Tri$^{2}$-plane: Thinking Head Avatar via Feature Pyramid

0

Sign in to get full access
Overview
- This paper presents Tri²-plane, a novel method for volumetric avatar reconstruction that leverages a feature pyramid to capture details at multiple scales.
- The method uses tri-plane representations, which are an efficient way to represent 3D geometry, along with a feature pyramid to extract details at different levels of granularity.
- The authors demonstrate that Tri²-plane outperforms previous state-of-the-art approaches for volumetric avatar reconstruction on various metrics.
Plain English Explanation
Tri²-plane is a new way to create 3D models of people, called avatars, from photographs or videos. The key idea is to use a technique called "tri-planes" to represent the 3D shape efficiently, and to combine this with a "feature pyramid" that can capture details at different levels of detail.
Tri-planes are a clever way to store 3D information - they split the 3D space into three orthogonal "planes" and store information about the object in each of those planes. This is more efficient than other 3D representations, which can require a lot of memory.
The feature pyramid is a way to extract information at multiple scales - from coarse, high-level details to fine, low-level details. By combining the tri-plane representation with the feature pyramid, the method is able to generate high-quality 3D avatars that capture intricate details like facial features, while still being computationally efficient.
The authors show that their Tri²-plane method outperforms previous state-of-the-art approaches for creating 3D avatars from images or videos. This could have applications in virtual reality, animation, video conferencing, and digital avatars.
Technical Explanation
The key technical contributions of the Tri²-plane method are:
-
Tri-plane Representation: The researchers use a tri-plane representation to efficiently encode the 3D geometry of the avatar. This involves splitting the 3D space into three orthogonal planes and storing the relevant information in each plane.
-
Feature Pyramid: To capture details at multiple scales, the method uses a feature pyramid. This extracts features at different levels of granularity, from coarse, high-level details to fine, low-level details.
-
End-to-End Training: Tri²-plane is trained end-to-end, directly optimizing the tri-plane representation to match the input images or video frames.
The authors evaluate their method on several benchmark datasets for 3D avatar reconstruction, and show that Tri²-plane outperforms previous state-of-the-art approaches in terms of reconstruction quality and efficiency.
Critical Analysis
The paper presents a well-designed and carefully evaluated method for volumetric avatar reconstruction. The use of the tri-plane representation and feature pyramid is a novel and effective approach to capturing 3D details efficiently.
One potential limitation is that the method relies on having multiple input views (e.g. images or video frames) to reconstruct the 3D avatar. In some applications, only a single input view may be available, which could limit the reconstruction quality.
Additionally, the paper does not explore the ability of the method to generalize to a wide range of subjects. The evaluations are mostly focused on a limited set of individuals, and it would be interesting to see how well Tri²-plane performs on more diverse data.
Overall, this is a promising piece of research that advances the state-of-the-art in 3D avatar reconstruction. The technical innovations and strong empirical results make it a valuable contribution to the field.
Conclusion
The Tri²-plane method presented in this paper offers a novel approach to volumetric avatar reconstruction that leverages a tri-plane representation and feature pyramid to capture details at multiple scales. The authors demonstrate state-of-the-art performance on benchmark datasets, showcasing the effectiveness of their technique.
This work has the potential to significantly impact applications such as virtual reality, animation, video conferencing, and digital avatars, where realistic and efficient 3D reconstructions of people are crucial. As the field of 3D computer vision continues to advance, methods like Tri²-plane will play an increasingly important role in enabling more immersive and personalized digital experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Tri$^{2}$-plane: Thinking Head Avatar via Feature Pyramid
Luchuan Song, Pinxin Liu, Lele Chen, Guojun Yin, Chenliang Xu
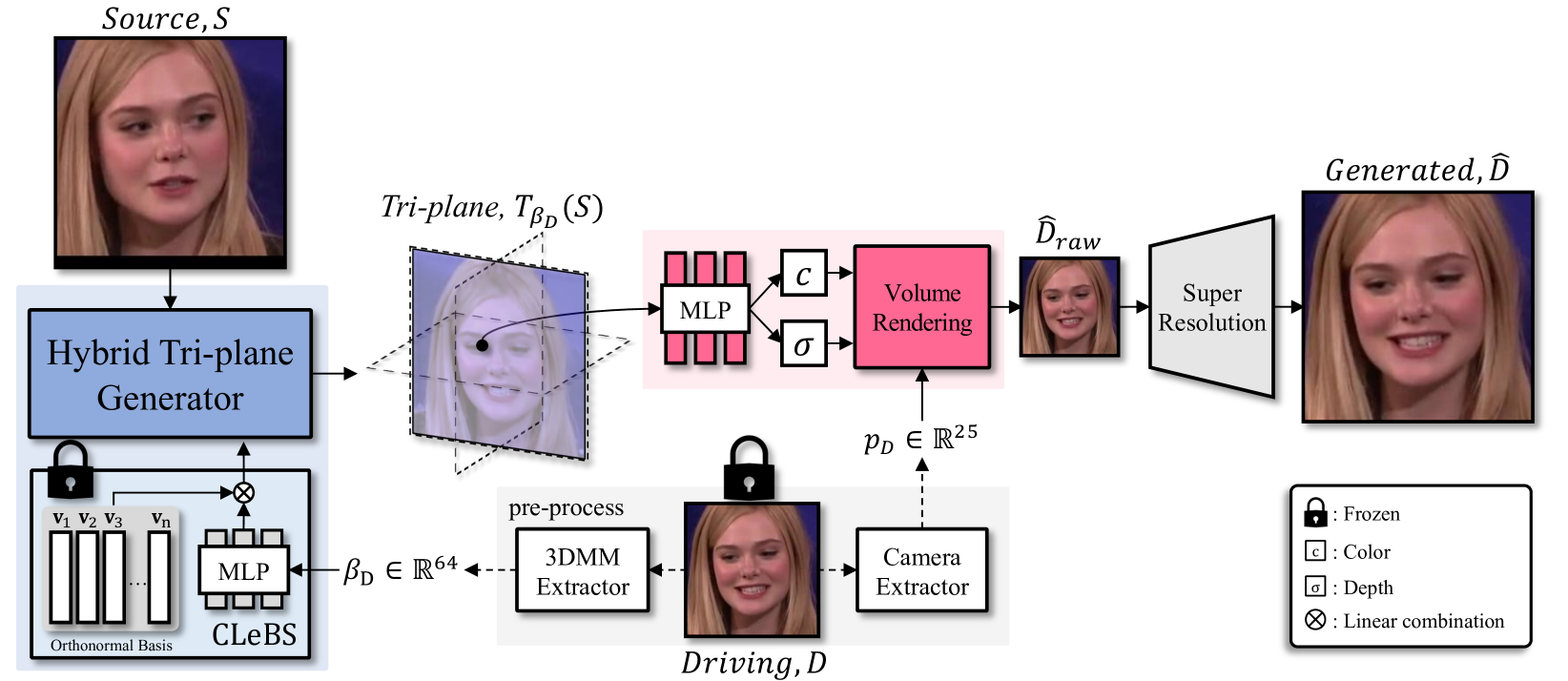
Recent years have witnessed considerable achievements in facial avatar reconstruction with neural volume rendering. Despite notable advancements, the reconstruction of complex and dynamic head movements from monocular videos still suffers from capturing and restoring fine-grained details. In this work, we propose a novel approach, named Tri$^2$-plane, for monocular photo-realistic volumetric head avatar reconstructions. Distinct from the existing works that rely on a single tri-plane deformation field for dynamic facial modeling, the proposed Tri$^2$-plane leverages the principle of feature pyramids and three top-to-down lateral connections tri-planes for details improvement. It samples and renders facial details at multiple scales, transitioning from the entire face to specific local regions and then to even more refined sub-regions. Moreover, we incorporate a camera-based geometry-aware sliding window method as an augmentation in training, which improves the robustness beyond the canonical space, with a particular improvement in cross-identity generation capabilities. Experimental outcomes indicate that the Tri$^2$-plane not only surpasses existing methodologies but also achieves superior performance across quantitative and qualitative assessments. The project website is: url{https://songluchuan.github.io/Tri2Plane.github.io/}.
Read more7/12/2024

0
SphereHead: Stable 3D Full-head Synthesis with Spherical Tri-plane Representation
Heyuan Li, Ce Chen, Tianhao Shi, Yuda Qiu, Sizhe An, Guanying Chen, Xiaoguang Han
While recent advances in 3D-aware Generative Adversarial Networks (GANs) have aided the development of near-frontal view human face synthesis, the challenge of comprehensively synthesizing a full 3D head viewable from all angles still persists. Although PanoHead proves the possibilities of using a large-scale dataset with images of both frontal and back views for full-head synthesis, it often causes artifacts for back views. Based on our in-depth analysis, we found the reasons are mainly twofold. First, from network architecture perspective, we found each plane in the utilized tri-plane/tri-grid representation space tends to confuse the features from both sides, causing mirroring artifacts (e.g., the glasses appear in the back). Second, from data supervision aspect, we found that existing discriminator training in 3D GANs mainly focuses on the quality of the rendered image itself, and does not care much about its plausibility with the perspective from which it was rendered. This makes it possible to generate face in non-frontal views, due to its easiness to fool the discriminator. In response, we propose SphereHead, a novel tri-plane representation in the spherical coordinate system that fits the human head's geometric characteristics and efficiently mitigates many of the generated artifacts. We further introduce a view-image consistency loss for the discriminator to emphasize the correspondence of the camera parameters and the images. The combination of these efforts results in visually superior outcomes with significantly fewer artifacts. Our code and dataset are publicly available at https://lhyfst.github.io/spherehead.
Read more7/17/2024
0
Learning to Generate Conditional Tri-plane for 3D-aware Expression Controllable Portrait Animation
Taekyung Ki, Dongchan Min, Gyeongsu Chae
In this paper, we present Export3D, a one-shot 3D-aware portrait animation method that is able to control the facial expression and camera view of a given portrait image. To achieve this, we introduce a tri-plane generator with an effective expression conditioning method, which directly generates a tri-plane of 3D prior by transferring the expression parameter of 3DMM into the source image. The tri-plane is then decoded into the image of different view through a differentiable volume rendering. Existing portrait animation methods heavily rely on image warping to transfer the expression in the motion space, challenging on disentanglement of appearance and expression. In contrast, we propose a contrastive pre-training framework for appearance-free expression parameter, eliminating undesirable appearance swap when transferring a cross-identity expression. Extensive experiments show that our pre-training framework can learn the appearance-free expression representation hidden in 3DMM, and our model can generate 3D-aware expression controllable portrait images without appearance swap in the cross-identity manner.
Read more7/24/2024
✅
0
PlaneRecTR++: Unified Query Learning for Joint 3D Planar Reconstruction and Pose Estimation
Jingjia Shi, Shuaifeng Zhi, Kai Xu
3D plane reconstruction from images can usually be divided into several sub-tasks of plane detection, segmentation, parameters regression and possibly depth prediction for per-frame, along with plane correspondence and relative camera pose estimation between frames. Previous works tend to divide and conquer these sub-tasks with distinct network modules, overall formulated by a two-stage paradigm. With an initial camera pose and per-frame plane predictions provided from the first stage, exclusively designed modules, potentially relying on extra plane correspondence labelling, are applied to merge multi-view plane entities and produce 6DoF camera pose. As none of existing works manage to integrate above closely related sub-tasks into a unified framework but treat them separately and sequentially, we suspect it potentially as a main source of performance limitation for existing approaches. Motivated by this finding and the success of query-based learning in enriching reasoning among semantic entities, in this paper, we propose PlaneRecTR++, a Transformer-based architecture, which for the first time unifies all sub-tasks related to multi-view reconstruction and pose estimation with a compact single-stage model, refraining from initial pose estimation and plane correspondence supervision. Extensive quantitative and qualitative experiments demonstrate that our proposed unified learning achieves mutual benefits across sub-tasks, obtaining a new state-of-the-art performance on public ScanNetv1, ScanNetv2, NYUv2-Plane, and MatterPort3D datasets.
Read more9/10/2024