Understanding Biases in ChatGPT-based Recommender Systems: Provider Fairness, Temporal Stability, and Recency

0

Sign in to get full access
Overview
- This paper examines biases in ChatGPT-based recommender systems, focusing on provider fairness, temporal stability, and recency.
- The researchers conducted experiments to evaluate these biases and proposed strategies to mitigate them.
- The findings provide insights into the challenges and opportunities of using large language models like ChatGPT for recommendation tasks.
Plain English Explanation
Recommender systems are algorithms that suggest products, services, or content to users based on their preferences and behaviors. As large language models like ChatGPT become more prominent in the recommender systems era, it's important to understand the biases that can arise in these systems.
This paper explores three types of biases in ChatGPT-based recommender systems:
- Provider Fairness: How evenly are recommendations distributed across different providers or sources?
- Temporal Stability: How consistent are the recommendations over time, even as new content becomes available?
- Recency: How much weight do the recommendations give to recent or new content versus older items?
The researchers conducted experiments to measure these biases and proposed strategies to mitigate them. For example, they found that ChatGPT tended to favor recent movies in its recommendations, and they suggested ways to balance recency with other factors like popularity and diversity.
By understanding and addressing these biases, the researchers aim to improve the fairness, stability, and user experience of ChatGPT-based recommender systems and conversational recommenders. This work could also help mitigate bias in mental health analysis and other applications of large language models.
Technical Explanation
The researchers first defined three types of biases in ChatGPT-based recommender systems:
-
Provider Fairness: This measures how evenly the recommendations are distributed across different providers or sources (e.g., movie studios, publishers, etc.). Unfair distribution could disadvantage certain providers.
-
Temporal Stability: This evaluates how consistent the recommendations are over time, even as new content becomes available. Unstable recommendations could confuse or frustrate users.
-
Recency: This assesses how much weight the recommendations give to recent or new content versus older items. An excessive focus on recency could neglect valuable older content.
To quantify these biases, the researchers conducted experiments using a movie recommendation dataset. They prompted ChatGPT with various queries and analyzed the resulting recommendations. Their analysis included metrics like entropy, Gini coefficient, and rank correlation to measure the biases.
The results showed that ChatGPT's recommendations exhibited biases in all three areas. For example, the recommendations were skewed toward recent movies and tended to favor certain movie studios over others. The researchers then proposed strategies to mitigate these biases, such as adjusting the prompt design or incorporating additional signals into the recommendation process.
Critical Analysis
The researchers provide a thorough and rigorous analysis of biases in ChatGPT-based recommender systems. Their experiments are well-designed, and the metrics they use to quantify the biases are appropriate and insightful.
However, the paper does not fully address the potential impact of these biases on end-users. While the researchers discuss the theoretical implications of unfair, unstable, or overly recent recommendations, they do not present empirical data on how these biases affect user satisfaction, engagement, or trust in the recommender system.
Additionally, the paper focuses on a specific domain (movie recommendations) and a single large language model (ChatGPT). Further research is needed to understand if these biases are prevalent in other types of recommendations or across a wider range of large language models.
Despite these limitations, the researchers' work highlights the importance of carefully evaluating the biases in large language model-based recommender systems and developing mitigation strategies to improve the fairness, stability, and user experience of these systems.
Conclusion
This paper provides a valuable contribution to the understanding of biases in ChatGPT-based recommender systems. By identifying and quantifying biases related to provider fairness, temporal stability, and recency, the researchers shed light on the challenges and opportunities of using large language models for recommendation tasks.
The proposed mitigation strategies offer a starting point for improving the fairness and user experience of these systems. As large language models continue to play a growing role in conversational recommenders and other applications, this research can help ensure that the benefits of these technologies are distributed equitably and that the biases are mitigated to the greatest extent possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Understanding Biases in ChatGPT-based Recommender Systems: Provider Fairness, Temporal Stability, and Recency
Yashar Deldjoo
This paper explores the biases in ChatGPT-based recommender systems, focusing on provider fairness (item-side fairness). Through extensive experiments and over a thousand API calls, we investigate the impact of prompt design strategies-including structure, system role, and intent-on evaluation metrics such as provider fairness, catalog coverage, temporal stability, and recency. The first experiment examines these strategies in classical top-K recommendations, while the second evaluates sequential in-context learning (ICL). In the first experiment, we assess seven distinct prompt scenarios on top-K recommendation accuracy and fairness. Accuracy-oriented prompts, like Simple and Chain-of-Thought (COT), outperform diversification prompts, which, despite enhancing temporal freshness, reduce accuracy by up to 50%. Embedding fairness into system roles, such as act as a fair recommender, proved more effective than fairness directives within prompts. Diversification prompts led to recommending newer movies, offering broader genre distribution compared to traditional collaborative filtering (CF) models. The second experiment explores sequential ICL, comparing zero-shot and few-shot ICL. Results indicate that including user demographic information in prompts affects model biases and stereotypes. However, ICL did not consistently improve item fairness and catalog coverage over zero-shot learning. Zero-shot learning achieved higher NDCG and coverage, while ICL-2 showed slight improvements in hit rate (HR) when age-group context was included. Our study provides insights into biases of RecLLMs, particularly in provider fairness and catalog coverage. By examining prompt design, learning strategies, and system roles, we highlight the potential and challenges of integrating LLMs into recommendation systems. Further details can be found at https://github.com/yasdel/Benchmark_RecLLM_Fairness.
Read more7/8/2024
🤿
0
Evaluating ChatGPT as a Recommender System: A Rigorous Approach
Dario Di Palma, Giovanni Maria Biancofiore, Vito Walter Anelli, Fedelucio Narducci, Tommaso Di Noia, Eugenio Di Sciascio
Large Language Models (LLMs) have recently shown impressive abilities in handling various natural language-related tasks. Among different LLMs, current studies have assessed ChatGPT's superior performance across manifold tasks, especially under the zero/few-shot prompting conditions. Given such successes, the Recommender Systems (RSs) research community have started investigating its potential applications within the recommendation scenario. However, although various methods have been proposed to integrate ChatGPT's capabilities into RSs, current research struggles to comprehensively evaluate such models while considering the peculiarities of generative models. Often, evaluations do not consider hallucinations, duplications, and out-of-the-closed domain recommendations and solely focus on accuracy metrics, neglecting the impact on beyond-accuracy facets. To bridge this gap, we propose a robust evaluation pipeline to assess ChatGPT's ability as an RS and post-process ChatGPT recommendations to account for these aspects. Through this pipeline, we investigate ChatGPT-3.5 and ChatGPT-4 performance in the recommendation task under the zero-shot condition employing the role-playing prompt. We analyze the model's functionality in three settings: the Top-N Recommendation, the cold-start recommendation, and the re-ranking of a list of recommendations, and in three domains: movies, music, and books. The experiments reveal that ChatGPT exhibits higher accuracy than the baselines on books domain. It also excels in re-ranking and cold-start scenarios while maintaining reasonable beyond-accuracy metrics. Furthermore, we measure the similarity between the ChatGPT recommendations and the other recommenders, providing insights about how ChatGPT could be categorized in the realm of recommender systems. The evaluation pipeline is publicly released for future research.
Read more6/5/2024
2
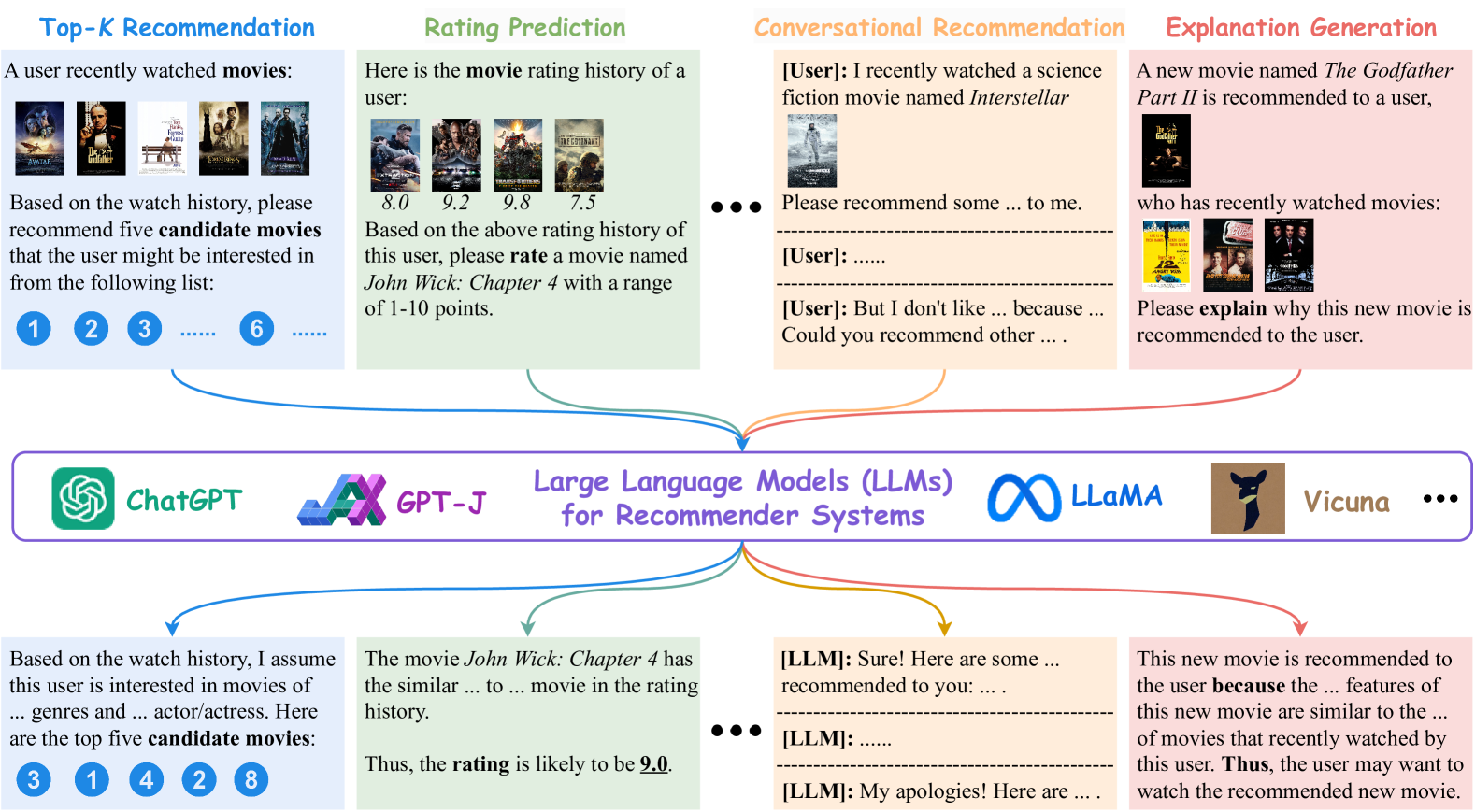
Recommender Systems in the Era of Large Language Models (LLMs)
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, Qing Li
With the prosperity of e-commerce and web applications, Recommender Systems (RecSys) have become an important component of our daily life, providing personalized suggestions that cater to user preferences. While Deep Neural Networks (DNNs) have made significant advancements in enhancing recommender systems by modeling user-item interactions and incorporating textual side information, DNN-based methods still face limitations, such as difficulties in understanding users' interests and capturing textual side information, inabilities in generalizing to various recommendation scenarios and reasoning on their predictions, etc. Meanwhile, the emergence of Large Language Models (LLMs), such as ChatGPT and GPT4, has revolutionized the fields of Natural Language Processing (NLP) and Artificial Intelligence (AI), due to their remarkable abilities in fundamental responsibilities of language understanding and generation, as well as impressive generalization and reasoning capabilities. As a result, recent studies have attempted to harness the power of LLMs to enhance recommender systems. Given the rapid evolution of this research direction in recommender systems, there is a pressing need for a systematic overview that summarizes existing LLM-empowered recommender systems, to provide researchers in relevant fields with an in-depth understanding. Therefore, in this paper, we conduct a comprehensive review of LLM-empowered recommender systems from various aspects including Pre-training, Fine-tuning, and Prompting. More specifically, we first introduce representative methods to harness the power of LLMs (as a feature encoder) for learning representations of users and items. Then, we review recent techniques of LLMs for enhancing recommender systems from three paradigms, namely pre-training, fine-tuning, and prompting. Finally, we comprehensively discuss future directions in this emerging field.
Read more4/23/2024
0
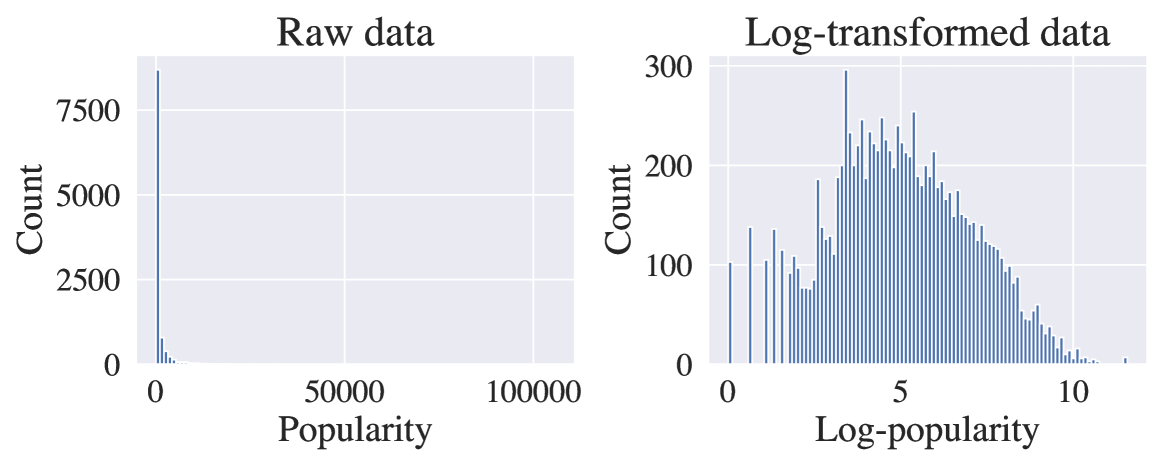
Large Language Models as Recommender Systems: A Study of Popularity Bias
Jan Malte Lichtenberg, Alexander Buchholz, Pola Schwobel
The issue of popularity bias -- where popular items are disproportionately recommended, overshadowing less popular but potentially relevant items -- remains a significant challenge in recommender systems. Recent advancements have seen the integration of general-purpose Large Language Models (LLMs) into the architecture of such systems. This integration raises concerns that it might exacerbate popularity bias, given that the LLM's training data is likely dominated by popular items. However, it simultaneously presents a novel opportunity to address the bias via prompt tuning. Our study explores this dichotomy, examining whether LLMs contribute to or can alleviate popularity bias in recommender systems. We introduce a principled way to measure popularity bias by discussing existing metrics and proposing a novel metric that fulfills a series of desiderata. Based on our new metric, we compare a simple LLM-based recommender to traditional recommender systems on a movie recommendation task. We find that the LLM recommender exhibits less popularity bias, even without any explicit mitigation.
Read more6/4/2024