet). Extensive experiments on two FS3D benchmarks FS-ScanNet and FS-SUNRGBD demonstrate that CP-VoteNet surpasses current state-of-the-art methods by considerable margins across different FS3D settings. Further ablation studies conducted corroborate the rationale and effectiveness of our designs.
Read more9/2/2024