SciAssess: Benchmarking LLM Proficiency in Scientific Literature Analysis
2403.01976
0
0
Abstract
Recent breakthroughs in Large Language Models (LLMs) have revolutionized natural language understanding and generation, sparking significant interest in applying them to scientific literature analysis. However, existing benchmarks fail to adequately evaluate the proficiency of LLMs in this domain, particularly in scenarios requiring higher-level abilities beyond mere memorization and the handling of multimodal data. In response to this gap, we introduce SciAssess, a benchmark specifically designed for the comprehensive evaluation of LLMs in scientific literature analysis. SciAssess aims to thoroughly assess the efficacy of LLMs by focusing on their capabilities in Memorization (L1), Comprehension (L2), and Analysis & Reasoning (L3). It encompasses a variety of tasks drawn from diverse scientific fields, including fundamental science, alloy materials, biomedicine, drug discovery, and organic materials. To ensure the reliability of SciAssess, rigorous quality control measures have been implemented, ensuring accuracy, anonymization, and compliance with copyright standards. SciAssess evaluates 11 LLMs, including GPT, Claude, and Gemini, highlighting their strengths and areas for improvement. This evaluation supports the ongoing development of LLM applications in the analysis of scientific literature. SciAssess and its resources are available at url{https://sci-assess.github.io/}.
Create account to get full access
Overview
- This paper proposes a new benchmark dataset called SciAssess to evaluate the proficiency of large language models (LLMs) in analyzing scientific literature.
- SciAssess includes a variety of tasks that assess an LLM's ability to understand and reason about scientific concepts, experimental design, and research findings.
- The goal is to provide a standardized way to measure and compare the scientific analysis capabilities of different LLMs.
Plain English Explanation
The paper introduces a new dataset called SciAssess that is designed to test how well large language models (LLMs) can analyze and understand scientific literature. LLMs are powerful AI systems that can process and generate human-like text, and they are increasingly being used in scientific applications. However, it's not clear how well they can truly comprehend and reason about complex scientific concepts and research.
SciAssess includes a variety of tasks that assess an LLM's ability to do things like explain scientific concepts in simple terms, analyze experimental designs and interpret results, and demonstrate an understanding of scientific hierarchies and relationships. By providing a standardized way to evaluate these capabilities, the researchers hope to enable better comparisons between different LLMs and identify areas where they excel or fall short.
Technical Explanation
The SciAssess benchmark dataset is designed to assess the proficiency of LLMs in analyzing scientific literature across a range of tasks. The dataset includes scientific articles from various domains, along with associated questions and prompts that evaluate different aspects of an LLM's understanding.
The tasks in SciAssess are organized into an "Ability Assessment Framework" that covers three main categories: Conceptual Understanding, Experimental Design and Interpretation, and Scientific Reasoning. Within each category, there are specific sub-tasks that test an LLM's ability to perform relevant scientific analysis and reasoning.
For example, the Conceptual Understanding tasks might ask an LLM to explain a scientific concept in simple terms, while the Experimental Design tasks could require the LLM to analyze the methodology and interpret the results of a study. The Scientific Reasoning tasks might assess an LLM's ability to understand hierarchical relationships within a scientific domain or generalize insights across different contexts.
By using this standardized benchmark, the researchers aim to provide a comprehensive way to evaluate and compare the scientific analysis capabilities of different LLMs.
Critical Analysis
The SciAssess benchmark represents a valuable contribution to the field of scientific natural language processing, as it addresses an important gap in the evaluation of LLMs' proficiency in this domain. However, the paper does acknowledge some potential limitations and areas for further research.
One key limitation is the scope of the dataset - while it covers a range of scientific domains, it may not capture the full breadth and complexity of scientific literature. Additionally, the paper notes that the tasks in SciAssess are primarily focused on assessing an LLM's understanding and reasoning, but do not directly address the model's ability to generate or summarize scientific content.
The researchers also highlight the need for further exploration of how LLMs' performance on SciAssess tasks relates to their real-world scientific capabilities and potential applications. Validating the benchmark's relevance and predictive power will be an important area of future research.
Conclusion
The SciAssess benchmark represents a significant step forward in the assessment of LLMs' proficiency in scientific literature analysis. By providing a standardized and comprehensive evaluation framework, the researchers aim to enable more rigorous comparisons between different LLMs and identify their strengths and weaknesses in this critical domain.
As LLMs continue to be applied in scientific research and decision-making, tools like SciAssess will become increasingly important for ensuring the reliability and trustworthiness of these systems. The insights gleaned from this benchmark can inform the development of more capable and scientifically-grounded LLMs, ultimately supporting the advancement of scientific knowledge and discovery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SciKnowEval: Evaluating Multi-level Scientific Knowledge of Large Language Models
Kehua Feng, Keyan Ding, Weijie Wang, Xiang Zhuang, Zeyuan Wang, Ming Qin, Yu Zhao, Jianhua Yao, Qiang Zhang, Huajun Chen
0
0
The burgeoning utilization of Large Language Models (LLMs) in scientific research necessitates advanced benchmarks capable of evaluating their understanding and application of scientific knowledge comprehensively. To address this need, we introduce the SciKnowEval benchmark, a novel framework that systematically evaluates LLMs across five progressive levels of scientific knowledge: studying extensively, inquiring earnestly, thinking profoundly, discerning clearly, and practicing assiduously. These levels aim to assess the breadth and depth of scientific knowledge in LLMs, including knowledge coverage, inquiry and exploration capabilities, reflection and reasoning abilities, ethic and safety considerations, as well as practice proficiency. Specifically, we take biology and chemistry as the two instances of SciKnowEval and construct a dataset encompassing 50K multi-level scientific problems and solutions. By leveraging this dataset, we benchmark 20 leading open-source and proprietary LLMs using zero-shot and few-shot prompting strategies. The results reveal that despite achieving state-of-the-art performance, the proprietary LLMs still have considerable room for improvement, particularly in addressing scientific computations and applications. We anticipate that SciKnowEval will establish a comprehensive standard for benchmarking LLMs in science research and discovery, and promote the development of LLMs that integrate scientific knowledge with strong safety awareness. The dataset and code are publicly available at https://github.com/hicai-zju/sciknoweval .
6/14/2024
💬
New!SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R. Loomba, Shichang Zhang, Yizhou Sun, Wei Wang
0
0
Most of the existing Large Language Model (LLM) benchmarks on scientific problem reasoning focus on problems grounded in high-school subjects and are confined to elementary algebraic operations. To systematically examine the reasoning capabilities required for solving complex scientific problems, we introduce an expansive benchmark suite SciBench for LLMs. SciBench contains a carefully curated dataset featuring a range of collegiate-level scientific problems from mathematics, chemistry, and physics domains. Based on the dataset, we conduct an in-depth benchmarking study of representative open-source and proprietary LLMs with various prompting strategies. The results reveal that the current LLMs fall short of delivering satisfactory performance, with the best overall score of merely 43.22%. Furthermore, through a detailed user study, we categorize the errors made by LLMs into ten problem-solving abilities. Our analysis indicates that no single prompting strategy significantly outperforms the others and some strategies that demonstrate improvements in certain problem-solving skills could result in declines in other skills. We envision that SciBench will catalyze further developments in the reasoning abilities of LLMs, thereby ultimately contributing to scientific research and discovery.
7/1/2024

SciEx: Benchmarking Large Language Models on Scientific Exams with Human Expert Grading and Automatic Grading
Tu Anh Dinh, Carlos Mullov, Leonard Barmann, Zhaolin Li, Danni Liu, Simon Rei{ss}, Jueun Lee, Nathan Lerzer, Fabian Ternava, Jianfeng Gao, Alexander Waibel, Tamim Asfour, Michael Beigl, Rainer Stiefelhagen, Carsten Dachsbacher, Klemens Bohm, Jan Niehues
0
0
With the rapid development of Large Language Models (LLMs), it is crucial to have benchmarks which can evaluate the ability of LLMs on different domains. One common use of LLMs is performing tasks on scientific topics, such as writing algorithms, querying databases or giving mathematical proofs. Inspired by the way university students are evaluated on such tasks, in this paper, we propose SciEx - a benchmark consisting of university computer science exam questions, to evaluate LLMs ability on solving scientific tasks. SciEx is (1) multilingual, containing both English and German exams, and (2) multi-modal, containing questions that involve images, and (3) contains various types of freeform questions with different difficulty levels, due to the nature of university exams. We evaluate the performance of various state-of-the-art LLMs on our new benchmark. Since SciEx questions are freeform, it is not straightforward to evaluate LLM performance. Therefore, we provide human expert grading of the LLM outputs on SciEx. We show that the free-form exams in SciEx remain challenging for the current LLMs, where the best LLM only achieves 59.4% exam grade on average. We also provide detailed comparisons between LLM performance and student performance on SciEx. To enable future evaluation of new LLMs, we propose using LLM-as-a-judge to grade the LLM answers on SciEx. Our experiments show that, although they do not perform perfectly on solving the exams, LLMs are decent as graders, achieving 0.948 Pearson correlation with expert grading.
6/18/2024
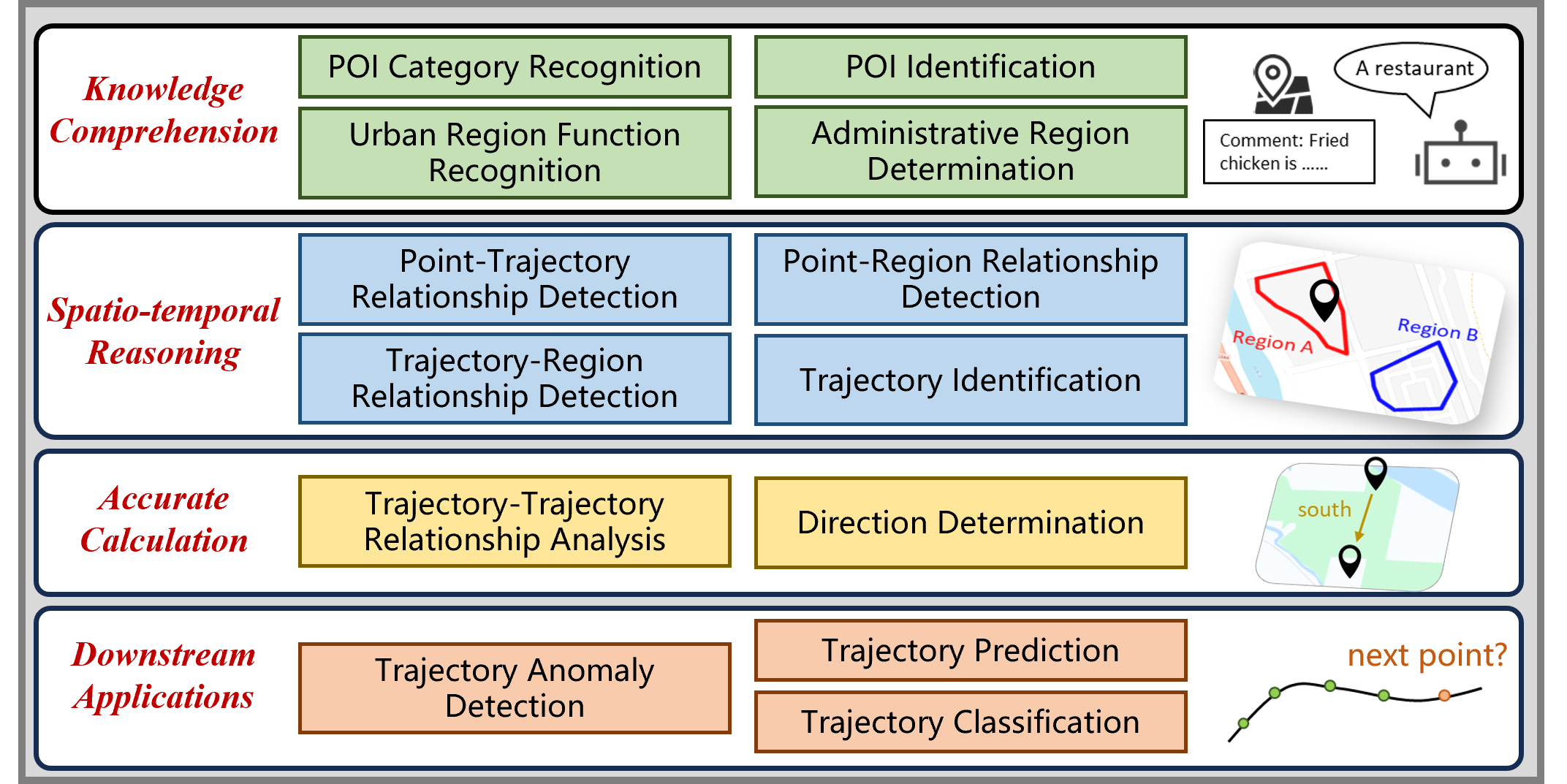
STBench: Assessing the Ability of Large Language Models in Spatio-Temporal Analysis
Wenbin Li, Di Yao, Ruibo Zhao, Wenjie Chen, Zijie Xu, Chengxue Luo, Chang Gong, Quanliang Jing, Haining Tan, Jingping Bi
0
0
The rapid evolution of large language models (LLMs) holds promise for reforming the methodology of spatio-temporal data mining. However, current works for evaluating the spatio-temporal understanding capability of LLMs are somewhat limited and biased. These works either fail to incorporate the latest language models or only focus on assessing the memorized spatio-temporal knowledge. To address this gap, this paper dissects LLMs' capability of spatio-temporal data into four distinct dimensions: knowledge comprehension, spatio-temporal reasoning, accurate computation, and downstream applications. We curate several natural language question-answer tasks for each category and build the benchmark dataset, namely STBench, containing 13 distinct tasks and over 60,000 QA pairs. Moreover, we have assessed the capabilities of 13 LLMs, such as GPT-4o, Gemma and Mistral. Experimental results reveal that existing LLMs show remarkable performance on knowledge comprehension and spatio-temporal reasoning tasks, with potential for further enhancement on other tasks through in-context learning, chain-of-though prompting, and fine-tuning. The code and datasets of STBench are released on https://github.com/LwbXc/STBench.
6/28/2024