Understanding is Compression

0

Sign in to get full access
Overview
- This paper explores the idea that "understanding is compression" and its implications for artificial intelligence and machine learning.
- The authors examine the relationship between compression, information theory, and the nature of intelligence.
- They propose that the ability to compress and represent information efficiently is a key characteristic of intelligent systems, including both biological and artificial intelligences.
- The paper covers topics such as the Solomonoff prior, ranking language models by compression, and the entropy law and its connection to data compression and language models.
Plain English Explanation
The paper suggests that the ability to understand and make sense of the world is closely related to the ability to compress information. Just as a good compression algorithm can take a large amount of data and represent it in a more concise way, the authors argue that intelligence, whether in biological or artificial systems, is fundamentally about finding efficient ways to represent and understand the complexity of the world.
Using ideas from information theory and computational learning theory, the authors explore how the "Solomonoff prior" - the idea that simpler explanations are more likely to be true - can be a useful guiding principle for building intelligent systems. They also discuss how we might be able to rank different language models based on their ability to compress information, and how the "entropy law" - the idea that information-rich, complex systems naturally tend towards disorder over time - can help us understand the challenges of building compressed representations of language and other complex phenomena.
The overall message is that by understanding the fundamental connection between intelligence, compression, and information theory, we may be able to make progress on long-standing challenges in artificial intelligence, including building more trustworthy and scrutinizable language models.
Technical Explanation
The paper draws on ideas from information theory, Kolmogorov complexity, and computational learning theory to explore the hypothesis that "understanding is compression." The authors argue that the ability to compress information - to find efficient representations that capture the underlying patterns and regularities in data - is a key aspect of intelligence, both in biological and artificial systems.
They start by introducing the Solomonoff prior, which suggests that simpler explanations are more likely to be true. This implies that intelligent systems should seek to find the most compressed representations of the world that are still consistent with the observed data.
The authors then discuss how we might be able to rank different language models based on their ability to compress information, and how the "entropy law" - the tendency of information-rich, complex systems to naturally become more disordered over time - can help us understand the challenges of building compressed representations of language and other complex phenomena.
The authors also discuss the implications of their ideas for building more trustworthy and scrutinizable language models, as well as the broader significance of the "understanding is compression" hypothesis for the field of artificial intelligence.
Critical Analysis
The authors make a compelling case for the connection between intelligence, compression, and information theory. Their ideas draw on well-established concepts in computer science and mathematics, and they provide a coherent framework for thinking about the nature of understanding and the challenges of building intelligent systems.
However, the paper does not delve deeply into some of the potential limitations or caveats of their approach. For example, it does not address the question of whether compression is the only or the most important aspect of intelligence, or how to resolve potential tensions between compression and other desirable properties like generalization, robustness, or interpretability.
Additionally, the paper could have explored in more depth the practical implications of their ideas for specific AI applications and the challenges of implementing these principles in real-world systems. Further research and experimentation may be needed to fully assess the practical utility and scalability of the "understanding is compression" hypothesis.
Overall, the paper presents a thought-provoking and potentially fruitful perspective on the nature of intelligence and the future of AI. By continuing to explore the connections between compression, information theory, and the foundations of intelligence, researchers may be able to make significant progress in building more capable and trustworthy artificial systems.
Conclusion
This paper presents a novel perspective on the nature of intelligence, proposing that the ability to compress and represent information efficiently is a key characteristic of both biological and artificial intelligence. By drawing on concepts from information theory, Kolmogorov complexity, and computational learning theory, the authors make a compelling case for the "understanding is compression" hypothesis and its implications for the field of AI.
While the paper does not address all the potential limitations and challenges of this approach, it offers a valuable framework for thinking about the fundamental principles underlying intelligent systems. By continuing to explore the connections between compression, information, and the nature of understanding, researchers may be able to make important advances in building more capable, trustworthy, and interpretable artificial intelligence systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Understanding is Compression
Ziguang Li, Chao Huang, Xuliang Wang, Haibo Hu, Cole Wyeth, Dongbo Bu, Quan Yu, Wen Gao, Xingwu Liu, Ming Li
Modern data compression methods are slowly reaching their limits after 80 years of research, millions of papers, and wide range of applications. Yet, the extravagant 6G communication speed requirement raises a major open question for revolutionary new ideas of data compression. We have previously shown all understanding or learning are compression, under reasonable assumptions. Large language models (LLMs) understand data better than ever before. Can they help us to compress data? The LLMs may be seen to approximate the uncomputable Solomonoff induction. Therefore, under this new uncomputable paradigm, we present LMCompress. LMCompress shatters all previous lossless compression algorithms, doubling the lossless compression ratios of JPEG-XL for images, FLAC for audios, and H.264 for videos, and quadrupling the compression ratio of bz2 for texts. The better a large model understands the data, the better LMCompress compresses.
Read more8/22/2024
0
Compression Represents Intelligence Linearly
Yuzhen Huang, Jinghan Zhang, Zifei Shan, Junxian He
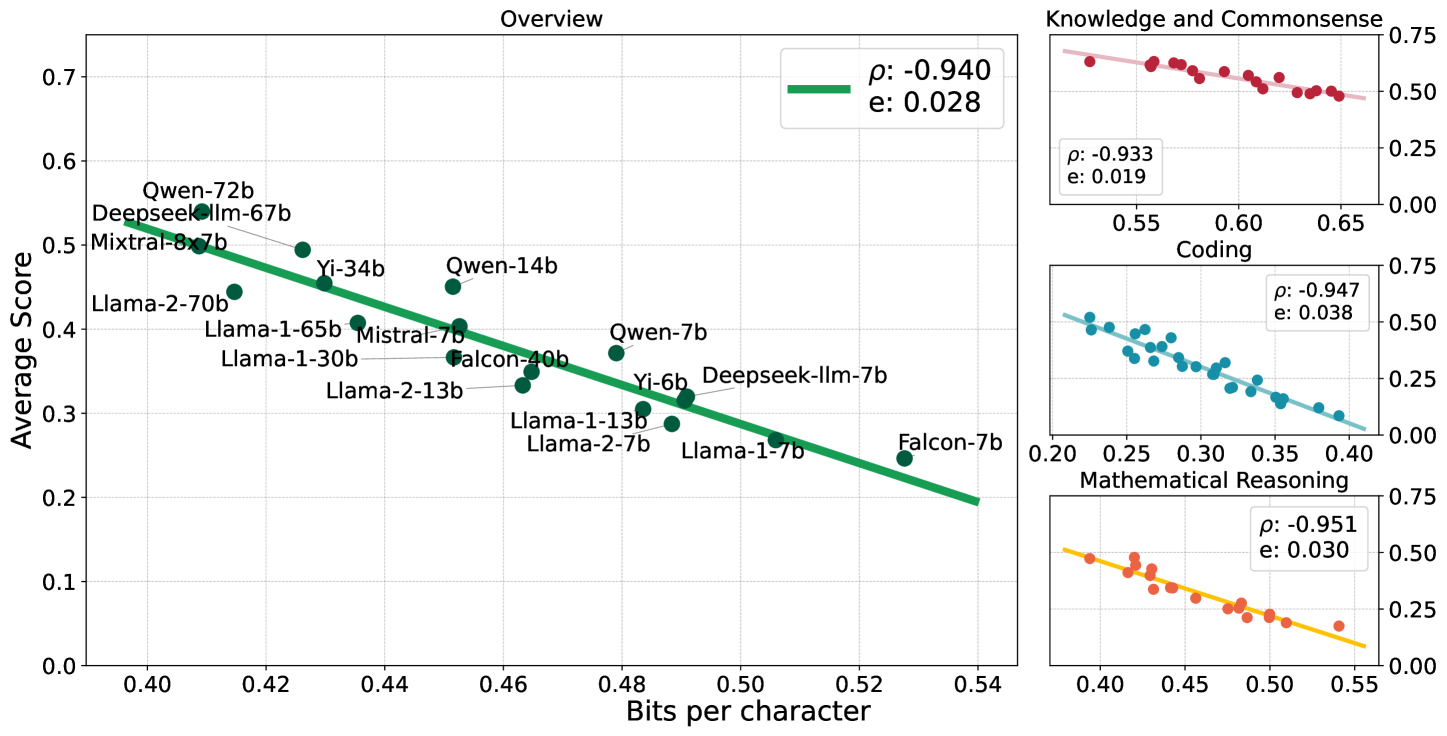
There is a belief that learning to compress well will lead to intelligence. Recently, language modeling has been shown to be equivalent to compression, which offers a compelling rationale for the success of large language models (LLMs): the development of more advanced language models is essentially enhancing compression which facilitates intelligence. Despite such appealing discussions, little empirical evidence is present for the interplay between compression and intelligence. In this work, we examine their relationship in the context of LLMs, treating LLMs as data compressors. Given the abstract concept of intelligence, we adopt the average downstream benchmark scores as a surrogate, specifically targeting intelligence related to knowledge and commonsense, coding, and mathematical reasoning. Across 12 benchmarks, our study brings together 31 public LLMs that originate from diverse organizations. Remarkably, we find that LLMs' intelligence -- reflected by average benchmark scores -- almost linearly correlates with their ability to compress external text corpora. These results provide concrete evidence supporting the belief that superior compression indicates greater intelligence. Furthermore, our findings suggest that compression efficiency, as an unsupervised metric derived from raw text corpora, serves as a reliable evaluation measure that is linearly associated with the model capabilities. We open-source our compression datasets as well as our data collection pipelines to facilitate future researchers to assess compression properly.
Read more8/20/2024
🏷️
0
Ranking LLMs by compression
Peijia Guo, Ziguang Li, Haibo Hu, Chao Huang, Ming Li, Rui Zhang
We conceptualize the process of understanding as information compression, and propose a method for ranking large language models (LLMs) based on lossless data compression. We demonstrate the equivalence of compression length under arithmetic coding with cumulative negative log probabilities when using a large language model as a prior, that is, the pre-training phase of the model is essentially the process of learning the optimal coding length. At the same time, the evaluation metric compression ratio can be obtained without actual compression, which greatly saves overhead. In this paper, we use five large language models as priors for compression, then compare their performance on challenging natural language processing tasks, including sentence completion, question answering, and coreference resolution. Experimental results show that compression ratio and model performance are positively correlated, so it can be used as a general metric to evaluate large language models.
Read more6/21/2024

0
Entropy Law: The Story Behind Data Compression and LLM Performance
Mingjia Yin, Chuhan Wu, Yufei Wang, Hao Wang, Wei Guo, Yasheng Wang, Yong Liu, Ruiming Tang, Defu Lian, Enhong Chen
Data is the cornerstone of large language models (LLMs), but not all data is useful for model learning. Carefully selected data can better elicit the capabilities of LLMs with much less computational overhead. Most methods concentrate on evaluating the quality of individual samples in data selection, while the combinatorial effects among samples are neglected. Even if each sample is of perfect quality, their combinations may be suboptimal in teaching LLMs due to their intrinsic homogeneity or contradiction. In this paper, we aim to uncover the underlying relationships between LLM performance and data selection. Inspired by the information compression nature of LLMs, we uncover an ``entropy law'' that connects LLM performance with data compression ratio and first-epoch training loss, which reflect the information redundancy of a dataset and the mastery of inherent knowledge encoded in this dataset, respectively. Through both theoretical deduction and empirical evaluation, we find that model performance is negatively correlated to the compression ratio of training data, which usually yields a lower training loss. Based on the findings of the entropy law, we propose a quite efficient and universal data selection method named textbf{ZIP} for training LLMs, which aim to prioritize data subsets exhibiting a low compression ratio. Based on a multi-stage algorithm that selects diverse data in a greedy manner, we can obtain a good data subset with satisfactory diversity. Extensive experiments have been conducted to validate the entropy law and the superiority of ZIP across different LLM backbones and alignment stages. We also present an interesting application of entropy law that can detect potential performance risks at the beginning of model training.
Read more7/12/2024