UMass-BioNLP at MEDIQA-M3G 2024: DermPrompt -- A Systematic Exploration of Prompt Engineering with GPT-4V for Dermatological Diagnosis

0

Sign in to get full access
Overview
- This paper presents DermPrompt, a systematic exploration of prompt engineering with GPT-4V for dermatological diagnosis.
- The researchers investigate how prompt design can enhance the performance of large language models in the context of medical image classification for skin conditions.
- The study evaluates various prompt strategies and their impact on the accuracy, robustness, and interpretability of the GPT-4V model for dermatological diagnosis.
Plain English Explanation
The researchers in this paper looked at ways to improve how a powerful language model called GPT-4V could be used to diagnose skin conditions. They explored different ways of giving instructions, or "prompts," to the model to see how that affected its ability to accurately identify skin problems, handle difficult cases, and explain its reasoning.
The key idea is that the way you phrase the instructions you give to a language model can have a big impact on how well it performs on a specific task, like diagnosing skin conditions. The researchers tried out different prompts to see which ones helped the model make more accurate diagnoses, be more reliable in tricky cases, and provide clearer explanations of its decisions.
This is an important area of research because language models like GPT-4V have the potential to be very useful tools for medical professionals, but we need to understand how to use them effectively. By carefully designing the prompts, the researchers aim to unlock the full potential of these models for tasks like dermatological diagnosis.
Technical Explanation
The paper presents DermPrompt, a systematic exploration of prompt engineering with the GPT-4V language model for dermatological diagnosis. The researchers investigate how prompt design can enhance the performance of large language models in the context of medical image classification for skin conditions.
The study evaluates various prompt strategies and their impact on the accuracy, robustness, and interpretability of the GPT-4V model. The researchers experiment with different prompts that vary in terms of task framing, instructions, and information provided to the model. They assess the model's performance on a dermatological diagnosis dataset and analyze the interpretability of its predictions.
The results demonstrate the significant impact of prompt engineering on the efficacy of the GPT-4V model for dermatological diagnosis. The researchers identify key prompt design principles and strategies that can enhance the model's accuracy, robustness, and transparency, making it a more reliable tool for medical professionals.
Critical Analysis
The paper provides a comprehensive and well-designed study on prompt engineering for dermatological diagnosis using the GPT-4V language model. The researchers have carefully considered various prompt strategies and their impact on the model's performance, addressing important aspects such as accuracy, robustness, and interpretability.
One potential limitation of the study is the reliance on a single dermatological diagnosis dataset. While this dataset is well-established, it would be beneficial to evaluate the prompt engineering strategies on additional datasets or even real-world clinical data to assess the generalizability of the findings.
Additionally, the paper does not delve deeply into the potential biases or limitations of the GPT-4V model itself. It would be valuable to investigate how the model's inherent biases or shortcomings might interact with the prompt engineering strategies and affect the overall performance and reliability of the system.
Despite these minor caveats, the study provides valuable insights into the importance of prompt engineering for leveraging the capabilities of large language models in the medical domain. The researchers' systematic approach and the practical implications of their findings make this paper an important contribution to the field of medical AI and prompt engineering.
Conclusion
This paper presents a comprehensive exploration of prompt engineering with the GPT-4V language model for dermatological diagnosis. The researchers demonstrate the significant impact of prompt design on the accuracy, robustness, and interpretability of the model's performance.
The key takeaway is that carefully crafting the instructions and information provided to language models can greatly enhance their capabilities for specialized tasks like medical image classification. This research highlights the importance of prompt engineering as a crucial aspect of developing reliable and transparent AI systems for healthcare applications.
The findings of this study have the potential to inform the development of more effective and trustworthy AI-powered diagnostic tools, ultimately improving patient care and supporting medical professionals in their decision-making processes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UMass-BioNLP at MEDIQA-M3G 2024: DermPrompt -- A Systematic Exploration of Prompt Engineering with GPT-4V for Dermatological Diagnosis
Parth Vashisht, Abhilasha Lodha, Mukta Maddipatla, Zonghai Yao, Avijit Mitra, Zhichao Yang, Junda Wang, Sunjae Kwon, Hong Yu
This paper presents our team's participation in the MEDIQA-ClinicalNLP2024 shared task B. We present a novel approach to diagnosing clinical dermatology cases by integrating large multimodal models, specifically leveraging the capabilities of GPT-4V under a retriever and a re-ranker framework. Our investigation reveals that GPT-4V, when used as a retrieval agent, can accurately retrieve the correct skin condition 85% of the time using dermatological images and brief patient histories. Additionally, we empirically show that Naive Chain-of-Thought (CoT) works well for retrieval while Medical Guidelines Grounded CoT is required for accurate dermatological diagnosis. Further, we introduce a Multi-Agent Conversation (MAC) framework and show its superior performance and potential over the best CoT strategy. The experiments suggest that using naive CoT for retrieval and multi-agent conversation for critique-based diagnosis, GPT-4V can lead to an early and accurate diagnosis of dermatological conditions. The implications of this work extend to improving diagnostic workflows, supporting dermatological education, and enhancing patient care by providing a scalable, accessible, and accurate diagnostic tool.
Read more5/10/2024
0
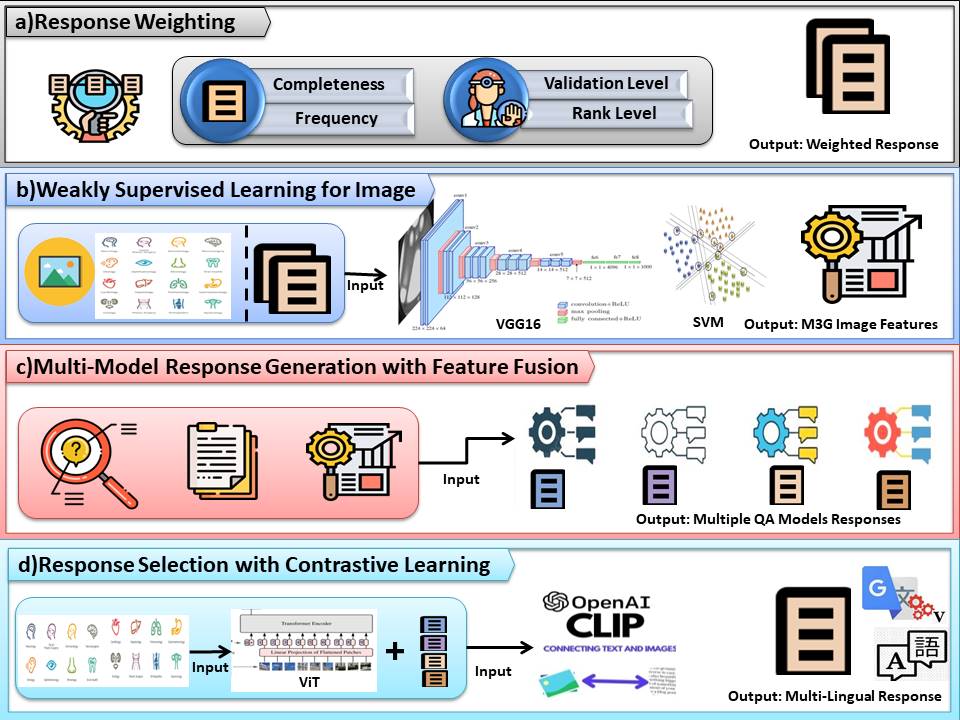
MediFact at MEDIQA-M3G 2024: Medical Question Answering in Dermatology with Multimodal Learning
Nadia Saeed
The MEDIQA-M3G 2024 challenge necessitates novel solutions for Multilingual & Multimodal Medical Answer Generation in dermatology (wai Yim et al., 2024a). This paper addresses the limitations of traditional methods by proposing a weakly supervised learning approach for open-ended medical question-answering (QA). Our system leverages readily available MEDIQA-M3G images via a VGG16-CNN-SVM model, enabling multilingual (English, Chinese, Spanish) learning of informative skin condition representations. Using pre-trained QA models, we further bridge the gap between visual and textual information through multimodal fusion. This approach tackles complex, open-ended questions even without predefined answer choices. We empower the generation of comprehensive answers by feeding the ViT-CLIP model with multiple responses alongside images. This work advances medical QA research, paving the way for clinical decision support systems and ultimately improving healthcare delivery.
Read more5/6/2024

0
Edinburgh Clinical NLP at MEDIQA-CORR 2024: Guiding Large Language Models with Hints
Aryo Pradipta Gema, Chaeeun Lee, Pasquale Minervini, Luke Daines, T. Ian Simpson, Beatrice Alex
The MEDIQA-CORR 2024 shared task aims to assess the ability of Large Language Models (LLMs) to identify and correct medical errors in clinical notes. In this study, we evaluate the capability of general LLMs, specifically GPT-3.5 and GPT-4, to identify and correct medical errors with multiple prompting strategies. Recognising the limitation of LLMs in generating accurate corrections only via prompting strategies, we propose incorporating error-span predictions from a smaller, fine-tuned model in two ways: 1) by presenting it as a hint in the prompt and 2) by framing it as multiple-choice questions from which the LLM can choose the best correction. We found that our proposed prompting strategies significantly improve the LLM's ability to generate corrections. Our best-performing solution with 8-shot + CoT + hints ranked sixth in the shared task leaderboard. Additionally, our comprehensive analyses show the impact of the location of the error sentence, the prompted role, and the position of the multiple-choice option on the accuracy of the LLM. This prompts further questions about the readiness of LLM to be implemented in real-world clinical settings.
Read more5/29/2024

0
MMGPL: Multimodal Medical Data Analysis with Graph Prompt Learning
Liang Peng, Songyue Cai, Zongqian Wu, Huifang Shang, Xiaofeng Zhu, Xiaoxiao Li
Prompt learning has demonstrated impressive efficacy in the fine-tuning of multimodal large models to a wide range of downstream tasks. Nonetheless, applying existing prompt learning methods for the diagnosis of neurological disorder still suffers from two issues: (i) existing methods typically treat all patches equally, despite the fact that only a small number of patches in neuroimaging are relevant to the disease, and (ii) they ignore the structural information inherent in the brain connection network which is crucial for understanding and diagnosing neurological disorders. To tackle these issues, we introduce a novel prompt learning model by learning graph prompts during the fine-tuning process of multimodal large models for diagnosing neurological disorders. Specifically, we first leverage GPT-4 to obtain relevant disease concepts and compute semantic similarity between these concepts and all patches. Secondly, we reduce the weight of irrelevant patches according to the semantic similarity between each patch and disease-related concepts. Moreover, we construct a graph among tokens based on these concepts and employ a graph convolutional network layer to extract the structural information of the graph, which is used to prompt the pre-trained multimodal large models for diagnosing neurological disorders. Extensive experiments demonstrate that our method achieves superior performance for neurological disorder diagnosis compared with state-of-the-art methods and validated by clinicians.
Read more6/28/2024