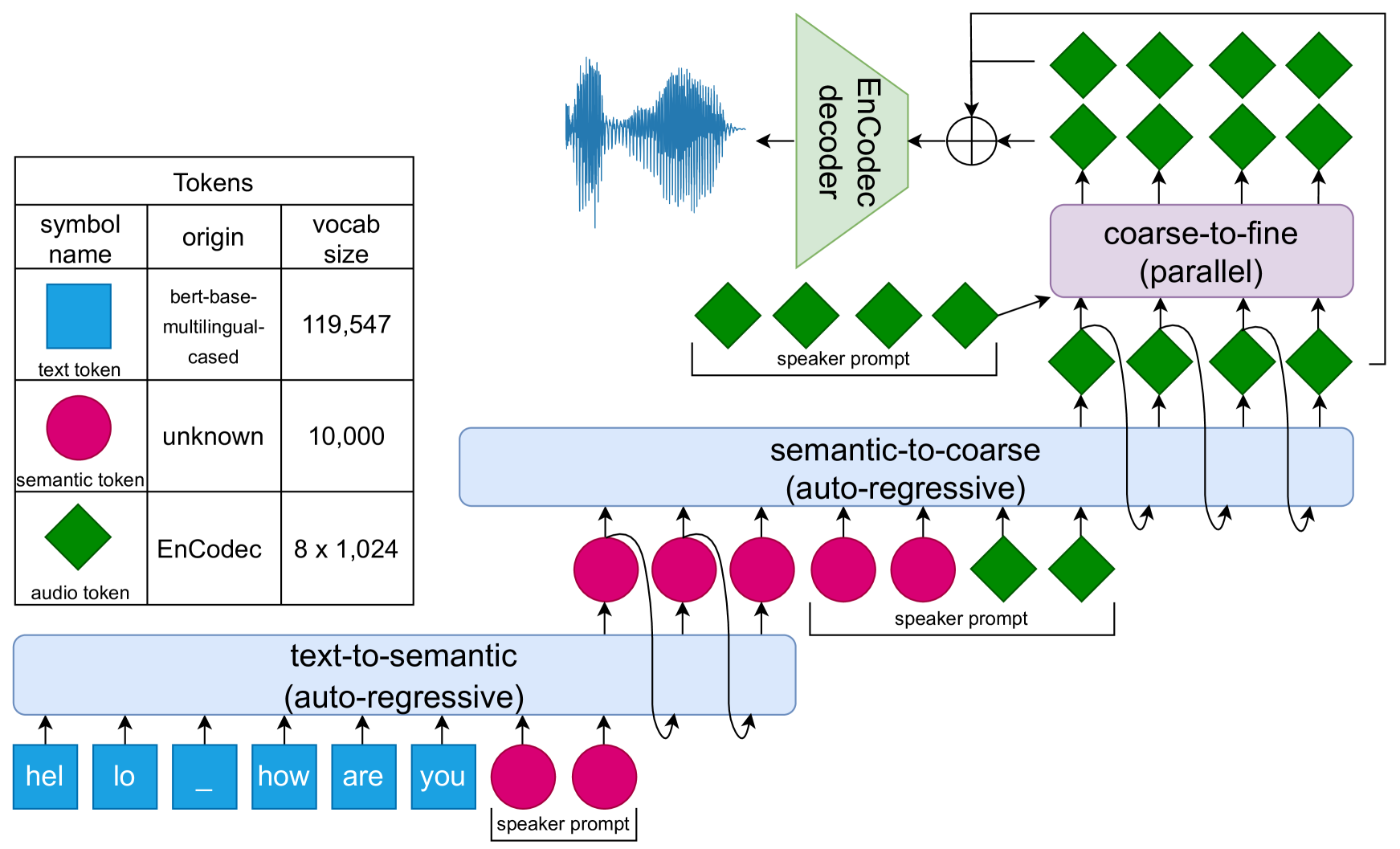
TTSDS -- Text-to-Speech Distribution Score

0

Sign in to get full access
Overview
- This paper introduces a new evaluation metric called the Text-to-Speech Distribution Score (TTSDS) for assessing the performance of text-to-speech (TTS) systems.
- TTSDS aims to provide a more comprehensive and reliable way to evaluate TTS models by considering not just the synthetic speech quality, but also its similarity to the natural speech distribution.
- The paper demonstrates the application of TTSDS on several state-of-the-art TTS models and highlights its advantages over existing evaluation metrics.
Plain English Explanation
Text-to-speech (TTS) systems are used to convert written text into spoken audio. Evaluating the performance of these systems is crucial, as it helps researchers and developers improve the technology. The provided paper introduces a new evaluation metric called the Text-to-Speech Distribution Score (TTSDS) that aims to provide a more comprehensive assessment of TTS models.
The key idea behind TTSDS is to not just measure the quality of the synthetic speech, but also how well it matches the distribution of natural human speech. This is important because a high-quality TTS system should not only sound good, but also sound natural and human-like. TTSDS achieves this by analyzing various acoustic features extracted from the synthesized speech and comparing them to a reference dataset of natural human speech.
By using TTSDS, the researchers were able to evaluate several state-of-the-art TTS models and gain insights into their strengths and weaknesses. This information can help researchers and developers improve TTS systems to make them even more natural and human-like, which is important for applications like voice assistants, audiobooks, and automated customer service.
Technical Explanation
The paper introduces the Text-to-Speech Distribution Score (TTSDS), a new evaluation metric for text-to-speech (TTS) systems. TTSDS aims to provide a more comprehensive assessment of TTS performance by considering not just the quality of the synthetic speech, but also its similarity to the distribution of natural human speech.
The key steps in the TTSDS methodology are:
-
Feature Extraction: The researchers extract a set of acoustic features from the synthesized speech, including spectral, prosodic, and voice quality characteristics. These features capture various aspects of the speech that contribute to its naturalness and human-likeness.
-
Distribution Comparison: The distribution of the extracted features from the synthetic speech is then compared to the distribution of the same features in a reference dataset of natural human speech. This comparison is performed using a statistical distance metric, such as the Wasserstein distance.
-
TTSDS Calculation: The TTSDS is calculated as the average of the Wasserstein distances across all the extracted features. A lower TTSDS indicates that the synthetic speech is more similar to the natural speech distribution, and thus more natural-sounding.
The researchers demonstrate the application of TTSDS on several state-of-the-art TTS models, including Tacotron 2, USAT, and NaturalSpeech 3. They show that TTSDS provides a more nuanced evaluation of these models compared to traditional metrics like mean opinion score (MOS), highlighting their strengths and weaknesses in terms of naturalness and human-likeness.
Critical Analysis
The TTSDS metric proposed in this paper provides a valuable addition to the arsenal of TTS evaluation tools. By considering the distribution of various acoustic features, TTSDS offers a more comprehensive assessment of how natural and human-like the synthesized speech sounds, rather than just focusing on perceived quality.
One potential limitation of the TTSDS approach is the reliance on a reference dataset of natural human speech. The quality and representativeness of this dataset can have a significant impact on the TTSDS results. The paper does not provide detailed information about the reference dataset used, which could be an area for further investigation.
Additionally, the paper does not directly compare TTSDS to other recently proposed TTS evaluation metrics, such as StoryTTS, which also aim to assess the naturalness and expressiveness of synthetic speech. A comparative analysis of these different evaluation approaches could help researchers and practitioners understand the strengths and weaknesses of each method.
Overall, the TTSDS metric represents a promising step forward in the evaluation of TTS systems, and the insights gained from its application can help drive the development of more natural and human-like text-to-speech technologies.
Conclusion
The Text-to-Speech Distribution Score (TTSDS) introduced in this paper offers a novel approach to evaluating the performance of text-to-speech (TTS) systems. By considering the distribution of various acoustic features in the synthesized speech and comparing them to a reference dataset of natural human speech, TTSDS provides a more comprehensive assessment of TTS naturalness and human-likeness.
The application of TTSDS on several state-of-the-art TTS models demonstrates its ability to highlight the strengths and weaknesses of these systems in a way that traditional metrics like mean opinion score (MOS) may not capture. This information can be invaluable for researchers and developers working to improve TTS technology, which is crucial for applications ranging from voice assistants to audiobooks and automated customer service.
While the TTSDS approach has some limitations, such as the reliance on a reference dataset, it represents a significant step forward in the field of TTS evaluation. As the research in this area continues to evolve, the insights and methodologies introduced in this paper are likely to have a lasting impact on the development of more natural and human-like text-to-speech systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TTSDS -- Text-to-Speech Distribution Score
Christoph Minixhofer, Ondv{r}ej Klejch, Peter Bell
Many recently published Text-to-Speech (TTS) systems produce audio close to real speech. However, TTS evaluation needs to be revisited to make sense of the results obtained with the new architectures, approaches and datasets. We propose evaluating the quality of synthetic speech as a combination of multiple factors such as prosody, speaker identity, and intelligibility. Our approach assesses how well synthetic speech mirrors real speech by obtaining correlates of each factor and measuring their distance from both real speech datasets and noise datasets. We benchmark 35 TTS systems developed between 2008 and 2024 and show that our score computed as an unweighted average of factors strongly correlates with the human evaluations from each time period.
Read more7/23/2024

0
On the Problem of Text-To-Speech Model Selection for Synthetic Data Generation in Automatic Speech Recognition
Nick Rossenbach, Ralf Schluter, Sakriani Sakti
The rapid development of neural text-to-speech (TTS) systems enabled its usage in other areas of natural language processing such as automatic speech recognition (ASR) or spoken language translation (SLT). Due to the large number of different TTS architectures and their extensions, selecting which TTS systems to use for synthetic data creation is not an easy task. We use the comparison of five different TTS decoder architectures in the scope of synthetic data generation to show the impact on CTC-based speech recognition training. We compare the recognition results to computable metrics like NISQA MOS and intelligibility, finding that there are no clear relations to the ASR performance. We also observe that for data generation auto-regressive decoding performs better than non-autoregressive decoding, and propose an approach to quantify TTS generalization capabilities.
Read more8/1/2024
0
Evaluating Text-to-Speech Synthesis from a Large Discrete Token-based Speech Language Model
Siyang Wang, 'Eva Sz'ekely
Recent advances in generative language modeling applied to discrete speech tokens presented a new avenue for text-to-speech (TTS) synthesis. These speech language models (SLMs), similarly to their textual counterparts, are scalable, probabilistic, and context-aware. While they can produce diverse and natural outputs, they sometimes face issues such as unintelligibility and the inclusion of non-speech noises or hallucination. As the adoption of this innovative paradigm in speech synthesis increases, there is a clear need for an in-depth evaluation of its capabilities and limitations. In this paper, we evaluate TTS from a discrete token-based SLM, through both automatic metrics and listening tests. We examine five key dimensions: speaking style, intelligibility, speaker consistency, prosodic variation, spontaneous behaviour. Our results highlight the model's strength in generating varied prosody and spontaneous outputs. It is also rated higher in naturalness and context appropriateness in listening tests compared to a conventional TTS. However, the model's performance in intelligibility and speaker consistency lags behind traditional TTS. Additionally, we show that increasing the scale of SLMs offers a modest boost in robustness. Our findings aim to serve as a benchmark for future advancements in generative SLMs for speech synthesis.
Read more5/17/2024
🏋️
0
On the Effect of Purely Synthetic Training Data for Different Automatic Speech Recognition Architectures
Nick Rossenbach, Benedikt Hilmes, Ralf Schluter
In this work we evaluate the utility of synthetic data for training automatic speech recognition (ASR). We use the ASR training data to train a text-to-speech (TTS) system similar to FastSpeech-2. With this TTS we reproduce the original training data, training ASR systems solely on synthetic data. For ASR, we use three different architectures, attention-based encoder-decoder, hybrid deep neural network hidden Markov model and a Gaussian mixture hidden Markov model, showing the different sensitivity of the models to synthetic data generation. In order to extend previous work, we present a number of ablation studies on the effectiveness of synthetic vs. real training data for ASR. In particular we focus on how the gap between training on synthetic and real data changes by varying the speaker embedding or by scaling the model size. For the latter we show that the TTS models generalize well, even when training scores indicate overfitting.
Read more7/26/2024