Transfer Learning with Self-Supervised Vision Transformers for Snake Identification

0

Sign in to get full access
Overview
- This paper presents a transfer learning approach using self-supervised Vision Transformers (ViT) for snake identification.
- The researchers leverage the powerful visual representations learned by self-supervised ViT models to fine-tune them for the task of classifying snake species.
- The proposed method achieves state-of-the-art performance on a snake identification dataset, demonstrating the effectiveness of transfer learning with self-supervised ViT.
Plain English Explanation
The paper introduces a new way to identify different species of snakes using computer vision. The key idea is to take a type of artificial intelligence model called a Vision Transformer, which has been trained on a large, general dataset of images, and then fine-tune it specifically for the task of recognizing different snake species.
Vision Transformers are a type of deep learning model that can learn to extract and understand visual features from images, similar to how the human visual system works. By starting with a Vision Transformer that has already been trained on a broad set of images, the researchers can "transfer" that general visual understanding to the more specific problem of identifying snakes.
This transfer learning approach is powerful because it allows the model to leverage the rich visual representations it has already learned, rather than having to learn everything from scratch. The researchers show that this method outperforms other state-of-the-art techniques for classifying different snake species, indicating that self-supervised Vision Transformers are a promising tool for computer vision tasks like this.
Technical Explanation
The researchers propose a transfer learning approach using self-supervised Vision Transformers (ViT) for the task of snake identification. They start with a ViT model that has been pre-trained on a large, general image dataset using self-supervised learning, which allows the model to learn powerful visual representations without the need for human-labeled data.
They then fine-tune this pre-trained ViT model on a dataset of snake images, freezing the lower layers of the ViT and only updating the higher layers. This transfer learning strategy enables the model to adapt the general visual understanding learned from the pre-training to the more specific task of classifying different snake species.
The researchers evaluate their approach on a snake identification dataset, comparing it to other state-of-the-art methods. Their results show that the fine-tuned self-supervised ViT outperforms these baselines, demonstrating the effectiveness of leveraging self-supervised representations for transfer learning in computer vision tasks.
Critical Analysis
The paper presents a well-designed study that makes a compelling case for the use of self-supervised Vision Transformers in the context of snake identification. However, the authors acknowledge several limitations and areas for future work:
-
The dataset used is relatively small, which may limit the generalizability of the findings. Evaluating the approach on larger and more diverse snake datasets would help validate the robustness of the method.
-
The transfer learning strategy employed here, where only the higher layers of the ViT are fine-tuned, may not be optimal for all tasks or datasets. Exploring alternative fine-tuning approaches, such as leveraging intermediate encoder representations, could lead to further performance improvements.
-
While the proposed method outperforms other state-of-the-art techniques, there is still room for improvement in the overall classification accuracy. Investigating ways to further boost the performance, such as ensemble methods or more sophisticated data augmentation techniques, could be valuable.
-
The paper does not provide much insight into the types of visual features or patterns the fine-tuned ViT model is learning to distinguish different snake species. Conducting additional analyses to interpret the model's decision-making process could lead to a better understanding of the underlying biological characteristics that are most informative for snake identification.
Overall, this paper presents a promising approach for leveraging self-supervised Vision Transformers in the context of snake identification, but further research is needed to fully realize the potential of this transfer learning technique.
Conclusion
This paper demonstrates the effectiveness of using self-supervised Vision Transformers for transfer learning in the domain of snake identification. By fine-tuning a pre-trained ViT model on a snake image dataset, the researchers were able to achieve state-of-the-art performance, outperforming other contemporary methods.
The key insight is that the rich visual representations learned by self-supervised ViT models can be successfully transferred to more specific computer vision tasks, such as classifying different snake species. This transfer learning strategy allows the model to leverage its general understanding of visual features, rather than having to learn everything from scratch.
The findings of this paper have important implications for the broader field of computer vision and the application of self-supervised learning techniques. As the availability of large, unlabeled image datasets continues to grow, self-supervised Vision Transformers could become an increasingly valuable tool for a wide range of visual recognition and classification tasks, potentially transforming how we approach various real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Transfer Learning with Self-Supervised Vision Transformers for Snake Identification
Anthony Miyaguchi, Murilo Gustineli, Austin Fischer, Ryan Lundqvist
We present our approach for the SnakeCLEF 2024 competition to predict snake species from images. We explore and use Meta's DINOv2 vision transformer model for feature extraction to tackle species' high variability and visual similarity in a dataset of 182,261 images. We perform exploratory analysis on embeddings to understand their structure, and train a linear classifier on the embeddings to predict species. Despite achieving a score of 39.69, our results show promise for DINOv2 embeddings in snake identification. All code for this project is available at https://github.com/dsgt-kaggle-clef/snakeclef-2024.
Read more7/9/2024

0
Multi-Label Plant Species Classification with Self-Supervised Vision Transformers
Murilo Gustineli, Anthony Miyaguchi, Ian Stalter
We present a transfer learning approach using a self-supervised Vision Transformer (DINOv2) for the PlantCLEF 2024 competition, focusing on the multi-label plant species classification. Our method leverages both base and fine-tuned DINOv2 models to extract generalized feature embeddings. We train classifiers to predict multiple plant species within a single image using these rich embeddings. To address the computational challenges of the large-scale dataset, we employ Spark for distributed data processing, ensuring efficient memory management and processing across a cluster of workers. Our data processing pipeline transforms images into grids of tiles, classifying each tile, and aggregating these predictions into a consolidated set of probabilities. Our results demonstrate the efficacy of combining transfer learning with advanced data processing techniques for multi-label image classification tasks. Our code is available at https://github.com/dsgt-kaggle-clef/plantclef-2024.
Read more7/10/2024
0
Liveness Detection in Computer Vision: Transformer-based Self-Supervised Learning for Face Anti-Spoofing
Arman Keresh, Pakizar Shamoi
Face recognition systems are increasingly used in biometric security for convenience and effectiveness. However, they remain vulnerable to spoofing attacks, where attackers use photos, videos, or masks to impersonate legitimate users. This research addresses these vulnerabilities by exploring the Vision Transformer (ViT) architecture, fine-tuned with the DINO framework. The DINO framework facilitates self-supervised learning, enabling the model to learn distinguishing features from unlabeled data. We compared the performance of the proposed fine-tuned ViT model using the DINO framework against a traditional CNN model, EfficientNet b2, on the face anti-spoofing task. Numerous tests on standard datasets show that the ViT model performs better than the CNN model in terms of accuracy and resistance to different spoofing methods. Additionally, we collected our own dataset from a biometric application to validate our findings further. This study highlights the superior performance of transformer-based architecture in identifying complex spoofing cues, leading to significant advancements in biometric security.
Read more6/21/2024
0
Exploring Self-Supervised Vision Transformers for Deepfake Detection: A Comparative Analysis
Huy H. Nguyen, Junichi Yamagishi, Isao Echizen
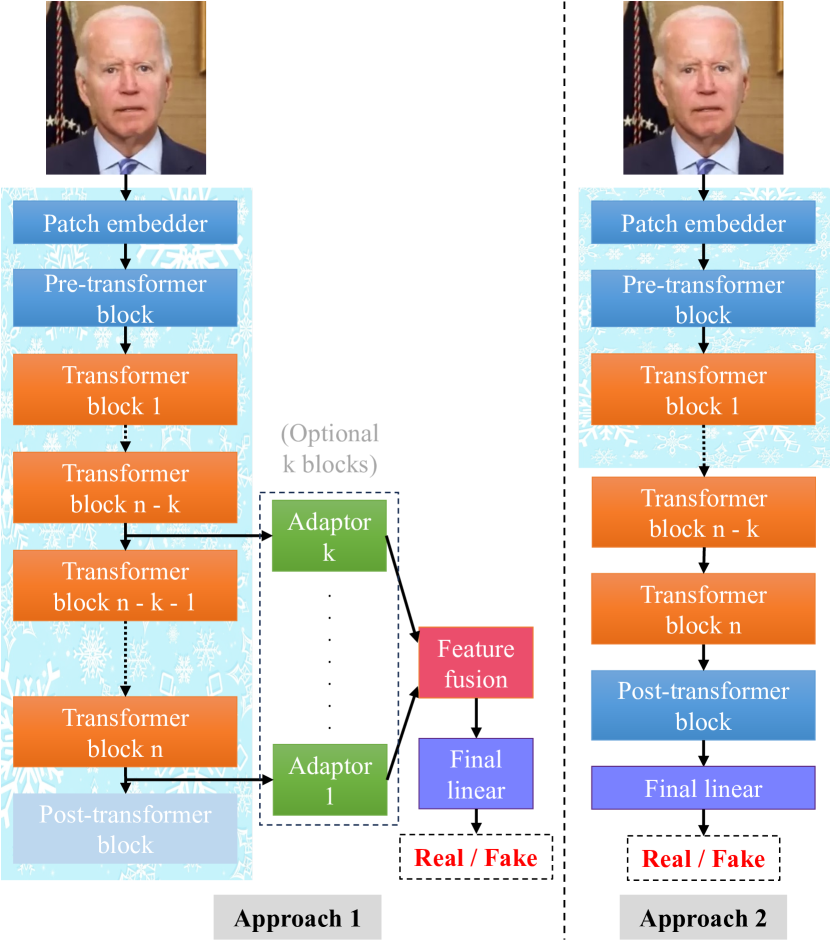
This paper investigates the effectiveness of self-supervised pre-trained vision transformers (ViTs) compared to supervised pre-trained ViTs and conventional neural networks (ConvNets) for detecting facial deepfake images and videos. It examines their potential for improved generalization and explainability, especially with limited training data. Despite the success of transformer architectures in various tasks, the deepfake detection community is hesitant to use large ViTs as feature extractors due to their perceived need for extensive data and suboptimal generalization with small datasets. This contrasts with ConvNets, which are already established as robust feature extractors. Additionally, training ViTs from scratch requires significant resources, limiting their use to large companies. Recent advancements in self-supervised learning (SSL) for ViTs, like masked autoencoders and DINOs, show adaptability across diverse tasks and semantic segmentation capabilities. By leveraging SSL ViTs for deepfake detection with modest data and partial fine-tuning, we find comparable adaptability to deepfake detection and explainability via the attention mechanism. Moreover, partial fine-tuning of ViTs is a resource-efficient option.
Read more8/12/2024