Transfer Learning with Informative Priors: Simple Baselines Better than Previously Reported

0
🔄
Sign in to get full access
Overview
- The paper explores the use of transfer learning to improve the performance of machine learning classifiers on target tasks with limited labeled data.
- It compares the effectiveness of standard transfer learning (using only initialization from a source task) with methods that learn an informative prior distribution over neural network weights from the source task.
- The authors conduct experiments across 5 datasets to evaluate the relative gains of these approaches, finding that the benefits of using informed priors vary significantly depending on the dataset.
Plain English Explanation
Transfer learning is a technique where a machine learning model trained on one task (the "source" task) is used to jumpstart the training of a model on a related but different "target" task. This can be especially helpful when there is limited labeled data available for the target task.
The key idea explored in this paper is that instead of just using the source task to initialize the weights of the target model (the standard approach), we can also use the source task to learn an informative prior distribution over the model's weights. This prior distribution can then be used to guide the training of the target model, potentially leading to better performance.
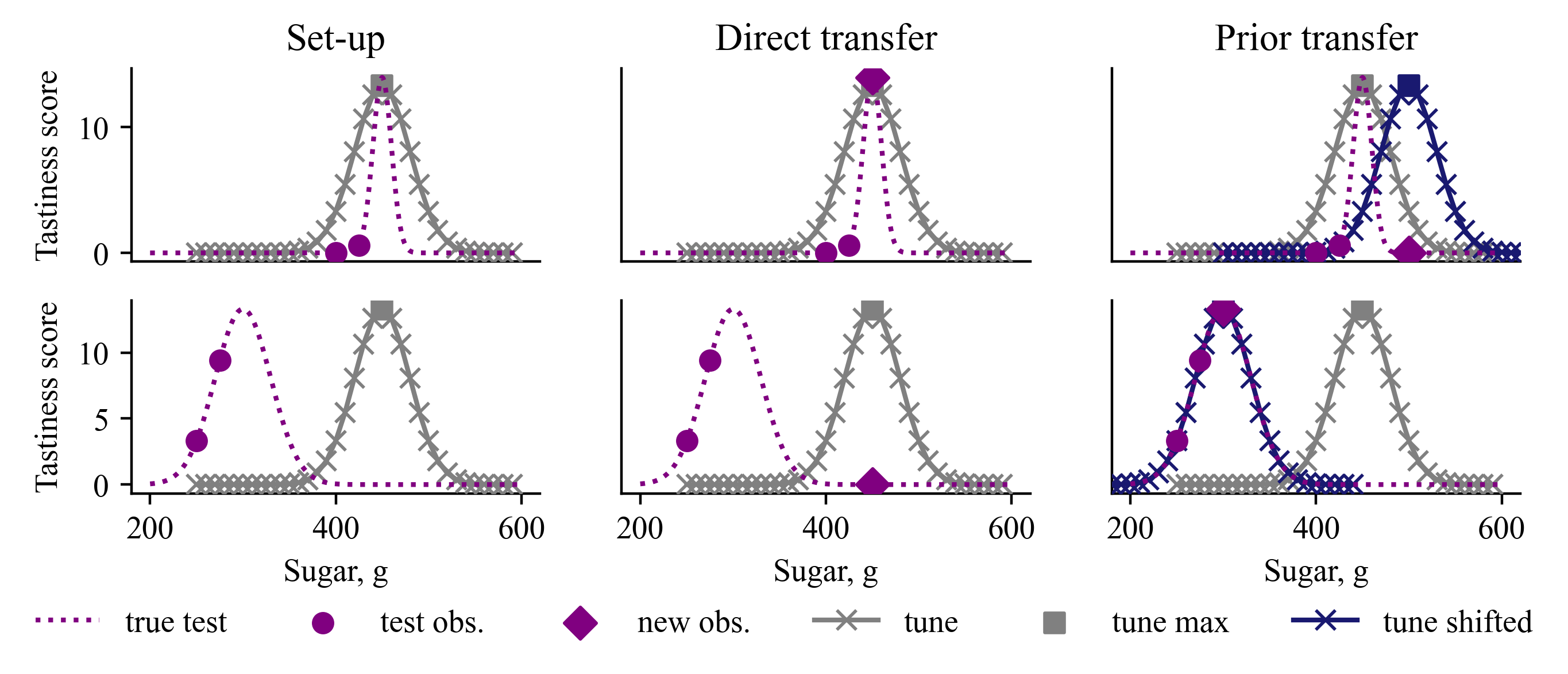
The authors compare this approach of learning an informative prior to the standard transfer learning technique across 5 different datasets. They find that the relative benefits of using an informed prior vary quite a bit depending on the dataset. For some datasets, there was no significant improvement over standard transfer learning, while for others, the gains were substantial (over 8 percentage points of accuracy).
The paper also explores different ways of representing the informed prior, finding that a simple isotropic (spherical) covariance matrix can perform competitively with more complex learned low-rank covariance matrices. This is an important practical finding, as the simpler isotropic prior is much easier to understand and tune.
Overall, this paper provides a nuanced view of the potential benefits of using informative priors for transfer learning, highlighting the need to carefully evaluate these techniques on a case-by-case basis depending on the target task and dataset.
Technical Explanation
The paper focuses on the problem of transfer learning, where the goal is to improve the performance of a classifier on a target task by leveraging knowledge from a related source task. The authors specifically investigate the use of informative priors over the neural network weights, learned from the source task, to guide the training of the target model.
The experimental setup involves training classifiers on 5 different datasets, comparing standard transfer learning (using only the source task initialization) to methods that also use an informed prior distribution over the weights. The authors consider two approaches for representing the informed prior: an isotropic Gaussian (a simple spherical covariance matrix) and a low-rank Gaussian (a more complex covariance matrix learned from the source task).
The key findings of the paper are:
-
Standard transfer learning performs better than previously reported: The authors find that standard transfer learning (using only the source task initialization) performs substantially better than what has been reported in prior work, especially in the regime of 5-300 examples per class in the target task.
-
Benefits of informed priors vary across datasets: The relative gains of using informed priors over standard transfer learning range from negligible or negative to substantial (over 8 percentage points of accuracy), depending on the dataset.
-
Isotropic prior can be competitive with learned low-rank prior: The simpler isotropic Gaussian prior appears to perform competitively with the more complex low-rank Gaussian prior, while being much easier to understand and tune.
-
Mechanistic justification for informed priors is not consistently supported: Further analysis suggests that the proposed justification for informed priors (improved alignment between train and test loss landscapes) is not consistently supported due to high variability in the empirical loss landscapes.
The authors release code to allow independent reproduction of all experiments, which is a valuable contribution to the research community.
Critical Analysis
The paper provides a nuanced and thorough evaluation of the potential benefits of using informed priors for transfer learning, which is a valuable contribution to the field. The authors' careful experimental design and analysis across multiple datasets offer important insights into when and how these techniques can be effectively applied.
However, the paper also highlights some limitations and areas for further research. The finding that the mechanistic justification for informed priors is not consistently supported is intriguing and suggests that the underlying reasons for their effectiveness may be more complex than the proposed alignment between train and test loss landscapes.
Additionally, the authors note that the relative benefits of informed priors can vary substantially across datasets, underscoring the need for further investigation into the factors that determine when these techniques will be most useful. Potential avenues for future research could include exploring alternative ways of constructing informative priors, as well as investigating the interaction between the source and target tasks and how it affects the transfer learning process.
Overall, this paper provides a valuable contribution to the understanding of transfer learning and the use of informative priors, while also highlighting the need for continued research in this area to fully unlock the potential of these techniques.
Conclusion
This paper presents a comprehensive investigation into the use of transfer learning with informative priors to improve the performance of machine learning classifiers on target tasks with limited labeled data. The authors conduct a careful comparison of standard transfer learning and methods that leverage source task information to learn a prior distribution over neural network weights, finding that the benefits of the latter approach can vary significantly depending on the dataset.
The key takeaways from this research are:
- Standard transfer learning can be more effective than previously reported, especially in the regime of 5-300 examples per class in the target task.
- The relative gains of using informed priors over standard transfer learning range from negligible or negative to substantial, depending on the dataset.
- A simple isotropic Gaussian prior can perform competitively with more complex learned low-rank priors, making it a practical and easier-to-understand option.
- The proposed mechanistic justification for informed priors (improved alignment between train and test loss landscapes) is not consistently supported, suggesting the need for further investigation into the underlying reasons for their effectiveness.
This research provides valuable insights for practitioners and researchers working on transfer learning, highlighting the importance of carefully evaluating these techniques on a case-by-case basis and the potential for continued advancements in this area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Transfer Learning with Informative Priors: Simple Baselines Better than Previously Reported
Ethan Harvey, Mikhail Petrov, Michael C. Hughes
We pursue transfer learning to improve classifier accuracy on a target task with few labeled examples available for training. Recent work suggests that using a source task to learn a prior distribution over neural net weights, not just an initialization, can boost target task performance. In this study, we carefully compare transfer learning with and without source task informed priors across 5 datasets. We find that standard transfer learning informed by an initialization only performs far better than reported in previous comparisons. The relative gains of methods using informative priors over standard transfer learning vary in magnitude across datasets. For the scenario of 5-300 examples per class, we find negative or negligible gains on 2 datasets, modest gains (between 1.5-3 points of accuracy) on 2 other datasets, and substantial gains (>8 points) on one dataset. Among methods using informative priors, we find that an isotropic covariance appears competitive with learned low-rank covariance matrix while being substantially simpler to understand and tune. Further analysis suggests that the mechanistic justification for informed priors -- hypothesized improved alignment between train and test loss landscapes -- is not consistently supported due to high variability in empirical landscapes. We release code to allow independent reproduction of all experiments.
Read more5/27/2024
0
Data-driven Prior Learning for Bayesian Optimisation
Sigrid Passano Hellan, Christopher G. Lucas, Nigel H. Goddard
Transfer learning for Bayesian optimisation has generally assumed a strong similarity between optimisation tasks, with at least a subset having similar optimal inputs. This assumption can reduce computational costs, but it is violated in a wide range of optimisation problems where transfer learning may nonetheless be useful. We replace this assumption with a weaker one only requiring the shape of the optimisation landscape to be similar, and analyse the recent method Prior Learning for Bayesian Optimisation - PLeBO - in this setting. By learning priors for the hyperparameters of the Gaussian process surrogate model we can better approximate the underlying function, especially for few function evaluations. We validate the learned priors and compare to a breadth of transfer learning approaches, using synthetic data and a recent air pollution optimisation problem as benchmarks. We show that PLeBO and prior transfer find good inputs in fewer evaluations.
Read more4/22/2024

0
Understanding the Role of Invariance in Transfer Learning
Till Speicher, Vedant Nanda, Krishna P. Gummadi
Transfer learning is a powerful technique for knowledge-sharing between different tasks. Recent work has found that the representations of models with certain invariances, such as to adversarial input perturbations, achieve higher performance on downstream tasks. These findings suggest that invariance may be an important property in the context of transfer learning. However, the relationship of invariance with transfer performance is not fully understood yet and a number of questions remain. For instance, how important is invariance compared to other factors of the pretraining task? How transferable is learned invariance? In this work, we systematically investigate the importance of representational invariance for transfer learning, as well as how it interacts with other parameters during pretraining. To do so, we introduce a family of synthetic datasets that allow us to precisely control factors of variation both in training and test data. Using these datasets, we a) show that for learning representations with high transfer performance, invariance to the right transformations is as, or often more, important than most other factors such as the number of training samples, the model architecture and the identity of the pretraining classes, b) show conditions under which invariance can harm the ability to transfer representations and c) explore how transferable invariance is between tasks. The code is available at url{https://github.com/tillspeicher/representation-invariance-transfer}.
Read more7/8/2024
🔄
0
The Common Intuition to Transfer Learning Can Win or Lose: Case Studies for Linear Regression
Yehuda Dar, Daniel LeJeune, Richard G. Baraniuk
We study a fundamental transfer learning process from source to target linear regression tasks, including overparameterized settings where there are more learned parameters than data samples. The target task learning is addressed by using its training data together with the parameters previously computed for the source task. We define a transfer learning approach to the target task as a linear regression optimization with a regularization on the distance between the to-be-learned target parameters and the already-learned source parameters. We analytically characterize the generalization performance of our transfer learning approach and demonstrate its ability to resolve the peak in generalization errors in double descent phenomena of the minimum L2-norm solution to linear regression. Moreover, we show that for sufficiently related tasks, the optimally tuned transfer learning approach can outperform the optimally tuned ridge regression method, even when the true parameter vector conforms to an isotropic Gaussian prior distribution. Namely, we demonstrate that transfer learning can beat the minimum mean square error (MMSE) solution of the independent target task. Our results emphasize the ability of transfer learning to extend the solution space to the target task and, by that, to have an improved MMSE solution. We formulate the linear MMSE solution to our transfer learning setting and point out its key differences from the common design philosophy to transfer learning.
Read more6/3/2024