Understanding Reasoning Ability of Language Models From the Perspective of Reasoning Paths Aggregation
2402.03268
0
0
🤔
Abstract
Pre-trained language models (LMs) are able to perform complex reasoning without explicit fine-tuning. To understand how pre-training with a next-token prediction objective contributes to the emergence of such reasoning capability, we propose that we can view an LM as deriving new conclusions by aggregating indirect reasoning paths seen at pre-training time. We found this perspective effective in two important cases of reasoning: logic reasoning with knowledge graphs (KGs) and chain-of-thought (CoT) reasoning. More specifically, we formalize the reasoning paths as random walk paths on the knowledge/reasoning graphs. Analyses of learned LM distributions suggest that a weighted sum of relevant random walk path probabilities is a reasonable way to explain how LMs reason. Experiments and analysis on multiple KG and CoT datasets reveal the effect of training on random walk paths and suggest that augmenting unlabeled random walk reasoning paths can improve real-world multi-step reasoning performance. code: https://github.com/WANGXinyiLinda/LM_random_walk
Create account to get full access
Overview
- Pre-trained language models (LMs) can perform complex reasoning without explicit fine-tuning
- Researchers propose that LMs derive new conclusions by aggregating indirect reasoning paths seen during pre-training
- This perspective is effective in explaining two important cases of reasoning: logic reasoning with knowledge graphs (KGs) and chain-of-thought (CoT) reasoning
Plain English Explanation
Language models (LMs) trained on large amounts of text data have shown the remarkable ability to reason and solve complex problems, even without being explicitly trained on those tasks. Researchers believe that this capability emerges from the way LMs learn to predict the next word in a sequence during pre-training.
The key insight is that LMs may be deriving new conclusions by combining and aggregating the indirect reasoning paths they've encountered in the text data used for pre-training. For example, link to "Distributional Reasoning in LLMs: Parallel Reasoning Processes in Multi-Step Inference" if an LM sees enough examples of "Paris is the capital of France" and "France is in Europe," it can then reason that "Paris is in Europe" without being explicitly trained on that conclusion.
The researchers formalize these reasoning paths as random walk paths on knowledge graphs or reasoning graphs. Their analysis suggests that a weighted sum of the probabilities of these relevant random walk paths can help explain how LMs perform logical reasoning and multi-step reasoning, as seen in link to "Reasoning with Efficient Knowledge Paths: How Knowledge Graph Guides Large Language Models for Multi-hop Inference" and link to "Can Small Language Models Help Large Language Models Reason?".
By understanding this underlying mechanism, the researchers hope to gain insights that can help improve the reasoning capabilities of language models, as explored in link to "Beyond Accuracy: Evaluating Reasoning Behavior of Large Language Models" and link to "The Representational Capacity of Neural Language Models for Chain-of-Thought Reasoning".
Technical Explanation
The researchers propose that we can view a pre-trained language model (LM) as deriving new conclusions by aggregating indirect reasoning paths seen during the pre-training process. They formalize these reasoning paths as random walk paths on knowledge graphs (KGs) or reasoning graphs.
To investigate this perspective, the researchers analyze the learned distributions of LMs and find that a weighted sum of relevant random walk path probabilities can reasonably explain how LMs perform logical reasoning with KGs and chain-of-thought (CoT) reasoning.
In the case of logical reasoning with KGs, the researchers show that the probability of an LM generating a correct answer can be approximated by the weighted sum of the probabilities of relevant random walk paths on the KG. This suggests that LMs are able to leverage the indirect reasoning paths encoded in the pre-training data to perform logical inference.
For CoT reasoning, the researchers find that the probabilities of relevant random walk paths on a reasoning graph can also help explain the LM's step-by-step reasoning process. This indicates that LMs are able to combine multiple reasoning steps seen during pre-training to tackle complex, multi-step problems.
Through experiments and analysis on multiple KG and CoT datasets, the researchers demonstrate the effect of training on random walk paths and suggest that augmenting the pre-training data with additional unlabeled random walk reasoning paths can improve the real-world multi-step reasoning performance of LMs.
Critical Analysis
The researchers provide a compelling perspective on how pre-trained language models are able to perform complex reasoning without explicit fine-tuning. The idea of aggregating indirect reasoning paths seen during pre-training is an intriguing explanation for the emergence of such reasoning capabilities.
However, the researchers acknowledge that their analysis is not a complete or definitive explanation for the reasoning abilities of LMs. There may be other mechanisms or factors at play that are not captured by the random walk path perspective.
Additionally, the researchers note that their experiments primarily focused on specific cases of logical reasoning and chain-of-thought reasoning. It would be valuable to further explore the applicability of this perspective to other types of reasoning and problem-solving tasks.
Another potential limitation is the reliance on the availability and quality of the knowledge graphs and reasoning graphs used in the analysis. The performance of the LMs may be influenced by the coverage and accuracy of the information contained in these graphs, which could vary depending on the domain and data sources used.
Despite these caveats, the researchers' work provides a valuable contribution to our understanding of the inner workings of pre-trained language models. By encouraging critical thinking and further exploration, this research can help advance the field of natural language processing and AI reasoning.
Conclusion
This paper presents a novel perspective on how pre-trained language models (LMs) are able to perform complex reasoning without explicit fine-tuning. The researchers propose that LMs derive new conclusions by aggregating indirect reasoning paths encountered during pre-training, which they formalize as random walk paths on knowledge graphs and reasoning graphs.
Through analyses and experiments, the researchers demonstrate that this perspective can effectively explain the logical reasoning and chain-of-thought reasoning capabilities of LMs. Their findings suggest that augmenting pre-training data with additional unlabeled random walk reasoning paths can improve the real-world multi-step reasoning performance of language models.
While not a complete explanation, this research provides valuable insights into the underlying mechanisms that enable the impressive reasoning abilities of pre-trained language models. By encouraging further exploration and critical analysis, this work contributes to our understanding of the representational capacity and reasoning behavior of large language models, which has important implications for the development of more capable and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Distributional reasoning in LLMs: Parallel reasoning processes in multi-hop reasoning
Yuval Shalev, Amir Feder, Ariel Goldstein
0
0
Large language models (LLMs) have shown an impressive ability to perform tasks believed to require thought processes. When the model does not document an explicit thought process, it becomes difficult to understand the processes occurring within its hidden layers and to determine if these processes can be referred to as reasoning. We introduce a novel and interpretable analysis of internal multi-hop reasoning processes in LLMs. We demonstrate that the prediction process for compositional reasoning questions can be modeled using a simple linear transformation between two semantic category spaces. We show that during inference, the middle layers of the network generate highly interpretable embeddings that represent a set of potential intermediate answers for the multi-hop question. We use statistical analyses to show that a corresponding subset of tokens is activated in the model's output, implying the existence of parallel reasoning paths. These observations hold true even when the model lacks the necessary knowledge to solve the task. Our findings can help uncover the strategies that LLMs use to solve reasoning tasks, offering insights into the types of thought processes that can emerge from artificial intelligence. Finally, we also discuss the implication of cognitive modeling of these results.
6/21/2024
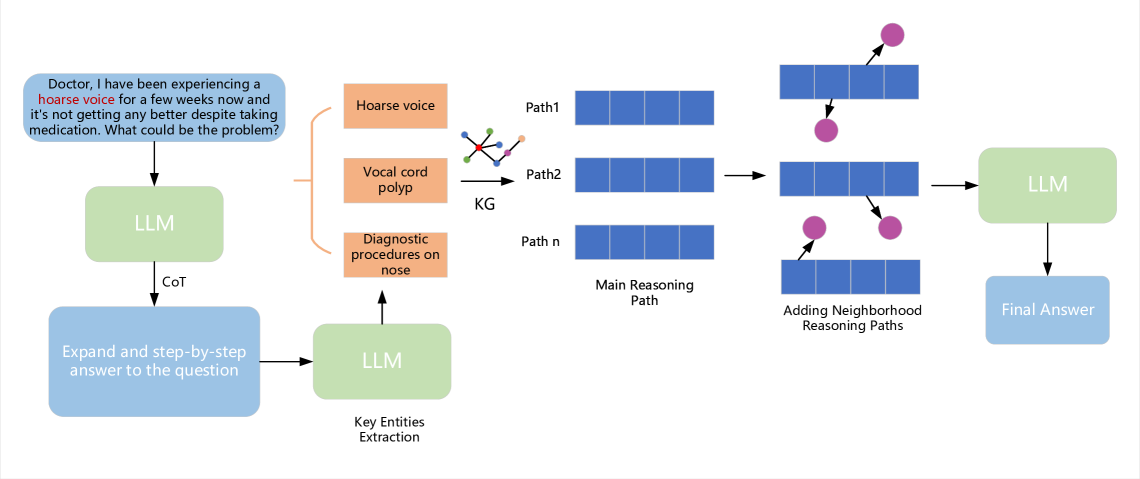
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
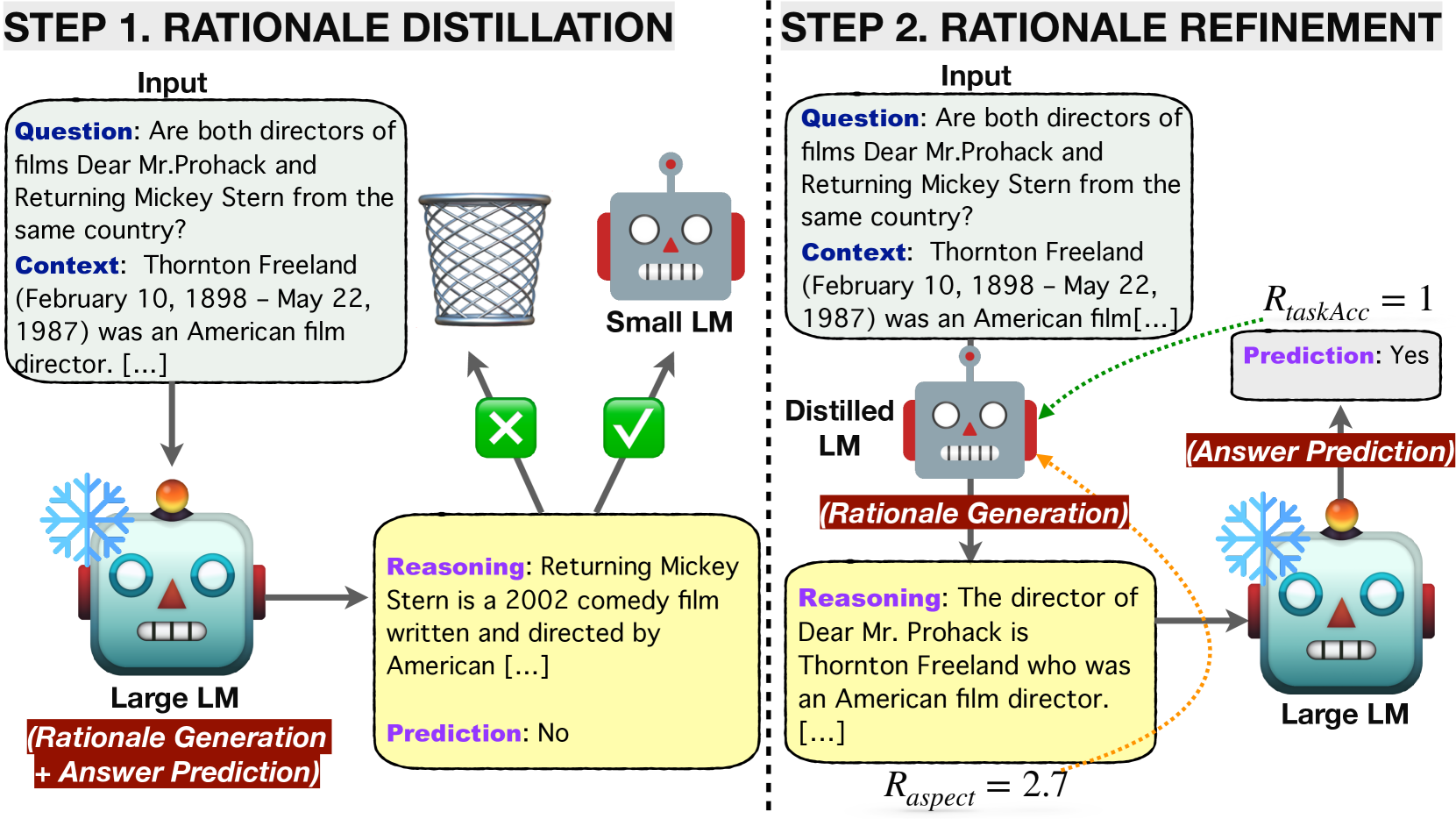
Can Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Jooyoung Lee, Fan Yang, Thanh Tran, Qian Hu, Emre Barut, Kai-Wei Chang, Chengwei Su
0
0
We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., 10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
4/5/2024

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024