Can LLM Generate Culturally Relevant Commonsense QA Data? Case Study in Indonesian and Sundanese
2402.17302
0
0

Abstract
Large Language Models (LLMs) are increasingly being used to generate synthetic data for training and evaluating models. However, it is unclear whether they can generate a good quality of question answering (QA) dataset that incorporates knowledge and cultural nuance embedded in a language, especially for low-resource languages. In this study, we investigate the effectiveness of using LLMs in generating culturally relevant commonsense QA datasets for Indonesian and Sundanese languages. To do so, we create datasets for these languages using various methods involving both LLMs and human annotators, resulting in ~4.5K questions per language (~9K in total), making our dataset the largest of its kind. Our experiments show that automatic data adaptation from an existing English dataset is less effective for Sundanese. Interestingly, using the direct generation method on the target language, GPT-4 Turbo can generate questions with adequate general knowledge in both languages, albeit not as culturally 'deep' as humans. We also observe a higher occurrence of fluency errors in the Sundanese dataset, highlighting the discrepancy between medium- and lower-resource languages.
Create account to get full access
Overview
- This paper investigates whether large language models (LLMs) can generate culturally relevant commonsense question-answering (QA) datasets for Indonesian and Sundanese, two major languages in Indonesia.
- The researchers aim to understand the capabilities and limitations of LLMs in producing QA data that aligns with the cultural context and commonsense knowledge of these specific language communities.
- The study compares LLM-generated data with human-authored data to assess the cultural relevance and quality of the generated content.
Plain English Explanation
The researchers in this study wanted to see if large language models (LLMs) - powerful AI systems that can generate human-like text - could create commonsense question-and-answer datasets that are culturally relevant for Indonesian and Sundanese speakers. Commonsense knowledge refers to the everyday, shared understanding that most people have about the world.
The researchers were interested in this because creating high-quality datasets for less-resourced languages can be challenging, and LLMs might be able to help. However, it's unclear if LLMs can generate content that aligns with the specific cultural contexts and shared knowledge of different language communities.
To test this, the researchers compared the QA data generated by LLMs to data created by human experts in Indonesian and Sundanese. They looked at factors like how culturally relevant and accurate the LLM-generated content was compared to the human-authored data. This allows them to understand the capabilities and limitations of using LLMs for this task.
Technical Explanation
The paper explores the ability of large language models (LLMs) to generate culturally relevant commonsense question-answering (QA) datasets for Indonesian and Sundanese, two major languages spoken in Indonesia.
The researchers used the GPT-3 LLM to generate QA pairs based on prompts designed to elicit commonsense knowledge and cultural context. They then compared the LLM-generated data to human-authored QA pairs collected from native speakers, evaluating factors like cultural relevance, accuracy, and coherence.
The results showed that while the LLM-generated data exhibited some cultural relevance, it often lacked the depth and nuance of the human-authored content. The LLM struggled to fully capture the contextual and commonsense knowledge that is deeply embedded in these language communities. The researchers also found issues with factual accuracy and logical coherence in parts of the LLM-generated data.
These findings suggest that while LLMs can be a helpful tool, they may have limitations in generating culturally grounded data for less-resourced languages like Indonesian and Sundanese. Further research is needed to improve the cultural alignment and commonsense reasoning capabilities of these models.
Critical Analysis
The paper provides a valuable case study on the challenges of using LLMs to generate culturally relevant commonsense QA data for under-resourced languages. The researchers acknowledge the limitations of their approach, such as the relatively small size of the human-authored dataset used for comparison.
Additionally, the paper does not delve deeply into potential biases or blind spots in the LLM-generated content. It would be helpful to have a more nuanced discussion of how the model's training data and underlying architecture may influence the cultural relevance and accuracy of the generated output.
Furthermore, the paper could have explored potential mitigation strategies, such as fine-tuning the LLM on more culturally diverse data or incorporating feedback from native speakers into the generation process. Approaches like those used in PerkweCOQA may offer insights for enhancing the cultural alignment of LLM-generated content.
Overall, the paper makes a valuable contribution by highlighting the challenges of using LLMs for culturally specific commonsense reasoning tasks. The findings underscore the need for further research and development to better align these powerful language models with the diverse cultural contexts and shared knowledge of different language communities.
Conclusion
This study provides a thought-provoking case study on the limitations of using large language models (LLMs) to generate culturally relevant commonsense question-answering (QA) data for Indonesian and Sundanese, two major languages in Indonesia.
The researchers found that while the LLM-generated content exhibited some cultural relevance, it often lacked the depth and nuance of human-authored data, struggling to fully capture the contextual and commonsense knowledge embedded in these language communities.
These findings suggest that while LLMs can be a helpful tool, they may have significant limitations in generating culturally grounded data for less-resourced languages. Addressing these limitations will be an important area of future research, as the ability to create high-quality, culturally aligned datasets is crucial for developing effective AI systems for diverse language communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Understanding the Capabilities and Limitations of Large Language Models for Cultural Commonsense
Siqi Shen, Lajanugen Logeswaran, Moontae Lee, Honglak Lee, Soujanya Poria, Rada Mihalcea
0
0
Large language models (LLMs) have demonstrated substantial commonsense understanding through numerous benchmark evaluations. However, their understanding of cultural commonsense remains largely unexamined. In this paper, we conduct a comprehensive examination of the capabilities and limitations of several state-of-the-art LLMs in the context of cultural commonsense tasks. Using several general and cultural commonsense benchmarks, we find that (1) LLMs have a significant discrepancy in performance when tested on culture-specific commonsense knowledge for different cultures; (2) LLMs' general commonsense capability is affected by cultural context; and (3) The language used to query the LLMs can impact their performance on cultural-related tasks. Our study points to the inherent bias in the cultural understanding of LLMs and provides insights that can help develop culturally aware language models.
5/9/2024

GeMQuAD : Generating Multilingual Question Answering Datasets from Large Language Models using Few Shot Learning
Amani Namboori, Shivam Mangale, Andy Rosenbaum, Saleh Soltan
0
0
The emergence of Large Language Models (LLMs) with capabilities like In-Context Learning (ICL) has ushered in new possibilities for data generation across various domains while minimizing the need for extensive data collection and modeling techniques. Researchers have explored ways to use this generated synthetic data to optimize smaller student models for reduced deployment costs and lower latency in downstream tasks. However, ICL-generated data often suffers from low quality as the task specificity is limited with few examples used in ICL. In this paper, we propose GeMQuAD - a semi-supervised learning approach, extending the WeakDAP framework, applied to a dataset generated through ICL with just one example in the target language using AlexaTM 20B Seq2Seq LLM. Through our approach, we iteratively identify high-quality data to enhance model performance, especially for low-resource multilingual setting in the context of Extractive Question Answering task. Our framework outperforms the machine translation-augmented model by 0.22/1.68 F1/EM (Exact Match) points for Hindi and 0.82/1.37 F1/EM points for Spanish on the MLQA dataset, and it surpasses the performance of model trained on an English-only dataset by 5.05/6.50 F1/EM points for Hindi and 3.81/3.69 points F1/EM for Spanish on the same dataset. Notably, our approach uses a pre-trained LLM for generation with no fine-tuning (FT), utilizing just a single annotated example in ICL to generate data, providing a cost-effective development process.
4/16/2024
💬
Exploring Large Language Models for Relevance Judgments in Tetun
Gabriel de Jesus, S'ergio Nunes
0
0
The Cranfield paradigm has served as a foundational approach for developing test collections, with relevance judgments typically conducted by human assessors. However, the emergence of large language models (LLMs) has introduced new possibilities for automating these tasks. This paper explores the feasibility of using LLMs to automate relevance assessments, particularly within the context of low-resource languages. In our study, LLMs are employed to automate relevance judgment tasks, by providing a series of query-document pairs in Tetun as the input text. The models are tasked with assigning relevance scores to each pair, where these scores are then compared to those from human annotators to evaluate the inter-annotator agreement levels. Our investigation reveals results that align closely with those reported in studies of high-resource languages.
6/12/2024
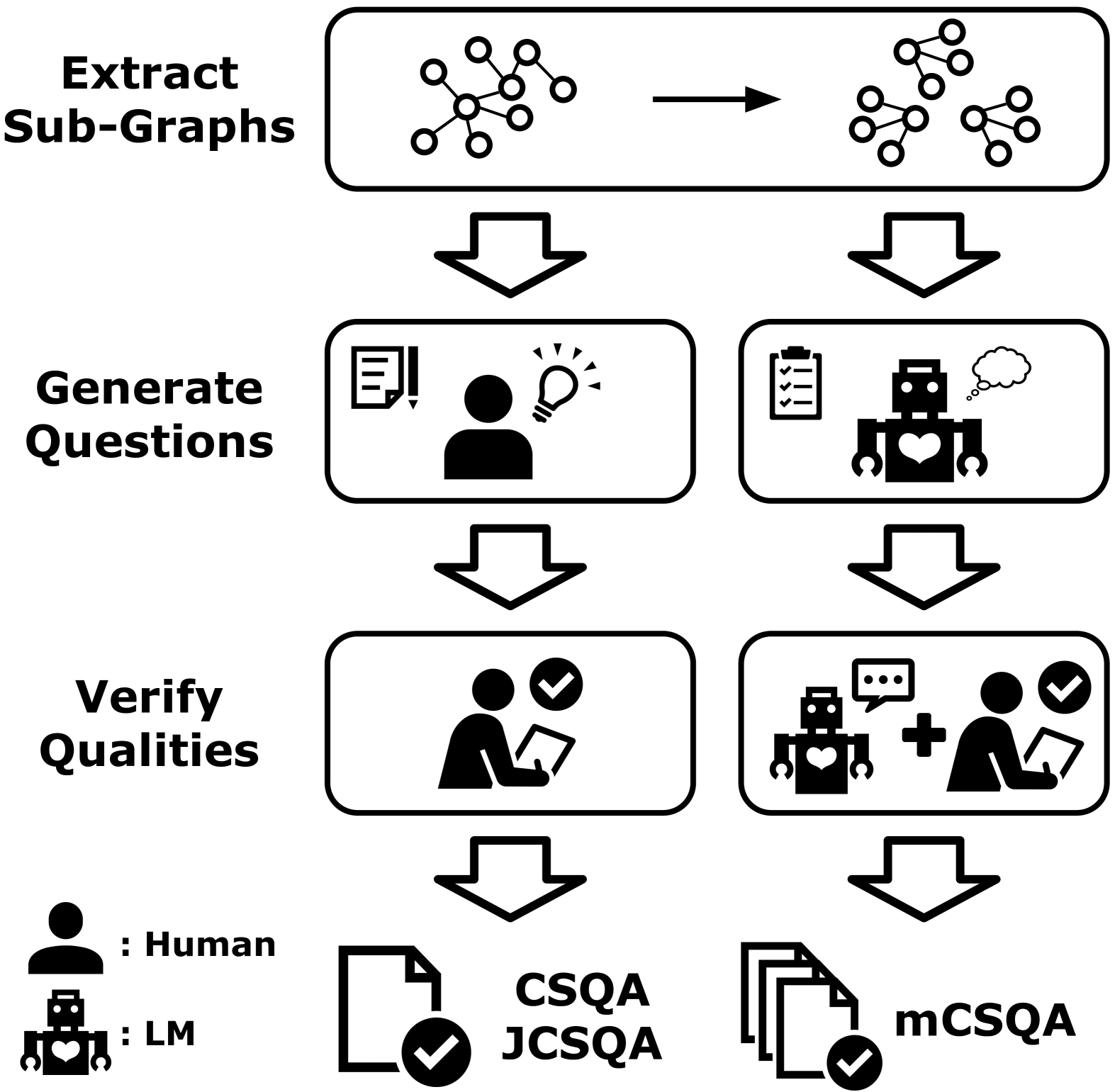
mCSQA: Multilingual Commonsense Reasoning Dataset with Unified Creation Strategy by Language Models and Humans
Yusuke Sakai, Hidetaka Kamigaito, Taro Watanabe
0
0
It is very challenging to curate a dataset for language-specific knowledge and common sense in order to evaluate natural language understanding capabilities of language models. Due to the limitation in the availability of annotators, most current multilingual datasets are created through translation, which cannot evaluate such language-specific aspects. Therefore, we propose Multilingual CommonsenseQA (mCSQA) based on the construction process of CSQA but leveraging language models for a more efficient construction, e.g., by asking LM to generate questions/answers, refine answers and verify QAs followed by reduced human efforts for verification. Constructed dataset is a benchmark for cross-lingual language-transfer capabilities of multilingual LMs, and experimental results showed high language-transfer capabilities for questions that LMs could easily solve, but lower transfer capabilities for questions requiring deep knowledge or commonsense. This highlights the necessity of language-specific datasets for evaluation and training. Finally, our method demonstrated that multilingual LMs could create QA including language-specific knowledge, significantly reducing the dataset creation cost compared to manual creation. The datasets are available at https://huggingface.co/datasets/yusuke1997/mCSQA.
6/7/2024