RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering

0
Sign in to get full access
Overview
• This research paper explores the use of retrieval-augmented generation for short-form open-domain question answering.
• The authors construct a dataset, called RetrievalQA, to assess the performance of these models.
• The paper evaluates how well retrieval-augmented generation models can adaptively leverage relevant information to answer questions, compared to other approaches.
Plain English Explanation
The paper focuses on a type of artificial intelligence (AI) system called "retrieval-augmented generation." These systems use a combination of information retrieval and language generation to answer questions. Instead of just generating an answer from scratch, they first search for relevant information, then use that information to generate a more accurate and tailored response.
The researchers created a new dataset, called RetrievalQA, to test how well these retrieval-augmented generation models perform on short-form, open-domain questions. Open-domain means the questions can cover a wide range of topics, rather than being limited to a specific domain.
The key idea is that by adaptively retrieving relevant information, these models should be able to provide higher-quality answers compared to approaches that don't use retrieval. The paper evaluates different models to see how effective this approach is in practice.
Technical Explanation
The researchers constructed the RetrievalQA dataset by collecting short-form, open-domain questions and sourcing relevant passages from Wikipedia to serve as the information that the models can retrieve and use to generate answers.
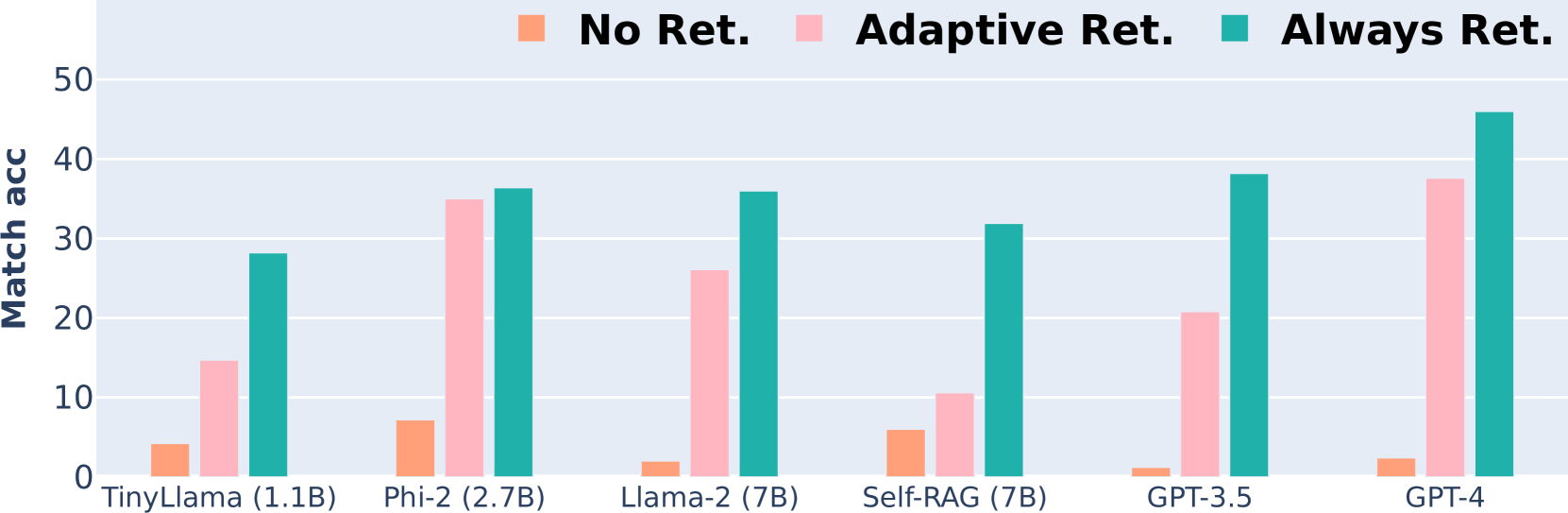
They then evaluated several retrieval-augmented generation models on this dataset, including those based on the DueT-RAG and Retro architectures. These models adaptively retrieve relevant information and incorporate it into the answer generation process.
The results show that the retrieval-augmented generation models outperform other approaches, such as standard language models that don't use retrieval, on various metrics like answer quality and faithfulness to the source information. This suggests that the adaptive retrieval process helps these models provide more accurate and informative answers for short-form, open-domain questions.
Critical Analysis
The paper provides a thorough evaluation of retrieval-augmented generation models on the RetrievalQA dataset, but there are a few potential limitations and areas for further research:
- The dataset is focused on short-form questions, so it's unclear how well these models would perform on longer, more complex queries.
- The evaluation is limited to a single domain (Wikipedia), and it would be valuable to assess performance on a more diverse set of information sources.
- The paper does not delve into the specific strengths and weaknesses of the different retrieval-augmented generation architectures, which could provide additional insights.
Nevertheless, the research demonstrates the potential benefits of adaptive information retrieval for improving the quality of short-form, open-domain question answering, which could have important applications in areas like conversational AI and domain-specific question answering.
Conclusion
This paper presents a novel dataset and comprehensive evaluation of retrieval-augmented generation models for short-form, open-domain question answering. The results suggest that adaptively retrieving relevant information can significantly improve the quality and faithfulness of generated answers, compared to models that don't leverage retrieval.
While further research is needed to assess the generalizability of these findings, this work highlights the importance of seamlessly integrating information retrieval and language generation for building more capable and trustworthy question-answering systems. The insights from this paper could inform the development of automated evaluation frameworks and inspire future advances in retrieval-augmented generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RetrievalQA: Assessing Adaptive Retrieval-Augmented Generation for Short-form Open-Domain Question Answering
Zihan Zhang, Meng Fang, Ling Chen
Adaptive retrieval-augmented generation (ARAG) aims to dynamically determine the necessity of retrieval for queries instead of retrieving indiscriminately to enhance the efficiency and relevance of the sourced information. However, previous works largely overlook the evaluation of ARAG approaches, leading to their effectiveness being understudied. This work presents a benchmark, RetrievalQA, comprising 1,271 short-form questions covering new world and long-tail knowledge. The knowledge necessary to answer the questions is absent from LLMs; therefore, external information must be retrieved to answer correctly. This makes RetrievalQA a suitable testbed to evaluate existing ARAG methods. We observe that calibration-based methods heavily rely on threshold tuning, while vanilla prompting is inadequate for guiding LLMs to make reliable retrieval decisions. Based on our findings, we propose Time-Aware Adaptive Retrieval (TA-ARE), a simple yet effective method that helps LLMs assess the necessity of retrieval without calibration or additional training. The dataset and code will be available at https://github.com/hyintell/RetrievalQA
Read more6/6/2024
⛏️
0
Evaluation of Retrieval-Augmented Generation: A Survey
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, Zhaofeng Liu
Retrieval-Augmented Generation (RAG) has recently gained traction in natural language processing. Numerous studies and real-world applications are leveraging its ability to enhance generative models through external information retrieval. Evaluating these RAG systems, however, poses unique challenges due to their hybrid structure and reliance on dynamic knowledge sources. To better understand these challenges, we conduct A Unified Evaluation Process of RAG (Auepora) and aim to provide a comprehensive overview of the evaluation and benchmarks of RAG systems. Specifically, we examine and compare several quantifiable metrics of the Retrieval and Generation components, such as relevance, accuracy, and faithfulness, within the current RAG benchmarks, encompassing the possible output and ground truth pairs. We then analyze the various datasets and metrics, discuss the limitations of current benchmarks, and suggest potential directions to advance the field of RAG benchmarks.
Read more7/4/2024

0
A Survey on Retrieval-Augmented Text Generation for Large Language Models
Yizheng Huang, Jimmy Huang
Retrieval-Augmented Generation (RAG) merges retrieval methods with deep learning advancements to address the static limitations of large language models (LLMs) by enabling the dynamic integration of up-to-date external information. This methodology, focusing primarily on the text domain, provides a cost-effective solution to the generation of plausible but possibly incorrect responses by LLMs, thereby enhancing the accuracy and reliability of their outputs through the use of real-world data. As RAG grows in complexity and incorporates multiple concepts that can influence its performance, this paper organizes the RAG paradigm into four categories: pre-retrieval, retrieval, post-retrieval, and generation, offering a detailed perspective from the retrieval viewpoint. It outlines RAG's evolution and discusses the field's progression through the analysis of significant studies. Additionally, the paper introduces evaluation methods for RAG, addressing the challenges faced and proposing future research directions. By offering an organized framework and categorization, the study aims to consolidate existing research on RAG, clarify its technological underpinnings, and highlight its potential to broaden the adaptability and applications of LLMs.
Read more8/26/2024
0
W-RAG: Weakly Supervised Dense Retrieval in RAG for Open-domain Question Answering
Jinming Nian, Zhiyuan Peng, Qifan Wang, Yi Fang
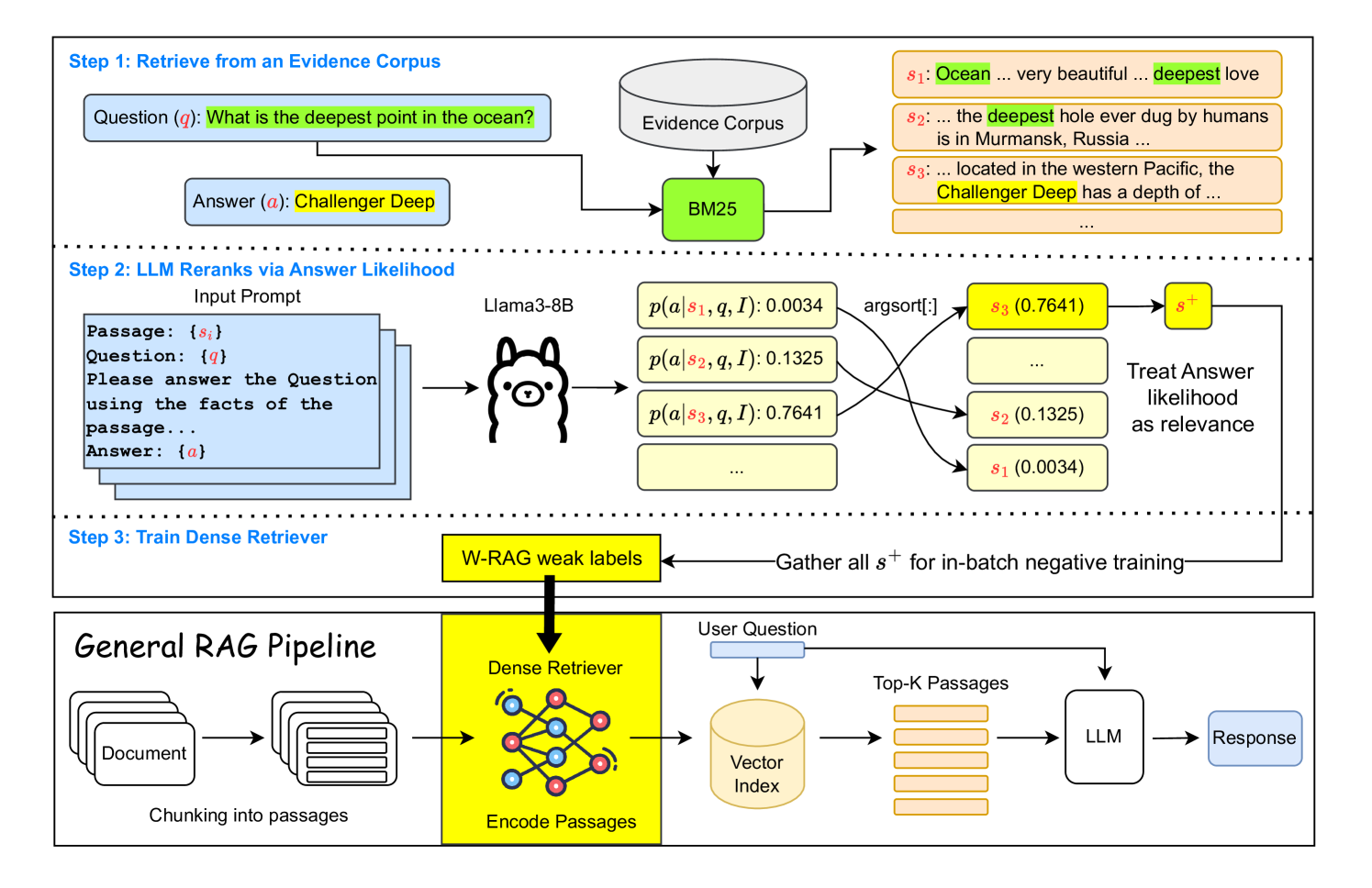
In knowledge-intensive tasks such as open-domain question answering (OpenQA), Large Language Models (LLMs) often struggle to generate factual answers relying solely on their internal (parametric) knowledge. To address this limitation, Retrieval-Augmented Generation (RAG) systems enhance LLMs by retrieving relevant information from external sources, thereby positioning the retriever as a pivotal component. Although dense retrieval demonstrates state-of-the-art performance, its training poses challenges due to the scarcity of ground-truth evidence, largely attributed to the high costs of human annotation. In this paper, we propose W-RAG by utilizing the ranking capabilities of LLMs to create weakly labeled data for training dense retrievers. Specifically, we rerank the top-$K$ passages retrieved via BM25 by assessing the probability that LLMs will generate the correct answer based on the question and each passage. The highest-ranking passages are then used as positive training examples for dense retrieval. Our comprehensive experiments across four publicly available OpenQA datasets demonstrate that our approach enhances both retrieval and OpenQA performance compared to baseline models.
Read more8/19/2024