TRAQ: Trustworthy Retrieval Augmented Question Answering via Conformal Prediction
2307.04642
0
0

Abstract
When applied to open-domain question answering, large language models (LLMs) frequently generate incorrect responses based on made-up facts, which are called $textit{hallucinations}$. Retrieval augmented generation (RAG) is a promising strategy to avoid hallucinations, but it does not provide guarantees on its correctness. To address this challenge, we propose the Trustworthy Retrieval Augmented Question Answering, or $textit{TRAQ}$, which provides the first end-to-end statistical correctness guarantee for RAG. TRAQ uses conformal prediction, a statistical technique for constructing prediction sets that are guaranteed to contain the semantically correct response with high probability. Additionally, TRAQ leverages Bayesian optimization to minimize the size of the constructed sets. In an extensive experimental evaluation, we demonstrate that TRAQ provides the desired correctness guarantee while reducing prediction set size by 16.2% on average compared to an ablation. The implementation is available at $href{https://github.com/shuoli90/TRAQ.git}{TRAQ}$.
Create account to get full access
Overview
- This paper presents TRAC, a trustworthy retrieval-augmented chatbot that aims to provide reliable and informative responses to user queries.
- TRAC combines large language models with a retrieval system to leverage both the generative capabilities of language models and the factual knowledge from retrieved information.
- The key innovations of TRAC include a retrieval-augmented architecture, a trustworthiness evaluation framework, and a novel training approach to improve the model's reliability.
Plain English Explanation
TRAC is a new type of chatbot that tries to give users accurate and trustworthy information. It does this by combining two important capabilities: the ability to generate fluent and coherent responses like a large language model, and the ability to retrieve and integrate relevant factual information, like a retrieval-augmented QA system.
The researchers behind TRAC recognized that while language models can produce human-like responses, they don't always reflect the ground truth. So TRAC was designed to be more reliable by improving the model's reasoning and self-reflection capabilities. It learns to not only generate responses, but also assess their trustworthiness before providing them to the user.
This case-based reasoning and retrieval-augmented approach allows TRAC to draw on a broad knowledge base to answer questions, while also being able to acknowledge the limits of its own knowledge and uncertainty. The researchers hope this will make TRAC a more trustworthy and robust open-domain QA system compared to traditional chatbots.
Technical Explanation
TRAC uses a retrieval-augmented architecture, where a large language model is combined with an information retrieval system. The language model is responsible for generating fluent responses, while the retrieval system provides relevant factual information to supplement the model's outputs.
The key innovations of TRAC include:
-
Trustworthiness Evaluation Framework: TRAC learns to assess the trustworthiness of its own responses by predicting a trustworthiness score. This allows the model to be more transparent about the reliability of the information it provides.
-
Retrieval-Augmented Training: TRAC is trained using a novel approach that integrates the retrieval system during training. This helps the model learn to effectively leverage the retrieved information to improve the quality and trustworthiness of its responses.
-
Trustworthy Response Generation: TRAC generates responses by first retrieving relevant information, then using the language model to produce a final response that is coherent and informed by the retrieved facts.
The researchers evaluated TRAC on a range of open-domain question answering and dialogue tasks, and found that it outperformed traditional chatbots in terms of response quality, factual accuracy, and trustworthiness.
Critical Analysis
The paper provides a thorough evaluation of TRAC's performance, demonstrating its advantages over existing chatbot systems. However, the authors acknowledge several limitations and areas for further research:
-
Scope of Evaluation: The experiments focused on open-domain question answering and dialogue tasks, but the authors note that TRAC's performance may vary for other types of tasks or specialized domains.
-
Reliance on Retrieval Quality: TRAC's performance is heavily dependent on the quality and relevance of the information retrieved by the underlying system. Improving the retrieval component could further enhance TRAC's capabilities.
-
Ethical Considerations: While the paper discusses TRAC's trustworthiness, there are broader ethical concerns around the development and deployment of AI-powered chatbots, such as issues of transparency, accountability, and potential misuse.
-
Scalability and Efficiency: As TRAC integrates both a language model and a retrieval system, there may be challenges in scaling the system to handle large volumes of user requests or deploying it in real-time applications.
Further research could explore ways to address these limitations, such as developing more robust and domain-agnostic retrieval systems, investigating the ethical implications of TRAC-like chatbots, and optimizing the system for increased efficiency and scalability.
Conclusion
The TRAC paper presents a novel approach to building trustworthy and informative chatbots by combining large language models with a retrieval-augmented architecture. The key innovations, including the trustworthiness evaluation framework and the retrieval-augmented training, enable TRAC to provide more reliable and transparent responses compared to traditional chatbots.
While the paper demonstrates the potential of this approach, it also highlights areas for further research and development to address the identified limitations. As AI-powered chatbots become more prevalent, the lessons learned from TRAC could contribute to the design of more trustworthy and socially responsible conversational AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RAGTruth: A Hallucination Corpus for Developing Trustworthy Retrieval-Augmented Language Models
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, Juntong Song, Tong Zhang
0
0
Retrieval-augmented generation (RAG) has become a main technique for alleviating hallucinations in large language models (LLMs). Despite the integration of RAG, LLMs may still present unsupported or contradictory claims to the retrieved contents. In order to develop effective hallucination prevention strategies under RAG, it is important to create benchmark datasets that can measure the extent of hallucination. This paper presents RAGTruth, a corpus tailored for analyzing word-level hallucinations in various domains and tasks within the standard RAG frameworks for LLM applications. RAGTruth comprises nearly 18,000 naturally generated responses from diverse LLMs using RAG. These responses have undergone meticulous manual annotations at both the individual cases and word levels, incorporating evaluations of hallucination intensity. We not only benchmark hallucination frequencies across different LLMs, but also critically assess the effectiveness of several existing hallucination detection methodologies. Furthermore, we show that using a high-quality dataset such as RAGTruth, it is possible to finetune a relatively small LLM and achieve a competitive level of performance in hallucination detection when compared to the existing prompt-based approaches using state-of-the-art large language models such as GPT-4.
5/20/2024
CONFLARE: CONFormal LArge language model REtrieval
Pouria Rouzrokh, Shahriar Faghani, Cooper U. Gamble, Moein Shariatnia, Bradley J. Erickson
0
0
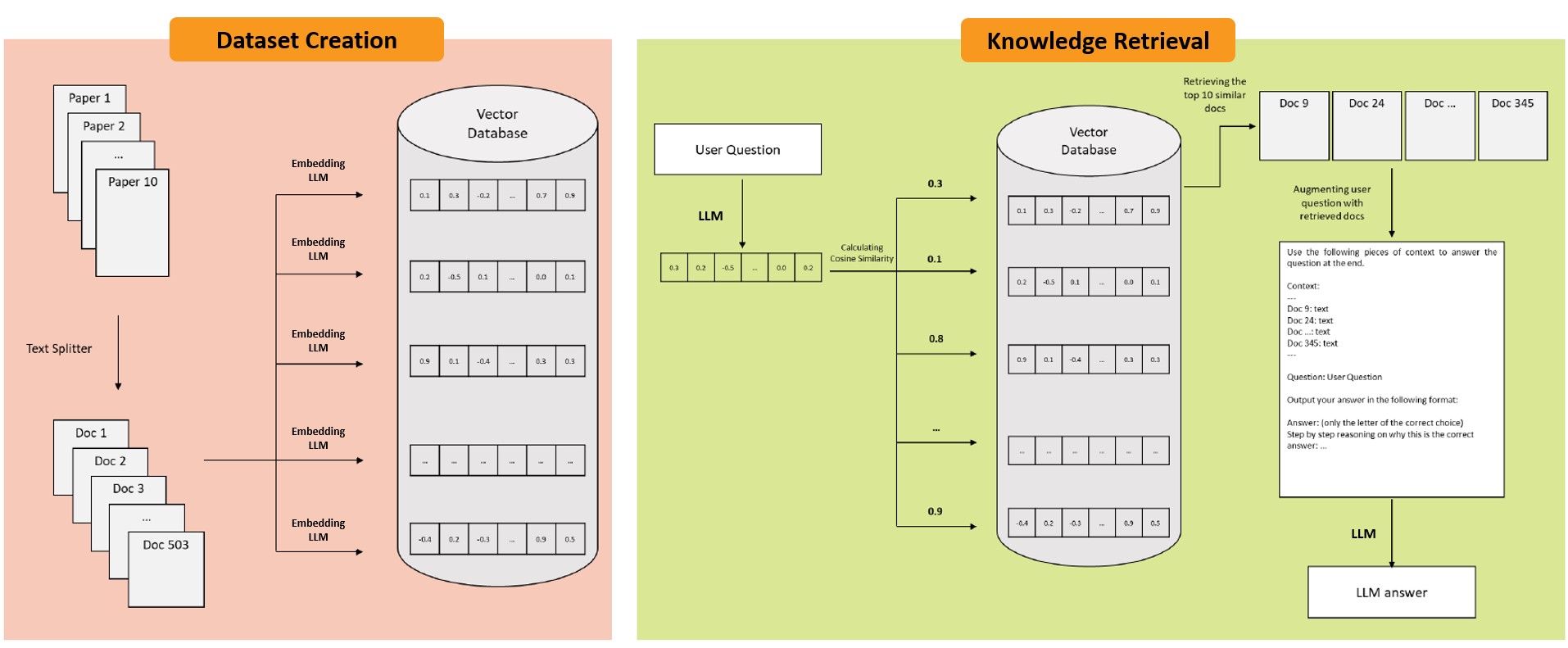
Retrieval-augmented generation (RAG) frameworks enable large language models (LLMs) to retrieve relevant information from a knowledge base and incorporate it into the context for generating responses. This mitigates hallucinations and allows for the updating of knowledge without retraining the LLM. However, RAG does not guarantee valid responses if retrieval fails to identify the necessary information as the context for response generation. Also, if there is contradictory content, the RAG response will likely reflect only one of the two possible responses. Therefore, quantifying uncertainty in the retrieval process is crucial for ensuring RAG trustworthiness. In this report, we introduce a four-step framework for applying conformal prediction to quantify retrieval uncertainty in RAG frameworks. First, a calibration set of questions answerable from the knowledge base is constructed. Each question's embedding is compared against document embeddings to identify the most relevant document chunks containing the answer and record their similarity scores. Given a user-specified error rate ({alpha}), these similarity scores are then analyzed to determine a similarity score cutoff threshold. During inference, all chunks with similarity exceeding this threshold are retrieved to provide context to the LLM, ensuring the true answer is captured in the context with a (1-{alpha}) confidence level. We provide a Python package that enables users to implement the entire workflow proposed in our work, only using LLMs and without human intervention.
4/9/2024
FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering
Tianchi Cai, Zhiwen Tan, Xierui Song, Tao Sun, Jiyan Jiang, Yunqi Xu, Yinger Zhang, Jinjie Gu
0
0
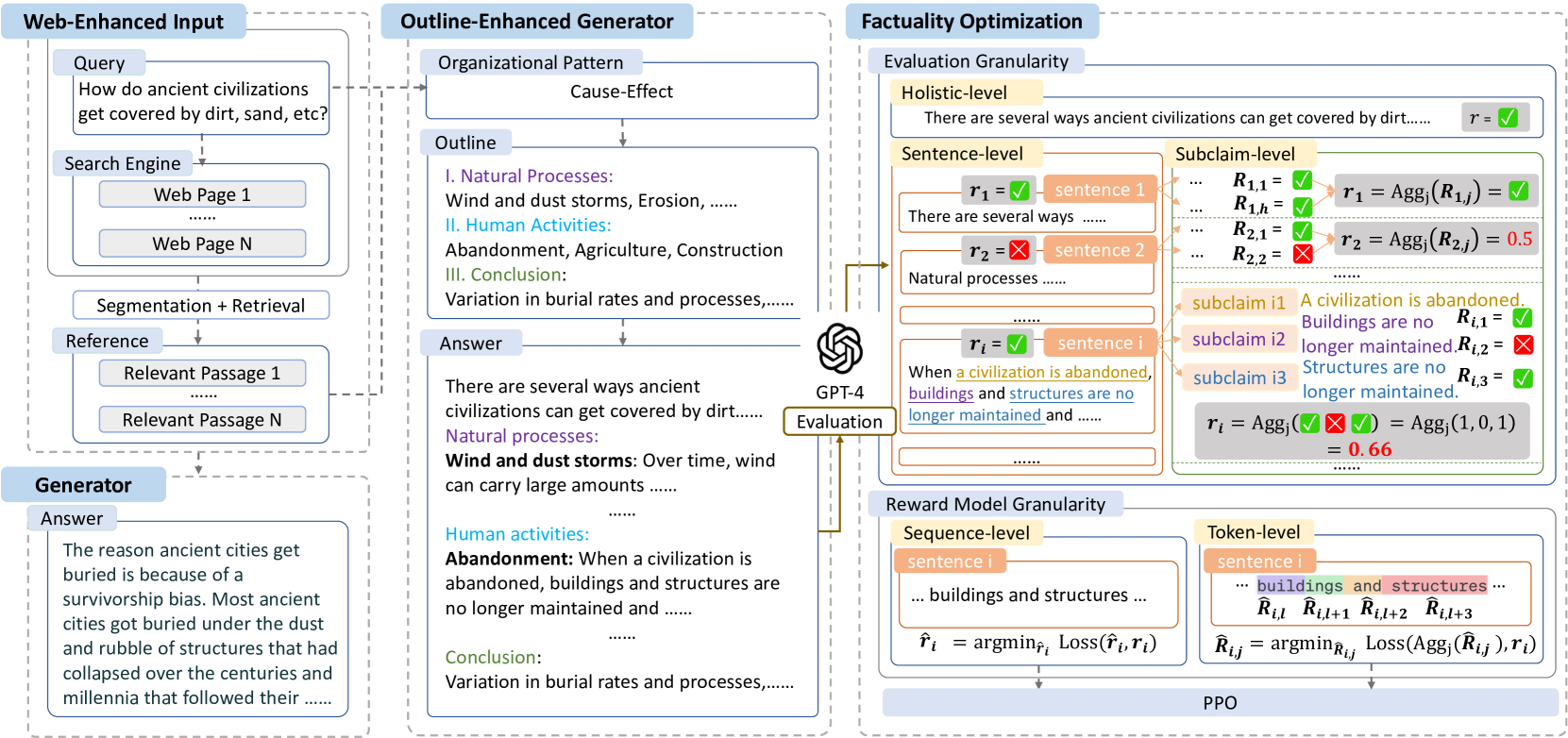
Retrieval Augmented Generation (RAG) has become prevalent in question-answering (QA) tasks due to its ability of utilizing search engine to enhance the quality of long-form question-answering (LFQA). Despite the emergence of various open source methods and web-enhanced commercial systems such as Bing Chat, two critical problems remain unsolved, i.e., the lack of factuality and clear logic in the generated long-form answers. In this paper, we remedy these issues via a systematic study on answer generation in web-enhanced LFQA. Specifically, we first propose a novel outline-enhanced generator to achieve clear logic in the generation of multifaceted answers and construct two datasets accordingly. Then we propose a factuality optimization method based on a carefully designed doubly fine-grained RLHF framework, which contains automatic evaluation and reward modeling in different levels of granularity. Our generic framework comprises conventional fine-grained RLHF methods as special cases. Extensive experiments verify the superiority of our proposed textit{Factuality-optimized RAG (FoRAG)} method on both English and Chinese benchmarks. In particular, when applying our method to Llama2-7B-chat, the derived model FoRAG-L-7B outperforms WebGPT-175B in terms of three commonly used metrics (i.e., coherence, helpfulness, and factuality), while the number of parameters is much smaller (only 1/24 of that of WebGPT-175B). Our datasets and models are made publicly available for better reproducibility: https://huggingface.co/forag.
6/21/2024
RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering
Zihan Zhang, Meng Fang, Ling Chen
0
0
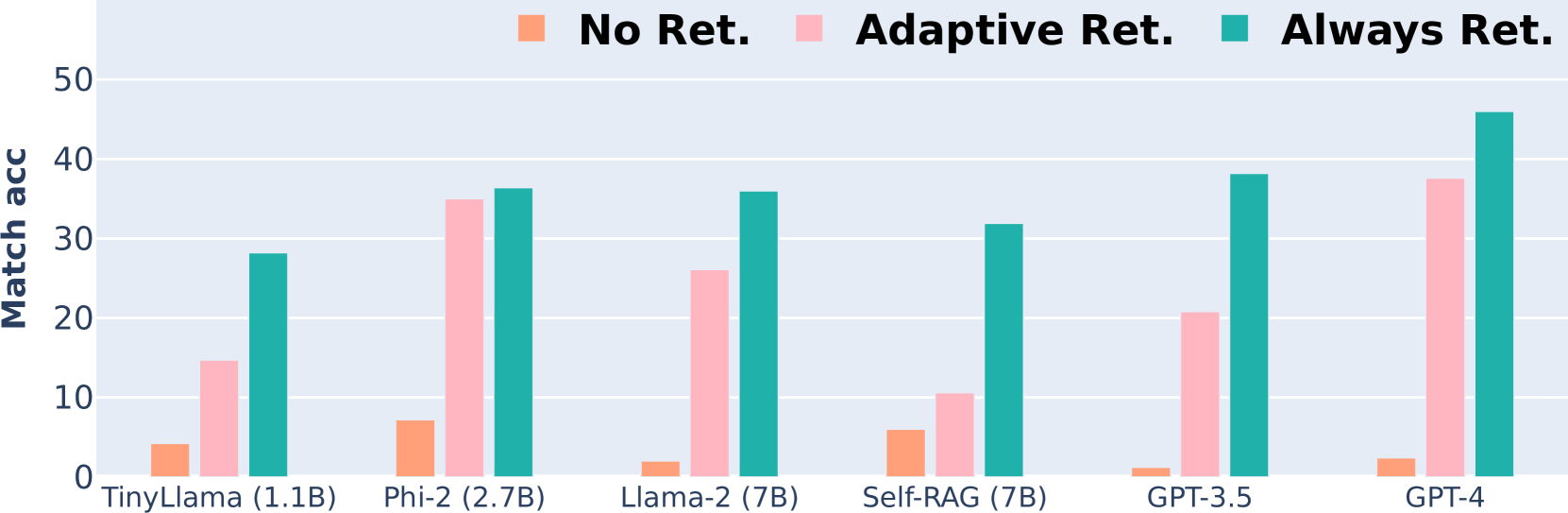
Adaptive retrieval-augmented generation (ARAG) aims to dynamically determine the necessity of retrieval for queries instead of retrieving indiscriminately to enhance the efficiency and relevance of the sourced information. However, previous works largely overlook the evaluation of ARAG approaches, leading to their effectiveness being understudied. This work presents a benchmark, RetrievalQA, comprising 1,271 short-form questions covering new world and long-tail knowledge. The knowledge necessary to answer the questions is absent from LLMs; therefore, external information must be retrieved to answer correctly. This makes RetrievalQA a suitable testbed to evaluate existing ARAG methods. We observe that calibration-based methods heavily rely on threshold tuning, while vanilla prompting is inadequate for guiding LLMs to make reliable retrieval decisions. Based on our findings, we propose Time-Aware Adaptive Retrieval (TA-ARE), a simple yet effective method that helps LLMs assess the necessity of retrieval without calibration or additional training. The dataset and code will be available at https://github.com/hyintell/RetrievalQA
6/6/2024