Trust the Model Where It Trusts Itself -- Model-Based Actor-Critic with Uncertainty-Aware Rollout Adaption
2405.19014
0
0

Abstract
Dyna-style model-based reinforcement learning (MBRL) combines model-free agents with predictive transition models through model-based rollouts. This combination raises a critical question: 'When to trust your model?'; i.e., which rollout length results in the model providing useful data? Janner et al. (2019) address this question by gradually increasing rollout lengths throughout the training. While theoretically tempting, uniform model accuracy is a fallacy that collapses at the latest when extrapolating. Instead, we propose asking the question 'Where to trust your model?'. Using inherent model uncertainty to consider local accuracy, we obtain the Model-Based Actor-Critic with Uncertainty-Aware Rollout Adaption (MACURA) algorithm. We propose an easy-to-tune rollout mechanism and demonstrate substantial improvements in data efficiency and performance compared to state-of-the-art deep MBRL methods on the MuJoCo benchmark.
Create account to get full access
Overview
- This paper proposes a novel model-based actor-critic reinforcement learning algorithm called "Trust the Model Where It Trusts Itself" (TMWTIT).
- The key idea is to adaptively adjust the length of the model-based rollouts during training based on the model's own uncertainty estimates.
- This allows the algorithm to "trust the model where it trusts itself" and rely more on the model's predictions when it is confident, while falling back to model-free exploration when the model is uncertain.
- The authors demonstrate the effectiveness of TMWTIT on several challenging continuous control tasks, showing improved sample efficiency and final performance compared to prior methods.
Plain English Explanation
In reinforcement learning, agents often use models of the environment to predict future states and plan their actions. However, these models can be imperfect and lead to errors if relied upon blindly. The TMWTIT algorithm aims to address this by adaptively adjusting how much the agent trusts the model during training.
The key idea is to have the model provide estimates of its own uncertainty - how confident it is in its predictions. When the model is very confident, the agent can trust it more and use longer "rollouts" (sequences of predicted future states) to plan its actions. But when the model is uncertain, the agent should rely more on direct interaction with the environment through model-free exploration.
By "trusting the model where it trusts itself," the agent can get the benefits of model-based planning when the model is reliable, while avoiding the pitfalls of relying on an uncertain model. This helps the agent learn more efficiently and achieve better performance than prior methods that use fixed rollout lengths or don't account for model uncertainty.
The TMWTIT algorithm is demonstrated on challenging continuous control tasks, showing improved sample efficiency and final performance compared to previous approaches. This adaptive use of model predictions based on uncertainty is a promising direction for making model-based reinforcement learning more robust and effective.
Technical Explanation
The TMWTIT algorithm builds on the model-based actor-critic framework, where the agent learns a dynamics model of the environment in addition to the policy and value function. However, rather than using a fixed rollout length during planning, TMWTIT adaptively adjusts the rollout length based on the model's own uncertainty estimates.
Specifically, the dynamics model outputs not just predicted next states, but also estimates of the epistemic (model) uncertainty in those predictions. The actor-critic updates then use shorter rollouts when the model is uncertain, and longer rollouts when the model is confident. This allows the agent to "trust the model where it trusts itself" - relying more on the model's predictions when it is reliable, while falling back to model-free exploration when the model is uncertain.
The authors demonstrate TMWTIT on several continuous control tasks from the MuJoCo and Roboschool environments. Compared to prior model-based and model-free reinforcement learning methods, TMWTIT demonstrates improved sample efficiency and final performance.
Critical Analysis
The TMWTIT algorithm represents a promising step towards more robust and effective model-based reinforcement learning. By adaptively adjusting the reliance on the model's predictions based on its own uncertainty estimates, the algorithm can avoid the pitfalls of blindly trusting an imperfect model.
However, the paper does not extensively explore the limitations of this approach. For example, the quality of the uncertainty estimates themselves could be a potential weakness - if the model is overconfident in its predictions, the agent may still trust the model too much in uncertain situations. Additionally, the computational overhead of simultaneously training the dynamics model, uncertainty estimates, and the actor-critic policies may limit the scalability of the approach.
Further research could investigate techniques to improve the reliability of the model uncertainty estimates, as well as ways to better balance the model-based and model-free components of the algorithm. Comparisons to other methods for managing model uncertainty, such as ensembles or uncertainty-aware exploration, would also help situate the contributions of TMWTIT within the broader field of model-based RL.
Overall, the TMWTIT algorithm represents an interesting and valuable step towards making model-based reinforcement learning more robust and practical. With further research and refinement, approaches like this could help unlock the full potential of model-based methods in challenging real-world applications.
Conclusion
The TMWTIT algorithm introduces a novel model-based actor-critic framework that adaptively adjusts the reliance on the model's predictions based on its own uncertainty estimates. By "trusting the model where it trusts itself," the agent can combine the benefits of model-based planning and model-free exploration, leading to improved sample efficiency and performance on challenging continuous control tasks.
While the approach has some limitations that merit further research, TMWTIT represents an important and promising step towards making model-based reinforcement learning more robust and practical. As the field continues to advance, techniques like this that can effectively manage model uncertainty will be crucial for unlocking the full potential of model-based methods in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Acting upon Imagination: when to trust imagined trajectories in model based reinforcement learning
Adrian Remonda, Eduardo Veas, Granit Luzhnica
0
0
Model-based reinforcement learning (MBRL) aims to learn model(s) of the environment dynamics that can predict the outcome of its actions. Forward application of the model yields so called imagined trajectories (sequences of action, predicted state-reward) used to optimize the set of candidate actions that maximize expected reward. The outcome, an ideal imagined trajectory or plan, is imperfect and typically MBRL relies on model predictive control (MPC) to overcome this by continuously re-planning from scratch, incurring thus major computational cost and increasing complexity in tasks with longer receding horizon. We propose uncertainty estimation methods for online evaluation of imagined trajectories to assess whether further planned actions can be trusted to deliver acceptable reward. These methods include comparing the error after performing the last action with the standard expected error and using model uncertainty to assess the deviation from expected outcomes. Additionally, we introduce methods that exploit the forward propagation of the dynamics model to evaluate if the remainder of the plan aligns with expected results and assess the remainder of the plan in terms of the expected reward. Our experiments demonstrate the effectiveness of the proposed uncertainty estimation methods by applying them to avoid unnecessary trajectory replanning in a shooting MBRL setting. Results highlight significant reduction on computational costs without sacrificing performance.
4/22/2024
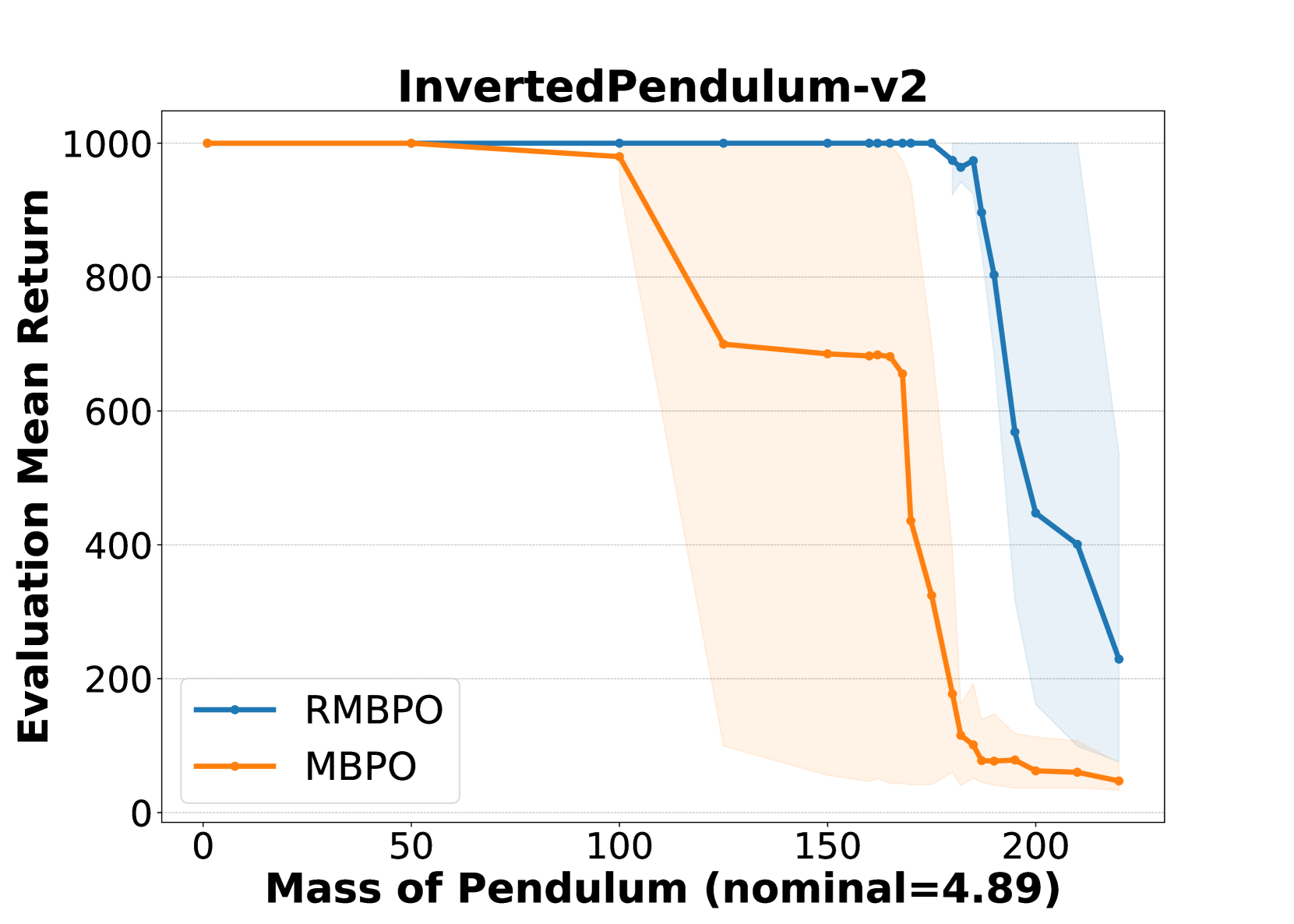
Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
Siemen Herremans, Ali Anwar, Siegfried Mercelis
0
0
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
7/2/2024
🔗
Adaptive Horizon Actor-Critic for Policy Learning in Contact-Rich Differentiable Simulation
Ignat Georgiev, Krishnan Srinivasan, Jie Xu, Eric Heiden, Animesh Garg
0
0
Model-Free Reinforcement Learning (MFRL), leveraging the policy gradient theorem, has demonstrated considerable success in continuous control tasks. However, these approaches are plagued by high gradient variance due to zeroth-order gradient estimation, resulting in suboptimal policies. Conversely, First-Order Model-Based Reinforcement Learning (FO-MBRL) methods employing differentiable simulation provide gradients with reduced variance but are susceptible to sampling error in scenarios involving stiff dynamics, such as physical contact. This paper investigates the source of this error and introduces Adaptive Horizon Actor-Critic (AHAC), an FO-MBRL algorithm that reduces gradient error by adapting the model-based horizon to avoid stiff dynamics. Empirical findings reveal that AHAC outperforms MFRL baselines, attaining 40% more reward across a set of locomotion tasks and efficiently scaling to high-dimensional control environments with improved wall-clock-time efficiency.
6/5/2024

Safe Deep Model-Based Reinforcement Learning with Lyapunov Functions
Harry Zhang
0
0
Model-based Reinforcement Learning (MBRL) has shown many desirable properties for intelligent control tasks. However, satisfying safety and stability constraints during training and rollout remains an open question. We propose a new Model-based RL framework to enable efficient policy learning with unknown dynamics based on learning model predictive control (LMPC) framework with mathematically provable guarantees of stability. We introduce and explore a novel method for adding safety constraints for model-based RL during training and policy learning. The new stability-augmented framework consists of a neural-network-based learner that learns to construct a Lyapunov function, and a model-based RL agent to consistently complete the tasks while satisfying user-specified constraints given only sub-optimal demonstrations and sparse-cost feedback. We demonstrate the capability of the proposed framework through simulated experiments.
5/28/2024