Unsupervised Non-Rigid Point Cloud Matching through Large Vision Models

0

Sign in to get full access
Overview
- Unsupervised non-rigid point cloud matching using large vision models
- Leverages the capabilities of pre-trained vision models for point cloud alignment without supervision
- Applicable to various 3D perception tasks like object detection, segmentation, and registration
Plain English Explanation
This research paper presents a novel approach to matching non-rigid point clouds in an unsupervised manner by harnessing the power of large pre-trained vision models. Point clouds are 3D representations of objects or scenes captured by sensors like LiDAR. Matching these point clouds is crucial for applications like 3D object detection and scene registration.
The key insight is that large vision models, trained on massive datasets of 2D images, have developed a rich understanding of visual patterns and geometry that can be effectively transferred to 3D point cloud data. By leveraging these pre-trained models, the researchers demonstrate that point cloud matching can be achieved without the need for laborious supervised training, making the process more efficient and scalable.
The approach involves converting the 3D point cloud data into a 2D image-like representation, which can then be processed by the pre-trained vision model. This allows the model to extract meaningful features and geometric information from the point clouds, which are then used to align and match them in an unsupervised manner.
Technical Explanation
The paper introduces an unsupervised point cloud matching framework that utilizes the capabilities of large-scale pre-trained vision models, such as CLIP and DINO.
The key steps of the proposed approach are:
-
Point Cloud Projection: The 3D point cloud data is projected onto 2D image-like representations using techniques like Spherical Projection and Orthogonal Projection. This allows the point cloud data to be processed by the pre-trained vision models.
-
Feature Extraction: The 2D projected point cloud representations are fed into the pre-trained vision models, which extract rich visual features and geometric information from the data.
-
Matching and Alignment: The extracted features are then used to match and align the point clouds in an unsupervised manner, without the need for labeled training data.
The researchers evaluate their approach on various 3D perception tasks, including object detection, segmentation, and registration. The results demonstrate the effectiveness of leveraging large vision models for unsupervised non-rigid point cloud matching, outperforming traditional methods and opening up new opportunities for 3D perception tasks.
Critical Analysis
The paper presents a promising approach, but it is essential to consider the potential limitations and areas for further research:
-
Data Representation: The performance of the approach may be sensitive to the choice of 2D projection techniques used to convert the 3D point cloud data. Exploring alternative representations or hybrid approaches could potentially improve the matching accuracy.
-
Model Generalization: While the pre-trained vision models demonstrate impressive capabilities, their performance may be influenced by the specific datasets and tasks they were trained on. Evaluating the model's ability to generalize to diverse point cloud data and scenarios would be important.
-
Computational Efficiency: The use of large pre-trained models may introduce computational overhead, especially for real-time or resource-constrained applications. Investigating ways to optimize the inference and matching processes would be valuable.
-
Interpretability: As with many deep learning-based approaches, the inner workings of the model can be challenging to interpret. Providing more insights into the specific features and geometric information learned by the vision models could enhance the overall understanding and trust in the system.
Conclusion
This research demonstrates a novel and promising approach to unsupervised non-rigid point cloud matching by leveraging the power of large-scale pre-trained vision models. By bridging the gap between 2D image understanding and 3D point cloud data, the proposed framework enables efficient and scalable point cloud alignment without the need for supervised training. The results highlight the potential of this approach to significantly impact various 3D perception tasks, such as object detection, segmentation, and registration. As the field of 3D computer vision continues to evolve, this work paves the way for further advancements in unsupervised 3D data processing and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unsupervised Non-Rigid Point Cloud Matching through Large Vision Models
Zhangquan Chen, Puhua Jiang, Ruqi Huang
In this paper, we propose a novel learning-based framework for non-rigid point cloud matching, which can be trained purely on point clouds without any correspondence annotation but also be extended naturally to partial-to-full matching. Our key insight is to incorporate semantic features derived from large vision models (LVMs) to geometry-based shape feature learning. Our framework effectively leverages the structural information contained in the semantic features to address ambiguities arise from self-similarities among local geometries. Furthermore, our framework also enjoys the strong generalizability and robustness regarding partial observations of LVMs, leading to improvements in the regarding point cloud matching tasks. In order to achieve the above, we propose a pixel-to-point feature aggregation module, a local and global attention network as well as a geometrical similarity loss function. Experimental results show that our method achieves state-of-the-art results in matching non-rigid point clouds in both near-isometric and heterogeneous shape collection as well as more realistic partial and noisy data.
Read more8/19/2024
0
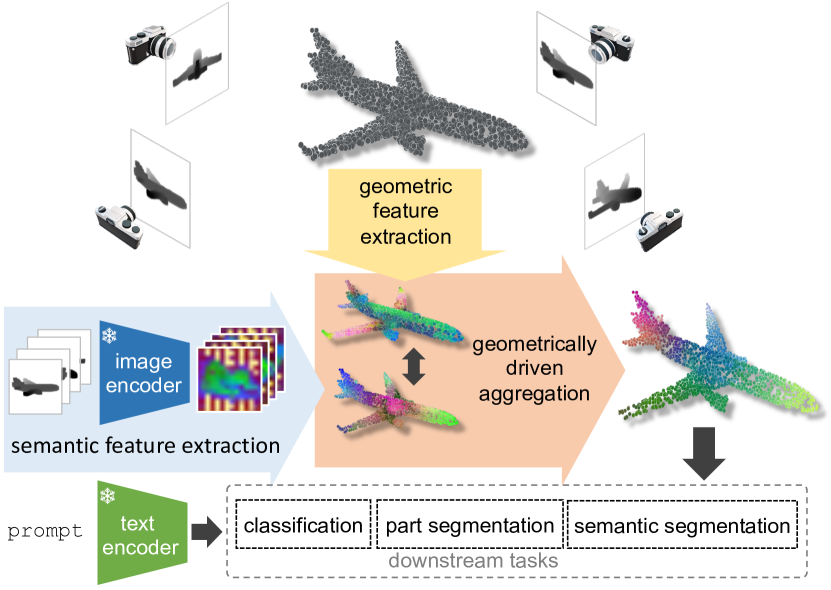
Geometrically-driven Aggregation for Zero-shot 3D Point Cloud Understanding
Guofeng Mei, Luigi Riz, Yiming Wang, Fabio Poiesi
Zero-shot 3D point cloud understanding can be achieved via 2D Vision-Language Models (VLMs). Existing strategies directly map Vision-Language Models from 2D pixels of rendered or captured views to 3D points, overlooking the inherent and expressible point cloud geometric structure. Geometrically similar or close regions can be exploited for bolstering point cloud understanding as they are likely to share semantic information. To this end, we introduce the first training-free aggregation technique that leverages the point cloud's 3D geometric structure to improve the quality of the transferred Vision-Language Models. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. We benchmark our approach on three downstream tasks, including classification, part segmentation, and semantic segmentation, with a variety of datasets representing both synthetic/real-world, and indoor/outdoor scenarios. Our approach achieves new state-of-the-art results in all benchmarks. Our approach operates iteratively, performing local-to-global aggregation based on geometric and semantic point-level reasoning. Code and dataset are available at https://luigiriz.github.io/geoze-website/
Read more4/16/2024

0
Training-Free Point Cloud Recognition Based on Geometric and Semantic Information Fusion
Yan Chen, Di Huang, Zhichao Liao, Xi Cheng, Xinghui Li, Lone Zeng
The trend of employing training-free methods for point cloud recognition is becoming increasingly popular due to its significant reduction in computational resources and time costs. However, existing approaches are limited as they typically extract either geometric or semantic features. To address this limitation, we are the first to propose a novel training-free method that integrates both geometric and semantic features. For the geometric branch, we adopt a non-parametric strategy to extract geometric features. In the semantic branch, we leverage a model aligned with text features to obtain semantic features. Additionally, we introduce the GFE module to complement the geometric information of point clouds and the MFF module to improve performance in few-shot settings. Experimental results demonstrate that our method outperforms existing state-of-the-art training-free approaches on mainstream benchmark datasets, including ModelNet and ScanObiectNN.
Read more9/12/2024

0
Geometry-aware Feature Matching for Large-Scale Structure from Motion
Gonglin Chen, Jinsen Wu, Haiwei Chen, Wenbin Teng, Zhiyuan Gao, Andrew Feng, Rongjun Qin, Yajie Zhao
Establishing consistent and dense correspondences across multiple images is crucial for Structure from Motion (SfM) systems. Significant view changes, such as air-to-ground with very sparse view overlap, pose an even greater challenge to the correspondence solvers. We present a novel optimization-based approach that significantly enhances existing feature matching methods by introducing geometry cues in addition to color cues. This helps fill gaps when there is less overlap in large-scale scenarios. Our method formulates geometric verification as an optimization problem, guiding feature matching within detector-free methods and using sparse correspondences from detector-based methods as anchor points. By enforcing geometric constraints via the Sampson Distance, our approach ensures that the denser correspondences from detector-free methods are geometrically consistent and more accurate. This hybrid strategy significantly improves correspondence density and accuracy, mitigates multi-view inconsistencies, and leads to notable advancements in camera pose accuracy and point cloud density. It outperforms state-of-the-art feature matching methods on benchmark datasets and enables feature matching in challenging extreme large-scale settings.
Read more9/14/2024