Unforgettable Generalization in Language Models

0

Sign in to get full access
Overview
- Examines the problem of forgetting in language models, where models can lose knowledge over time.
- Proposes an "unforgettable" language model that retains knowledge better than standard models.
- Evaluates the model on a range of benchmark tasks to assess its generalization and retention capabilities.
Plain English Explanation
Large language models, the powerful AI systems that can generate human-like text, often suffer from a problem called "forgetting". Over time, as they are trained on new information, they can lose or forget some of their original knowledge and capabilities. This can be a significant issue, as we want these models to maintain and build upon their understanding rather than constantly losing information.
The paper introduces an "unforgettable" language model that is designed to retain knowledge better than standard models. The key idea is to modify the model's training process in a way that helps it remember important information, even as it continues to learn new things. The researchers evaluate this new model on a variety of benchmark tasks, looking at both its ability to generalize to new situations as well as its capacity to retain knowledge over time.
The findings suggest that the unforgettable model is indeed able to hold onto information better than typical language models. This could be an important step in developing AI systems that can continuously learn and expand their knowledge without constantly forgetting what they've already learned. By addressing the forgetting problem, these models may become more reliable, robust, and useful in real-world applications.
Technical Explanation
The paper proposes an "unforgettable" language model that is designed to overcome the issue of forgetting, where models lose knowledge over time as they are trained on new information. The key innovation is a modified training process that helps the model retain important knowledge better than standard language models.
The researchers evaluate their unforgettable model on a range of benchmark tasks, including both generalization to new situations as well as retention of knowledge over time. The results indicate that the unforgettable model is indeed able to hold onto information more effectively compared to typical language models.
Specifically, the paper makes the following technical contributions:
-
Unforgettable Training Process: The authors introduce a new training procedure that encourages the model to retain important knowledge, even as it continues to learn new information. This involves techniques like selective rehearsal of past training data and careful management of the model's internal representations.
-
Benchmark Evaluations: The researchers assess their unforgettable model across a variety of tasks, including language understanding, generation, and knowledge retrieval. This allows them to evaluate both the model's generalization capabilities as well as its ability to retain information over time.
-
Insights and Analysis: The paper provides detailed analysis of the model's performance, shedding light on the factors that contribute to its improved retention of knowledge. The authors also discuss potential limitations and areas for future research.
Overall, this work represents an important step in addressing the forgetting problem in language models, which is a significant challenge in the field of AI. By developing models that can continuously learn and expand their knowledge without constantly forgetting, the researchers aim to create more reliable, robust, and useful AI systems.
Critical Analysis
The paper presents a promising approach to addressing the forgetting problem in language models, but there are a few important caveats and areas for further research:
-
Scalability and Efficiency: While the unforgettable model demonstrates improved retention, it's unclear how the specialized training process would scale to the extremely large language models used in practice. The additional computational and memory requirements could be prohibitive, limiting the model's real-world applicability.
-
Generalization Tradeoffs: The paper focuses on retention of knowledge, but it's possible that the techniques used to prevent forgetting could interfere with a model's ability to generalize to novel situations. Further research is needed to fully understand this potential tradeoff.
-
Interpretability and Explainability: The inner workings of the unforgettable model are complex and not easily interpretable. It would be valuable to gain a deeper understanding of how the model is able to retain knowledge, which could lead to further improvements and insights.
-
Broader Evaluation: The paper evaluates the model on a limited set of benchmark tasks. Assessing its performance on a wider range of real-world applications would provide a more comprehensive understanding of its capabilities and limitations.
Despite these potential concerns, the paper represents an important contribution to the field of language modeling and the challenge of avoiding forgetting. By continuing to explore techniques for building more robust and retentive AI systems, researchers can work towards developing models that are truly unforgettable.
Conclusion
The paper introduces an "unforgettable" language model that is designed to overcome the issue of forgetting, where models lose knowledge over time as they are trained on new information. Through a modified training process, the researchers have developed a model that is able to retain important knowledge more effectively than standard language models.
The key findings from the paper's evaluations suggest that the unforgettable model outperforms typical language models on a range of benchmark tasks, demonstrating both improved generalization capabilities as well as enhanced retention of knowledge over time. This represents an important step forward in addressing a significant challenge in the field of AI, with potential implications for building more reliable, robust, and useful language models.
While the paper identifies some caveats and areas for further research, such as scalability and potential tradeoffs with generalization, the overall contribution is valuable. By continuing to push the boundaries of what language models can achieve, researchers can work towards developing AI systems that can continuously learn and expand their knowledge without constantly forgetting what they've already learned.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unforgettable Generalization in Language Models
Eric Zhang, Leshem Chosen, Jacob Andreas
When language models (LMs) are trained to forget (or unlearn'') a skill, how precisely does their behavior change? We study the behavior of transformer LMs in which tasks have been forgotten via fine-tuning on randomized labels. Such LMs learn to generate near-random predictions for individual examples in the training'' set used for forgetting. Across tasks, however, LMs exhibit extreme variability in whether LM predictions change on examples outside the training set. In some tasks (like entailment classification), forgetting generalizes robustly, and causes models to produce uninformative predictions on new task instances; in other tasks (like physical commonsense reasoning and scientific question answering) forgetting affects only the training examples, and models continue to perform the forgotten'' task accurately even for examples very similar to those that appeared in the training set. Dataset difficulty is not predictive of whether a behavior can be forgotten; instead, generalization in forgetting is (weakly) predicted by the confidence of LMs' initial task predictions and the variability of LM representations of training data, with low confidence and low variability both associated with greater generalization. Perhaps most surprisingly, random-label forgetting appears to be somewhat insensitive to the contents of the training set: for example, models trained on science questions with random labels continue to answer other science questions accurately, but begin to produce random labels on entailment classification tasks. Finally, we show that even generalizable forgetting is shallow: linear probes trained on LMs' representations can still perform tasks reliably after forgetting. Our results highlight the difficulty and unpredictability of performing targeted skill removal from models via fine-tuning.
Read more9/5/2024

0
Demystifying Forgetting in Language Model Fine-Tuning with Statistical Analysis of Example Associations
Xisen Jin, Xiang Ren
Language models (LMs) are known to suffer from forgetting of previously learned examples when fine-tuned, breaking stability of deployed LM systems. Despite efforts on mitigating forgetting, few have investigated whether, and how forgotten upstream examples are associated with newly learned tasks. Insights on such associations enable efficient and targeted mitigation of forgetting. In this paper, we empirically analyze forgetting that occurs in $N$ upstream examples while the model learns $M$ new tasks and visualize their associations with a $M times N$ matrix. We empirically demonstrate that the degree of forgetting can often be approximated by simple multiplicative contributions of the upstream examples and newly learned tasks. We also reveal more complicated patterns where specific subsets of examples are forgotten with statistics and visualization. Following our analysis, we predict forgetting that happens on upstream examples when learning a new task with matrix completion over the empirical associations, outperforming prior approaches that rely on trainable LMs. Project website: https://inklab.usc.edu/lm-forgetting-prediction/
Read more6/21/2024
0
Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
Antonis Antoniades, Xinyi Wang, Yanai Elazar, Alfonso Amayuelas, Alon Albalak, Kexun Zhang, William Yang Wang
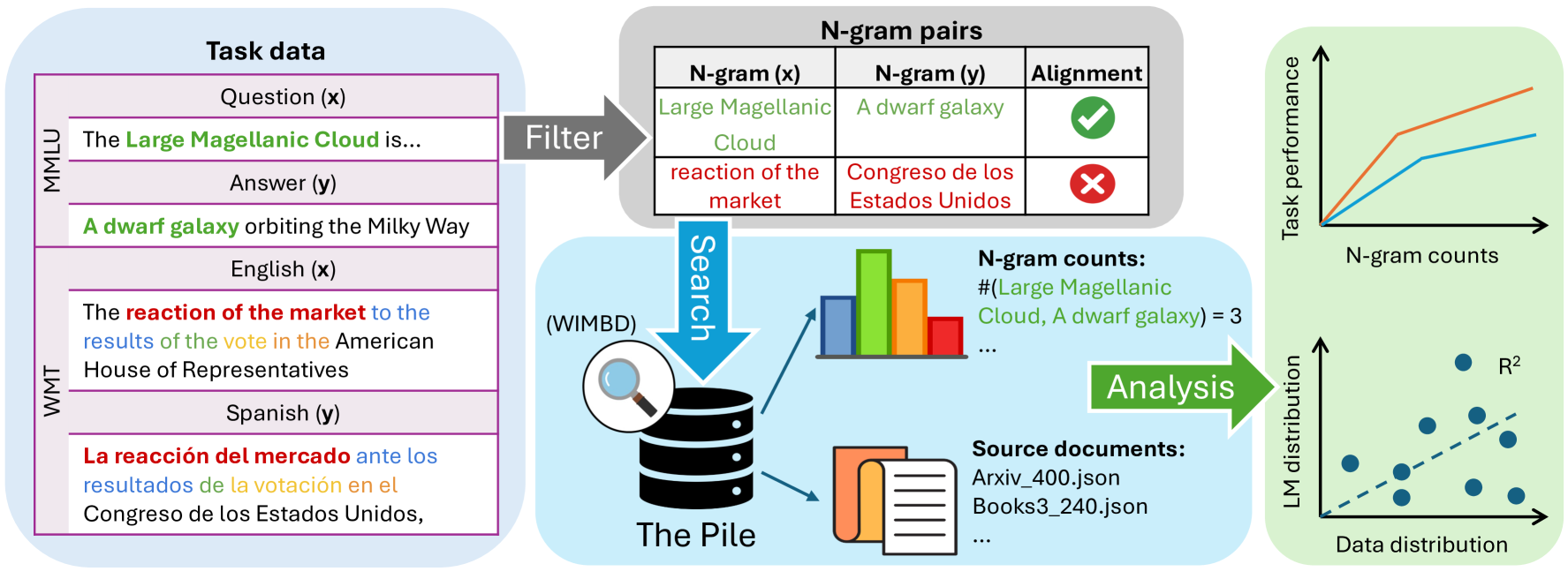
Despite the proven utility of large language models (LLMs) in real-world applications, there remains a lack of understanding regarding how they leverage their large-scale pretraining text corpora to achieve such capabilities. In this work, we investigate the interplay between generalization and memorization in pretrained LLMs at scale, through a comprehensive $n$-gram analysis of their training data. Our experiments focus on three general task types: translation, question-answering, and multiple-choice reasoning. With various sizes of open-source LLMs and their pretraining corpora, we observe that as the model size increases, the task-relevant $n$-gram pair data becomes increasingly important, leading to improved task performance, decreased memorization, stronger generalization, and emergent abilities. Our results support the hypothesis that LLMs' capabilities emerge from a delicate balance of memorization and generalization with sufficient task-related pretraining data, and point the way to larger-scale analyses that could further improve our understanding of these models.
Read more7/23/2024
0
Digital Forgetting in Large Language Models: A Survey of Unlearning Methods
Alberto Blanco-Justicia, Najeeb Jebreel, Benet Manzanares, David S'anchez, Josep Domingo-Ferrer, Guillem Collell, Kuan Eeik Tan
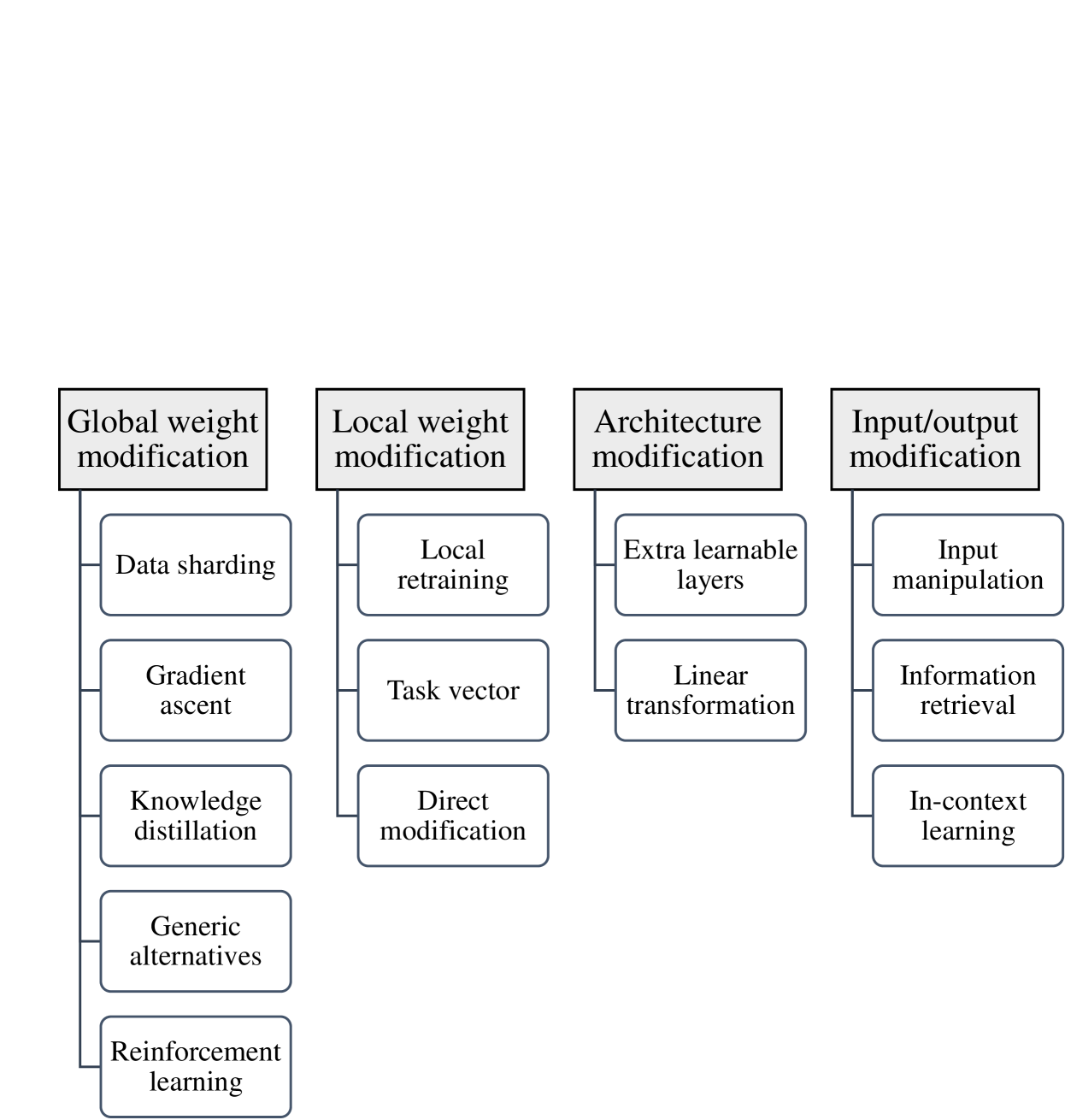
The objective of digital forgetting is, given a model with undesirable knowledge or behavior, obtain a new model where the detected issues are no longer present. The motivations for forgetting include privacy protection, copyright protection, elimination of biases and discrimination, and prevention of harmful content generation. Effective digital forgetting has to be effective (meaning how well the new model has forgotten the undesired knowledge/behavior), retain the performance of the original model on the desirable tasks, and be scalable (in particular forgetting has to be more efficient than retraining from scratch on just the tasks/data to be retained). This survey focuses on forgetting in large language models (LLMs). We first provide background on LLMs, including their components, the types of LLMs, and their usual training pipeline. Second, we describe the motivations, types, and desired properties of digital forgetting. Third, we introduce the approaches to digital forgetting in LLMs, among which unlearning methodologies stand out as the state of the art. Fourth, we provide a detailed taxonomy of machine unlearning methods for LLMs, and we survey and compare current approaches. Fifth, we detail datasets, models and metrics used for the evaluation of forgetting, retaining and runtime. Sixth, we discuss challenges in the area. Finally, we provide some concluding remarks.
Read more4/3/2024