TraveLER: A Multi-LMM Agent Framework for Video Question-Answering

0
Sign in to get full access
Overview
- Proposes a multi-agent framework called TraveLER for video question-answering
- Combines multiple large language models (LLMs) to answer questions about video content
- Aims to improve upon existing single-agent approaches by leveraging the strengths of different LLMs
Plain English Explanation
TraveLER is a new system designed to help answer questions about videos. It's made up of multiple "agents," each with their own specialized language model. These agents work together to understand the video content and provide accurate and comprehensive answers to questions.
The idea is that by using a team of different language models, TraveLER can draw on their unique strengths and cover a wider range of question types. For example, one agent might excel at understanding visual details, while another is better at reasoning about the narrative or events depicted in the video.
The researchers believe this multi-agent approach can outperform previous single-agent systems that relied on just one language model. By combining the knowledge and capabilities of multiple models, TraveLER can give more thorough and nuanced answers to video-related questions.
Technical Explanation
The TraveLER framework consists of multiple large language model (LLM) agents, each with its own specialized capabilities. These agents work together in a collaborative manner to answer questions about video content.
The key components of TraveLER include:
- Visual-Semantic Embedding Agent: Responsible for extracting and aligning visual and textual features from the video to create a unified representation.
- Narrative Reasoning Agent: Focuses on understanding the narrative structure and storyline of the video.
- Knowledge Grounding Agent: Leverages external knowledge bases to provide contextual information relevant to the video content.
- Answer Generation Agent: Synthesizes the outputs from the other agents to formulate a final answer to the user's question.
The agents communicate through a shared memory system, allowing them to exchange information and refine their responses iteratively. This collaborative approach aims to better capture the nuances and complexities of video understanding compared to a single-agent architecture.
Critical Analysis
The TraveLER framework presents a promising direction for video question-answering, but there are a few potential limitations and areas for further research:
- Scalability: The multi-agent design may introduce additional computational overhead and coordination challenges as the number of agents increases. The researchers should explore ways to optimize the framework's efficiency.
- Robustness: The paper does not discuss how TraveLER would handle noisy or incomplete video data, which is a common real-world scenario. Evaluating the system's performance under such conditions would be valuable.
- Explainability: While the multi-agent approach aims to provide more comprehensive answers, it may also make the system's decision-making process less transparent. Developing mechanisms to explain the reasoning behind TraveLER's outputs could improve user trust and acceptance.
- Generalization: The evaluation in the paper is limited to a specific video question-answering dataset. Assessing TraveLER's performance on a wider range of video-related tasks would help demonstrate its broader applicability.
Overall, the TraveLER framework represents an interesting and potentially impactful contribution to the field of video understanding. Further research and development to address the identified limitations could help unlock the full potential of this multi-agent approach.
Conclusion
The TraveLER framework introduces a novel multi-agent architecture for video question-answering, combining the strengths of multiple large language models to provide more comprehensive and accurate answers. By leveraging specialized agents for different aspects of video understanding, the system aims to outperform traditional single-agent approaches.
While the paper presents promising results, there are opportunities for further research to address scalability, robustness, explainability, and generalization concerns. Continued advancements in this area could lead to more powerful and user-friendly video-based question-answering systems, with applications in education, entertainment, and various other domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TraveLER: A Multi-LMM Agent Framework for Video Question-Answering
Chuyi Shang, Amos You, Sanjay Subramanian, Trevor Darrell, Roei Herzig
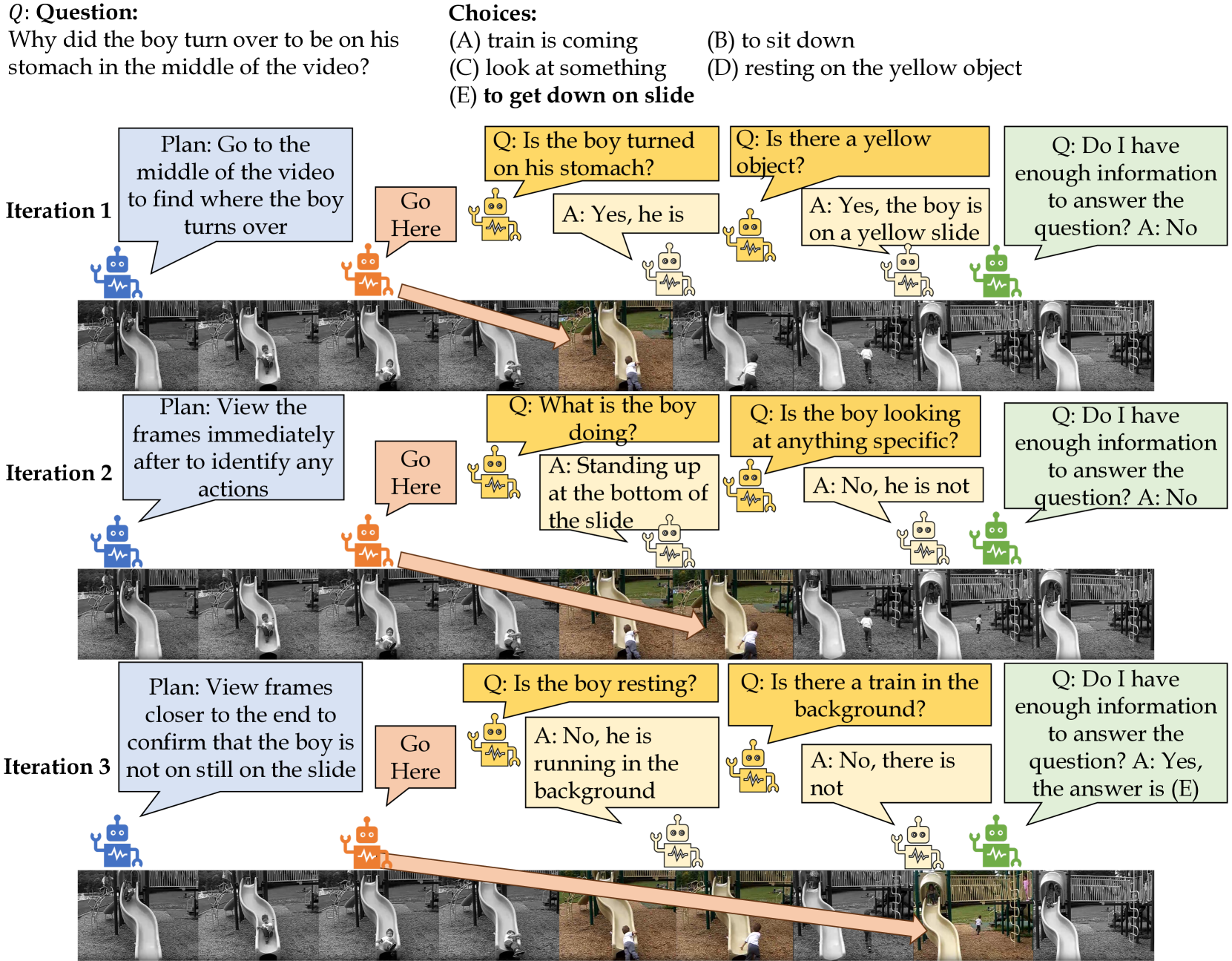
Recently, Large Multimodal Models (LMMs) have made significant progress in video question-answering using a frame-wise approach by leveraging large-scale, image-based pretraining in a zero-shot manner. While image-based methods for videos have shown impressive performance, a current limitation is that they often overlook how key timestamps are selected and cannot adjust when incorrect timestamps are identified. Moreover, they are unable to extract details relevant to the question, instead providing general descriptions of the frame. To overcome this, we design a multi-LMM agent framework that travels along the video, iteratively collecting relevant information from keyframes through interactive question-asking until there is sufficient information to answer the question. Specifically, we propose TraveLER, a model that can create a plan to Traverse through the video, ask questions about individual frames to Locate and store key information, and then Evaluate if there is enough information to answer the question. Finally, if there is not enough information, our method is able to Replan based on its collected knowledge. Through extensive experiments, we find that the proposed TraveLER approach improves performance on several video question-answering benchmarks, such as NExT-QA, STAR, and Perception Test, without the need to fine-tune on specific datasets.
Read more4/3/2024

0
Weakly Supervised Gaussian Contrastive Grounding with Large Multimodal Models for Video Question Answering
Haibo Wang, Chenghang Lai, Yixuan Sun, Weifeng Ge
Video Question Answering (VideoQA) aims to answer natural language questions based on the information observed in videos. Despite the recent success of Large Multimodal Models (LMMs) in image-language understanding and reasoning, they deal with VideoQA insufficiently, by simply taking uniformly sampled frames as visual inputs, which ignores question-relevant visual clues. Moreover, there are no human annotations for question-critical timestamps in existing VideoQA datasets. In light of this, we propose a novel weakly supervised framework to enforce the LMMs to reason out the answers with question-critical moments as visual inputs. Specifically, we first fuse the question and answer pairs as event descriptions to find multiple keyframes as target moments and pseudo-labels, with the visual-language alignment capability of the CLIP models. With these pseudo-labeled keyframes as additionally weak supervision, we devise a lightweight Gaussian-based Contrastive Grounding (GCG) module. GCG learns multiple Gaussian functions to characterize the temporal structure of the video, and sample question-critical frames as positive moments to be the visual inputs of LMMs. Extensive experiments on several benchmarks verify the effectiveness of our framework, and we achieve substantial improvements compared to previous state-of-the-art methods.
Read more7/24/2024
🔮
0
Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models
Zhengxing Lan, Hongbo Li, Lingshan Liu, Bo Fan, Yisheng Lv, Yilong Ren, Zhiyong Cui
Predicting the future trajectories of dynamic traffic actors is a cornerstone task in autonomous driving. Though existing notable efforts have resulted in impressive performance improvements, a gap persists in scene cognitive and understanding of the complex traffic semantics. This paper proposes Traj-LLM, the first to investigate the potential of using Large Language Models (LLMs) without explicit prompt engineering to generate future motion from agents' past/observed trajectories and scene semantics. Traj-LLM starts with sparse context joint coding to dissect the agent and scene features into a form that LLMs understand. On this basis, we innovatively explore LLMs' powerful comprehension abilities to capture a spectrum of high-level scene knowledge and interactive information. Emulating the human-like lane focus cognitive function and enhancing Traj-LLM's scene comprehension, we introduce lane-aware probabilistic learning powered by the pioneering Mamba module. Finally, a multi-modal Laplace decoder is designed to achieve scene-compliant multi-modal predictions. Extensive experiments manifest that Traj-LLM, fortified by LLMs' strong prior knowledge and understanding prowess, together with lane-aware probability learning, outstrips state-of-the-art methods across evaluation metrics. Moreover, the few-shot analysis further substantiates Traj-LLM's performance, wherein with just 50% of the dataset, it outperforms the majority of benchmarks relying on complete data utilization. This study explores equipping the trajectory prediction task with advanced capabilities inherent in LLMs, furnishing a more universal and adaptable solution for forecasting agent motion in a new way.
Read more5/9/2024
0
A Human-Like Reasoning Framework for Multi-Phases Planning Task with Large Language Models
Chengxing Xie, Difan Zou
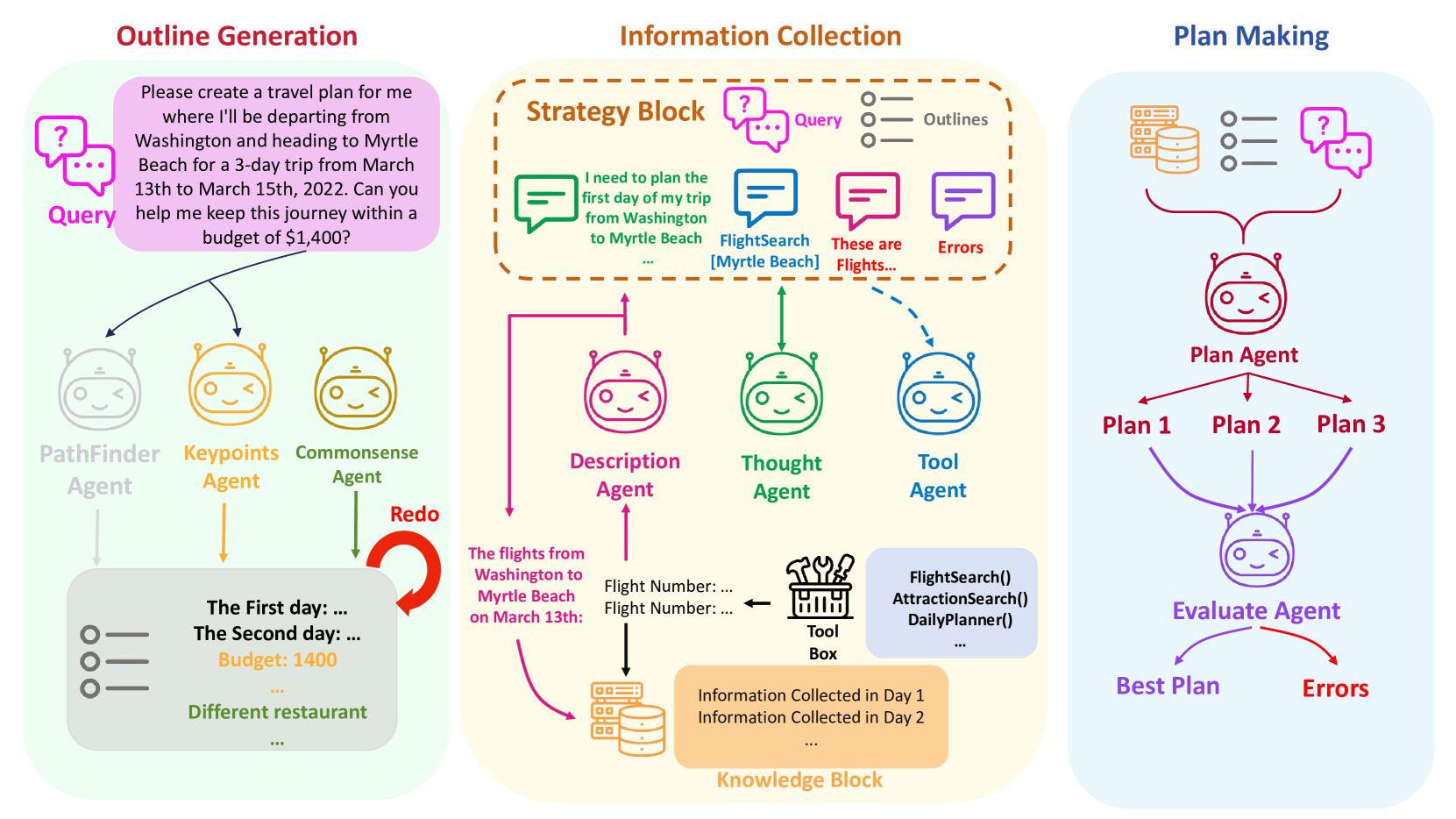
Recent studies have highlighted their proficiency in some simple tasks like writing and coding through various reasoning strategies. However, LLM agents still struggle with tasks that require comprehensive planning, a process that challenges current models and remains a critical research issue. In this study, we concentrate on travel planning, a Multi-Phases planning problem, that involves multiple interconnected stages, such as outlining, information gathering, and planning, often characterized by the need to manage various constraints and uncertainties. Existing reasoning approaches have struggled to effectively address this complex task. Our research aims to address this challenge by developing a human-like planning framework for LLM agents, i.e., guiding the LLM agent to simulate various steps that humans take when solving Multi-Phases problems. Specifically, we implement several strategies to enable LLM agents to generate a coherent outline for each travel query, mirroring human planning patterns. Additionally, we integrate Strategy Block and Knowledge Block into our framework: Strategy Block facilitates information collection, while Knowledge Block provides essential information for detailed planning. Through our extensive experiments, we demonstrate that our framework significantly improves the planning capabilities of LLM agents, enabling them to tackle the travel planning task with improved efficiency and effectiveness. Our experimental results showcase the exceptional performance of the proposed framework; when combined with GPT-4-Turbo, it attains $10times$ the performance gains in comparison to the baseline framework deployed on GPT-4-Turbo.
Read more5/29/2024