A Training Rate and Survival Heuristic for Inference and Robustness Evaluation (TRASHFIRE)

0

Sign in to get full access
Overview
- This paper presents a systematic approach to modeling the robustness of deep convolutional neural networks (DCNNs).
- The researchers focus on understanding how various factors, such as network architecture and training data, impact the robustness of DCNNs.
- They propose a framework for quantifying and analyzing the robustness of DCNNs to various types of perturbations.
Plain English Explanation
Deep learning models, such as deep convolutional neural networks, have become incredibly powerful, but they can also be vulnerable to small changes in their input data. This can be a problem when using these models in real-world applications, where the input data may not be perfect.
The researchers in this paper wanted to better understand what factors influence the robustness of deep learning models. They focused on deep convolutional neural networks (DCNNs), which are a type of deep learning model that are particularly good at analyzing images.
The researchers developed a systematic framework for evaluating the robustness of DCNNs to different types of perturbations, such as changes in brightness, contrast, or the addition of noise. They tested how factors like the network architecture and the training data used to create the model affected the model's robustness.
By understanding what makes deep learning models more or less robust, the researchers hope to be able to design more reliable and trustworthy AI systems that can be used in real-world applications.
Technical Explanation
The paper presents a systematic approach to evaluating the robustness of deep convolutional neural networks (DCNNs). The researchers first define a framework for quantifying the robustness of DCNNs, which involves subjecting the models to various types of perturbations and measuring their performance.
The researchers then conduct a series of experiments to understand how different factors, such as network architecture and training data, impact the robustness of DCNNs. They test the models' performance on a range of perturbations, including changes in brightness, contrast, and the addition of noise.
The results of the experiments show that both network architecture and training data can have a significant impact on the robustness of DCNNs. The researchers find that certain architectural features, such as skip connections, can improve robustness, while the choice of training data can also play a crucial role.
The paper provides valuable insights into the factors that influence the robustness of deep learning models, which can inform the design of more reliable and trustworthy AI systems.
Critical Analysis
The paper provides a comprehensive and systematic approach to modeling the robustness of DCNNs, which is a significant contribution to the field of deep learning. However, the researchers acknowledge several limitations and areas for further research.
One limitation is that the study primarily focuses on image classification tasks, and the findings may not generalize to other types of deep learning applications, such as natural language processing or reinforcement learning. Additionally, the researchers only consider a limited set of perturbations, and there may be other types of perturbations that could be explored in future studies.
Another potential issue is that the experiments were conducted on a relatively small number of datasets and models, and the findings may not be representative of the broader landscape of deep learning research. It would be valuable to see the approach applied to a wider range of datasets and model architectures to assess its generalizability.
Despite these limitations, the paper presents a robust and well-designed framework for evaluating the robustness of DCNNs, which could be a valuable tool for researchers and practitioners working on developing more reliable and trustworthy AI systems.
Conclusion
This paper introduces a systematic approach to modeling the robustness of deep convolutional neural networks (DCNNs). The researchers develop a framework for quantifying the robustness of DCNNs and conduct a series of experiments to understand how factors such as network architecture and training data impact the models' performance under various perturbations.
The findings of the paper provide valuable insights into the factors that influence the robustness of deep learning models, which can inform the design of more reliable and trustworthy AI systems. While the study has some limitations, the systematic and rigorous approach presented in the paper represents an important contribution to the field of deep learning research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Training Rate and Survival Heuristic for Inference and Robustness Evaluation (TRASHFIRE)
Charles Meyers, Mohammad Reza Saleh Sedghpour, Tommy Lofstedt, Erik Elmroth
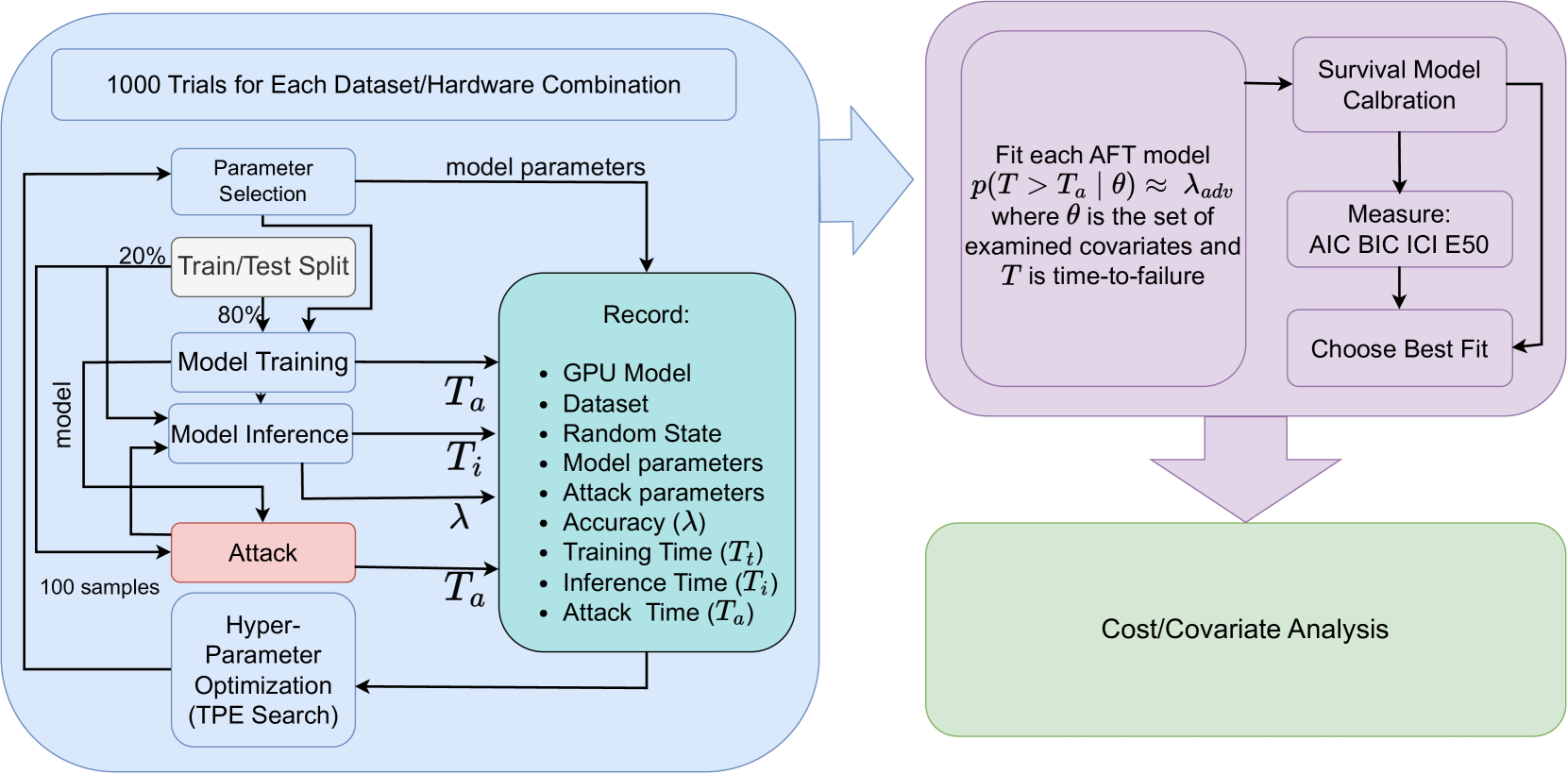
Machine learning models -- deep neural networks in particular -- have performed remarkably well on benchmark datasets across a wide variety of domains. However, the ease of finding adversarial counter-examples remains a persistent problem when training times are measured in hours or days and the time needed to find a successful adversarial counter-example is measured in seconds. Much work has gone into generating and defending against these adversarial counter-examples, however the relative costs of attacks and defences are rarely discussed. Additionally, machine learning research is almost entirely guided by test/train metrics, but these would require billions of samples to meet industry standards. The present work addresses the problem of understanding and predicting how particular model hyper-parameters influence the performance of a model in the presence of an adversary. The proposed approach uses survival models, worst-case examples, and a cost-aware analysis to precisely and accurately reject a particular model change during routine model training procedures rather than relying on real-world deployment, expensive formal verification methods, or accurate simulations of very complicated systems (textit{e.g.}, digitally recreating every part of a car or a plane). Through an evaluation of many pre-processing techniques, adversarial counter-examples, and neural network configurations, the conclusion is that deeper models do offer marginal gains in survival times compared to more shallow counterparts. However, we show that those gains are driven more by the model inference time than inherent robustness properties. Using the proposed methodology, we show that ResNet is hopelessly insecure against even the simplest of white box attacks.
Read more9/14/2024
0
A Cost-Aware Approach to Adversarial Robustness in Neural Networks
Charles Meyers, Mohammad Reza Saleh Sedghpour, Tommy Lofstedt, Erik Elmroth
Considering the growing prominence of production-level AI and the threat of adversarial attacks that can evade a model at run-time, evaluating the robustness of models to these evasion attacks is of critical importance. Additionally, testing model changes likely means deploying the models to (e.g. a car or a medical imaging device), or a drone to see how it affects performance, making un-tested changes a public problem that reduces development speed, increases cost of development, and makes it difficult (if not impossible) to parse cause from effect. In this work, we used survival analysis as a cloud-native, time-efficient and precise method for predicting model performance in the presence of adversarial noise. For neural networks in particular, the relationships between the learning rate, batch size, training time, convergence time, and deployment cost are highly complex, so researchers generally rely on benchmark datasets to assess the ability of a model to generalize beyond the training data. To address this, we propose using accelerated failure time models to measure the effect of hardware choice, batch size, number of epochs, and test-set accuracy by using adversarial attacks to induce failures on a reference model architecture before deploying the model to the real world. We evaluate several GPU types and use the Tree Parzen Estimator to maximize model robustness and minimize model run-time simultaneously. This provides a way to evaluate the model and optimise it in a single step, while simultaneously allowing us to model the effect of model parameters on training time, prediction time, and accuracy. Using this technique, we demonstrate that newer, more-powerful hardware does decrease the training time, but with a monetary and power cost that far outpaces the marginal gains in accuracy.
Read more9/14/2024
0
From Attack to Defense: Insights into Deep Learning Security Measures in Black-Box Settings
Firuz Juraev, Mohammed Abuhamad, Eric Chan-Tin, George K. Thiruvathukal, Tamer Abuhmed
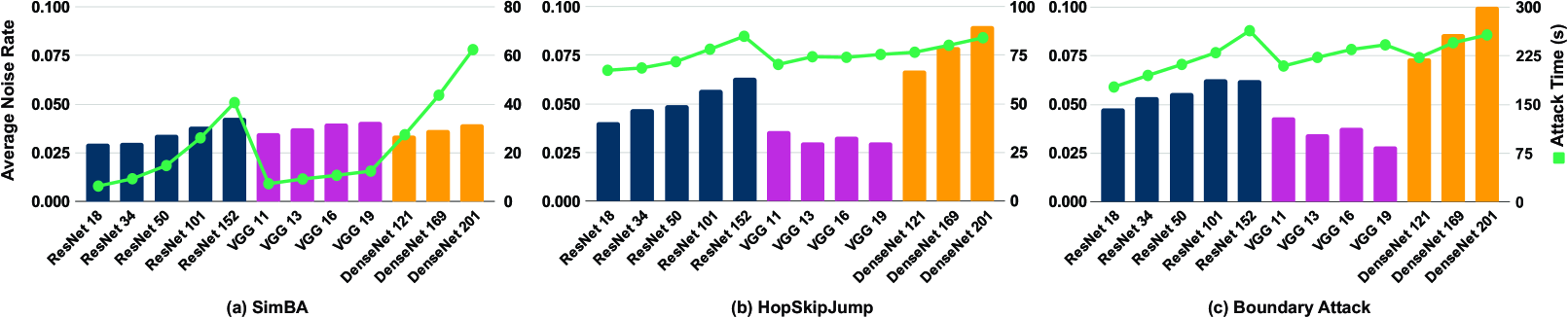
Deep Learning (DL) is rapidly maturing to the point that it can be used in safety- and security-crucial applications. However, adversarial samples, which are undetectable to the human eye, pose a serious threat that can cause the model to misbehave and compromise the performance of such applications. Addressing the robustness of DL models has become crucial to understanding and defending against adversarial attacks. In this study, we perform comprehensive experiments to examine the effect of adversarial attacks and defenses on various model architectures across well-known datasets. Our research focuses on black-box attacks such as SimBA, HopSkipJump, MGAAttack, and boundary attacks, as well as preprocessor-based defensive mechanisms, including bits squeezing, median smoothing, and JPEG filter. Experimenting with various models, our results demonstrate that the level of noise needed for the attack increases as the number of layers increases. Moreover, the attack success rate decreases as the number of layers increases. This indicates that model complexity and robustness have a significant relationship. Investigating the diversity and robustness relationship, our experiments with diverse models show that having a large number of parameters does not imply higher robustness. Our experiments extend to show the effects of the training dataset on model robustness. Using various datasets such as ImageNet-1000, CIFAR-100, and CIFAR-10 are used to evaluate the black-box attacks. Considering the multiple dimensions of our analysis, e.g., model complexity and training dataset, we examined the behavior of black-box attacks when models apply defenses. Our results show that applying defense strategies can significantly reduce attack effectiveness. This research provides in-depth analysis and insight into the robustness of DL models against various attacks, and defenses.
Read more5/6/2024
0
How to Train your Antivirus: RL-based Hardening through the Problem-Space
Ilias Tsingenopoulos, Jacopo Cortellazzi, Branislav Bov{s}ansk'y, Simone Aonzo, Davy Preuveneers, Wouter Joosen, Fabio Pierazzi, Lorenzo Cavallaro
ML-based malware detection on dynamic analysis reports is vulnerable to both evasion and spurious correlations. In this work, we investigate a specific ML architecture employed in the pipeline of a widely-known commercial antivirus company, with the goal to harden it against adversarial malware. Adversarial training, the sole defensive technique that can confer empirical robustness, is not applicable out of the box in this domain, for the principal reason that gradient-based perturbations rarely map back to feasible problem-space programs. We introduce a novel Reinforcement Learning approach for constructing adversarial examples, a constituent part of adversarially training a model against evasion. Our approach comes with multiple advantages. It performs modifications that are feasible in the problem-space, and only those; thus it circumvents the inverse mapping problem. It also makes possible to provide theoretical guarantees on the robustness of the model against a particular set of adversarial capabilities. Our empirical exploration validates our theoretical insights, where we can consistently reach 0% Attack Success Rate after a few adversarial retraining iterations.
Read more9/6/2024