TSCLIP: Robust CLIP Fine-Tuning for Worldwide Cross-Regional Traffic Sign Recognition

0

Sign in to get full access
Overview
- Proposes a robust CLIP fine-tuning approach called TSCLIP for cross-regional traffic sign recognition
- Addresses the challenge of training computer vision models to recognize diverse traffic signs across different geographic regions
- Leverages the power of the CLIP (Contrastive Language-Image Pre-training) model as a strong baseline
Plain English Explanation
The paper presents a new technique called TSCLIP (Traffic Sign CLIP) for training computer vision models to recognize traffic signs from around the world. Recognizing traffic signs is an important task for self-driving cars and other applications, but traffic signs can vary a lot depending on the country or region.
The researchers use a popular AI model called CLIP as a starting point. CLIP is trained on a huge amount of online data to learn how to connect images and text. The researchers then "fine-tune" CLIP on a dataset of traffic sign images and labels, allowing it to specialize in recognizing traffic signs.
This fine-tuning process helps the model learn the unique visual features and patterns of traffic signs, making it more robust to variations across different geographic regions. The researchers demonstrate that TSCLIP outperforms other approaches for cross-regional traffic sign recognition.
Technical Explanation
The key technical contributions of the paper are:
-
TSCLIP Architecture: The researchers fine-tune the CLIP model, which was pre-trained on a large-scale image-text dataset, on a traffic sign recognition dataset. This allows TSCLIP to leverage CLIP's powerful cross-modal representation learning capabilities while specializing in traffic sign recognition.
-
Cross-Regional Training: To make TSCLIP robust to geographic variations, the researchers use a training strategy that exposes the model to traffic sign data from multiple regions during fine-tuning. This helps the model learn shared visual features that generalize well across different regional datasets.
-
Evaluation on Diverse Benchmarks: The paper evaluates TSCLIP on several cross-regional traffic sign recognition benchmarks, demonstrating its strong performance compared to other state-of-the-art approaches. This includes datasets covering different parts of the world, such as Europe, the US, and China.
Critical Analysis
The paper makes a compelling case for the effectiveness of the TSCLIP approach, but a few potential limitations and areas for future work are worth noting:
-
While TSCLIP demonstrates strong cross-regional performance, the paper does not explore how it would scale to truly global coverage of traffic signs from all around the world. Further research may be needed to assess its robustness at that scale.
-
The paper focuses on recognizing traffic signs, but real-world self-driving applications would also require understanding the semantic meaning and context of the signs. Extending TSCLIP to these higher-level reasoning tasks could be an area for future work.
-
The evaluation is primarily quantitative, based on recognition accuracy metrics. Incorporating more qualitative analysis, such as failure case studies or user experience assessments, could provide additional insights into TSCLIP's strengths and weaknesses.
Conclusion
Overall, the TSCLIP approach presented in this paper represents an important step forward in building robust computer vision models for cross-regional traffic sign recognition. By leveraging the power of CLIP and adopting a cross-regional fine-tuning strategy, the researchers have developed a technique that can reliably identify traffic signs in diverse geographic contexts. This work has significant implications for the development of reliable self-driving technologies and other transportation-related applications that rely on accurate traffic sign recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TSCLIP: Robust CLIP Fine-Tuning for Worldwide Cross-Regional Traffic Sign Recognition
Guoyang Zhao, Fulong Ma, Weiqing Qi, Chenguang Zhang, Yuxuan Liu, Ming Liu, Jun Ma
Traffic sign is a critical map feature for navigation and traffic control. Nevertheless, current methods for traffic sign recognition rely on traditional deep learning models, which typically suffer from significant performance degradation considering the variations in data distribution across different regions. In this paper, we propose TSCLIP, a robust fine-tuning approach with the contrastive language-image pre-training (CLIP) model for worldwide cross-regional traffic sign recognition. We first curate a cross-regional traffic sign benchmark dataset by combining data from ten different sources. Then, we propose a prompt engineering scheme tailored to the characteristics of traffic signs, which involves specific scene descriptions and corresponding rules to generate targeted text descriptions for optimizing the model training process. During the TSCLIP fine-tuning process, we implement adaptive dynamic weight ensembling (ADWE) to seamlessly incorporate outcomes from each training iteration with the zero-shot CLIP model. This approach ensures that the model retains its ability to generalize while acquiring new knowledge about traffic signs. Our method surpasses conventional classification benchmark models in cross-regional traffic sign evaluations, and it achieves state-of-the-art performance compared to existing CLIP fine-tuning techniques. To the best knowledge of authors, TSCLIP is the first contrastive language-image model used for the worldwide cross-regional traffic sign recognition task. The project website is available at: https://github.com/guoyangzhao/TSCLIP.
Read more9/24/2024
0
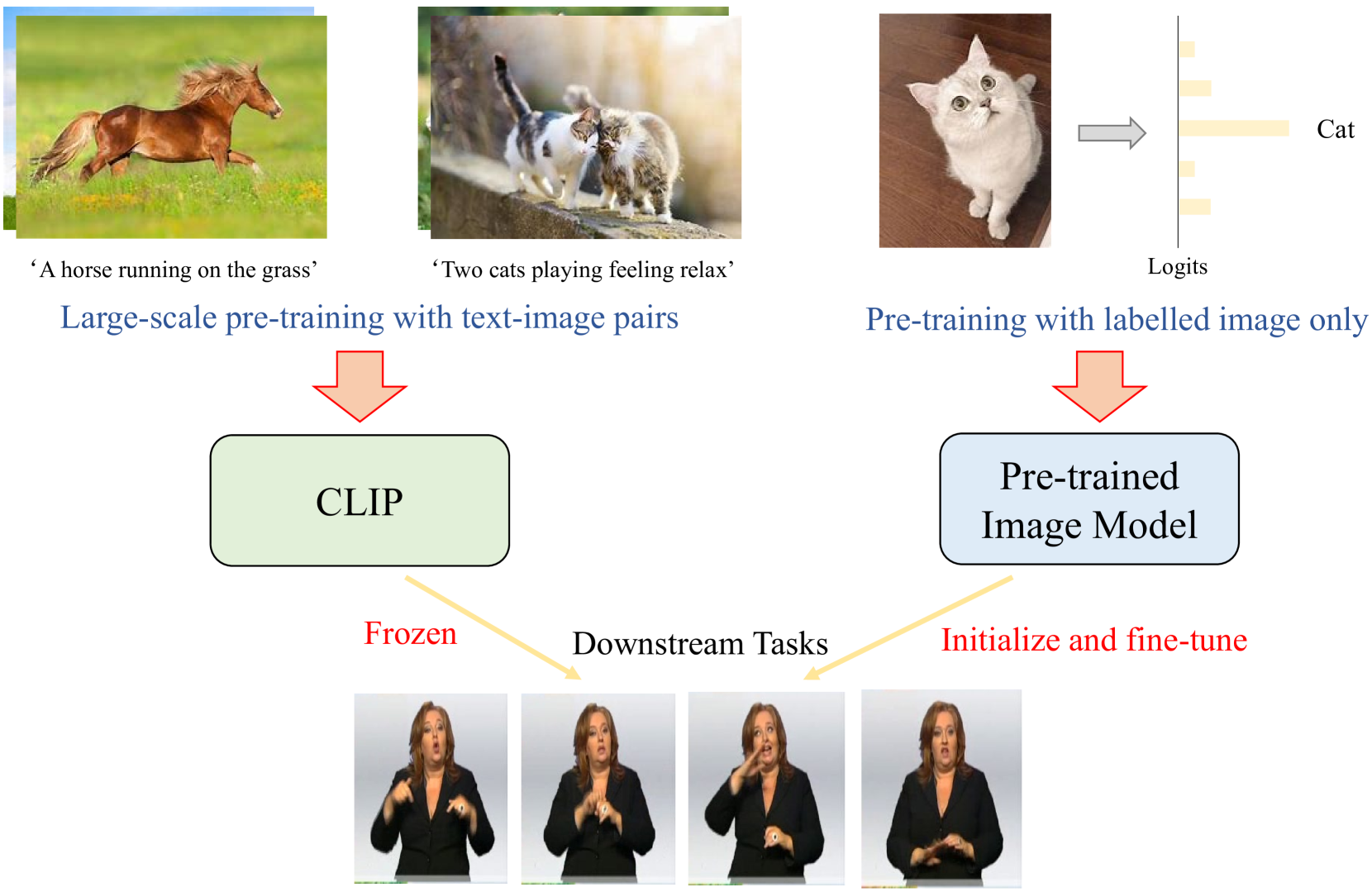
Improving Continuous Sign Language Recognition with Adapted Image Models
Lianyu Hu, Tongkai Shi, Liqing Gao, Zekang Liu, Wei Feng
The increase of web-scale weakly labelled image-text pairs have greatly facilitated the development of large-scale vision-language models (e.g., CLIP), which have shown impressive generalization performance over a series of downstream tasks. However, the massive model size and scarcity of available data limit their applications to fine-tune the whole model in downstream tasks. Besides, fully fine-tuning the model easily forgets the generic essential knowledge acquired in the pretraining stage and overfits the downstream data. To enable high efficiency when adapting these large vision-language models (e.g., CLIP) to performing continuous sign language recognition (CSLR) while preserving their generalizability, we propose a novel strategy (AdaptSign). Especially, CLIP is adopted as the visual backbone to extract frame-wise features whose parameters are fixed, and a set of learnable modules are introduced to model spatial sign variations or capture temporal sign movements. The introduced additional modules are quite lightweight, only owning 3.2% extra computations with high efficiency. The generic knowledge acquired in the pretraining stage is well-preserved in the frozen CLIP backbone in this process. Extensive experiments show that despite being efficient, AdaptSign is able to demonstrate superior performance across a series of CSLR benchmarks including PHOENIX14, PHOENIX14-T, CSL-Daily and CSL compared to existing methods. Visualizations show that AdaptSign could learn to dynamically pay major attention to the informative spatial regions and cross-frame trajectories in sign videos.
Read more4/15/2024

0
Cross-domain Few-shot In-context Learning for Enhancing Traffic Sign Recognition
Yaozong Gan, Guang Li, Ren Togo, Keisuke Maeda, Takahiro Ogawa, Miki Haseyama
Recent multimodal large language models (MLLM) such as GPT-4o and GPT-4v have shown great potential in autonomous driving. In this paper, we propose a cross-domain few-shot in-context learning method based on the MLLM for enhancing traffic sign recognition (TSR). We first construct a traffic sign detection network based on Vision Transformer Adapter and an extraction module to extract traffic signs from the original road images. To reduce the dependence on training data and improve the performance stability of cross-country TSR, we introduce a cross-domain few-shot in-context learning method based on the MLLM. To enhance MLLM's fine-grained recognition ability of traffic signs, the proposed method generates corresponding description texts using template traffic signs. These description texts contain key information about the shape, color, and composition of traffic signs, which can stimulate the ability of MLLM to perceive fine-grained traffic sign categories. By using the description texts, our method reduces the cross-domain differences between template and real traffic signs. Our approach requires only simple and uniform textual indications, without the need for large-scale traffic sign images and labels. We perform comprehensive evaluations on the German traffic sign recognition benchmark dataset, the Belgium traffic sign dataset, and two real-world datasets taken from Japan. The experimental results show that our method significantly enhances the TSR performance.
Read more7/9/2024

0
SignCLIP: Connecting Text and Sign Language by Contrastive Learning
Zifan Jiang, Gerard Sant, Amit Moryossef, Mathias Muller, Rico Sennrich, Sarah Ebling
We present SignCLIP, which re-purposes CLIP (Contrastive Language-Image Pretraining) to project spoken language text and sign language videos, two classes of natural languages of distinct modalities, into the same space. SignCLIP is an efficient method of learning useful visual representations for sign language processing from large-scale, multilingual video-text pairs, without directly optimizing for a specific task or sign language which is often of limited size. We pretrain SignCLIP on Spreadthesign, a prominent sign language dictionary consisting of ~500 thousand video clips in up to 44 sign languages, and evaluate it with various downstream datasets. SignCLIP discerns in-domain signing with notable text-to-video/video-to-text retrieval accuracy. It also performs competitively for out-of-domain downstream tasks such as isolated sign language recognition upon essential few-shot prompting or fine-tuning. We analyze the latent space formed by the spoken language text and sign language poses, which provides additional linguistic insights. Our code and models are openly available.
Read more7/2/2024