A Unified Hallucination Mitigation Framework for Large Vision-Language Models

0

Sign in to get full access
Overview
- This paper presents a unified framework for mitigating hallucination in large vision-language models.
- Hallucination refers to the models generating nonsensical or factually incorrect outputs.
- The framework aims to detect and mitigate hallucination across multiple tasks and modalities.
Plain English Explanation
Large vision-language models, which can process both text and images, have become incredibly powerful. However, these models can sometimes generate outputs that are completely made up or incorrect, a problem known as "hallucination." This paper introduces a unified framework to detect and prevent this hallucination across different tasks and types of data.
The key idea is to train the model to be more cautious and only produce outputs that it is highly confident about. This is done through a combination of techniques, including:
- Rejection sampling: The model learns to identify when it is unsure about an output and rejects producing it.
- Calibration: The model's confidence scores are adjusted to better reflect its actual uncertainty.
- Contrastive learning: The model is trained to differentiate between real and hallucinated outputs.
By implementing these methods, the framework aims to make large vision-language models more reliable and trustworthy, reducing the risk of them generating nonsensical or factually incorrect information.
Technical Explanation
The paper introduces a unified framework for mitigating hallucination in large vision-language models. Hallucination refers to the models generating outputs that are nonsensical or factually incorrect.
The key components of the framework are:
-
Rejection Sampling: The model learns to identify when it is uncertain about an output and rejects producing it. This is accomplished by training the model to predict its own confidence score and only generate an output if the score exceeds a certain threshold.
-
Calibration: The model's confidence scores are adjusted to better reflect its actual uncertainty. This helps ensure that the model's self-assessed confidence aligns with its true capabilities.
-
Contrastive Learning: The model is trained to differentiate between real and hallucinated outputs. This helps the model learn the characteristics of hallucinated outputs so it can better detect and avoid them.
The framework is evaluated on a variety of vision-language tasks, including image captioning, visual question answering, and multimodal classification. The results demonstrate that the proposed techniques are effective at mitigating hallucination across these different applications.
Critical Analysis
The paper presents a comprehensive and well-designed framework for addressing the hallucination problem in large vision-language models. The authors have thoughtfully combined several techniques, including rejection sampling, calibration, and contrastive learning, to create a unified approach.
One potential limitation is that the framework may not be as effective for all types of hallucination. The authors acknowledge that their focus is on "semantic" hallucination, where the model generates factually incorrect outputs, but there may be other forms of hallucination (e.g., perceptual hallucination) that require different mitigation strategies.
Additionally, the framework relies on the model's ability to accurately assess its own confidence, which could be challenging in certain scenarios. Further research may be needed to explore the robustness of the confidence estimation process.
Overall, this paper presents a significant step forward in addressing the critical issue of hallucination in large vision-language models. The unified framework provides a promising approach that could help improve the reliability and trustworthiness of these powerful AI systems.
Conclusion
This paper introduces a comprehensive framework for mitigating hallucination in large vision-language models. By combining techniques such as rejection sampling, calibration, and contrastive learning, the framework aims to make these models more reliable and trustworthy, reducing the risk of them generating nonsensical or factually incorrect outputs.
The evaluation results demonstrate the effectiveness of the proposed approach across a variety of vision-language tasks. While the framework has some limitations, it represents an important advancement in addressing the hallucination problem, which is a critical challenge for the widespread deployment of large AI models. The insights and techniques presented in this paper could have a significant impact on the development of more robust and reliable vision-language systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Unified Hallucination Mitigation Framework for Large Vision-Language Models
Yue Chang, Liqiang Jing, Xiaopeng Zhang, Yue Zhang
Hallucination is a common problem for Large Vision-Language Models (LVLMs) with long generations which is difficult to eradicate. The generation with hallucinations is partially inconsistent with the image content. To mitigate hallucination, current studies either focus on the process of model inference or the results of model generation, but the solutions they design sometimes do not deal appropriately with various types of queries and the hallucinations of the generations about these queries. To accurately deal with various hallucinations, we present a unified framework, Dentist, for hallucination mitigation. The core step is to first classify the queries, then perform different processes of hallucination mitigation based on the classification result, just like a dentist first observes the teeth and then makes a plan. In a simple deployment, Dentist can classify queries as perception or reasoning and easily mitigate potential hallucinations in answers which has been demonstrated in our experiments. On MMbench, we achieve a 13.44%/10.2%/15.8% improvement in accuracy on Image Quality, a Coarse Perception visual question answering (VQA) task, over the baseline InstructBLIP/LLaVA/VisualGLM.
Read more9/26/2024

0
Mitigating Multilingual Hallucination in Large Vision-Language Models
Xiaoye Qu, Mingyang Song, Wei Wei, Jianfeng Dong, Yu Cheng
While Large Vision-Language Models (LVLMs) have exhibited remarkable capabilities across a wide range of tasks, they suffer from hallucination problems, where models generate plausible yet incorrect answers given the input image-query pair. This hallucination phenomenon is even more severe when querying the image in non-English languages, while existing methods for mitigating hallucinations in LVLMs only consider the English scenarios. In this paper, we make the first attempt to mitigate this important multilingual hallucination in LVLMs. With thorough experiment analysis, we found that multilingual hallucination in LVLMs is a systemic problem that could arise from deficiencies in multilingual capabilities or inadequate multimodal abilities. To this end, we propose a two-stage Multilingual Hallucination Removal (MHR) framework for LVLMs, aiming to improve resistance to hallucination for both high-resource and low-resource languages. Instead of relying on the intricate manual annotations of multilingual resources, we fully leverage the inherent capabilities of the LVLM and propose a novel cross-lingual alignment method, which generates multiple responses for each image-query input and then identifies the hallucination-aware pairs for each language. These data pairs are finally used for direct preference optimization to prompt the LVLMs to favor non-hallucinating responses. Experimental results show that our MHR achieves a substantial reduction in hallucination generation for LVLMs. Notably, on our extended multilingual POPE benchmark, our framework delivers an average increase of 19.0% in accuracy across 13 different languages. Our code and model weights are available at https://github.com/ssmisya/MHR
Read more8/2/2024

0
A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
Read more5/7/2024
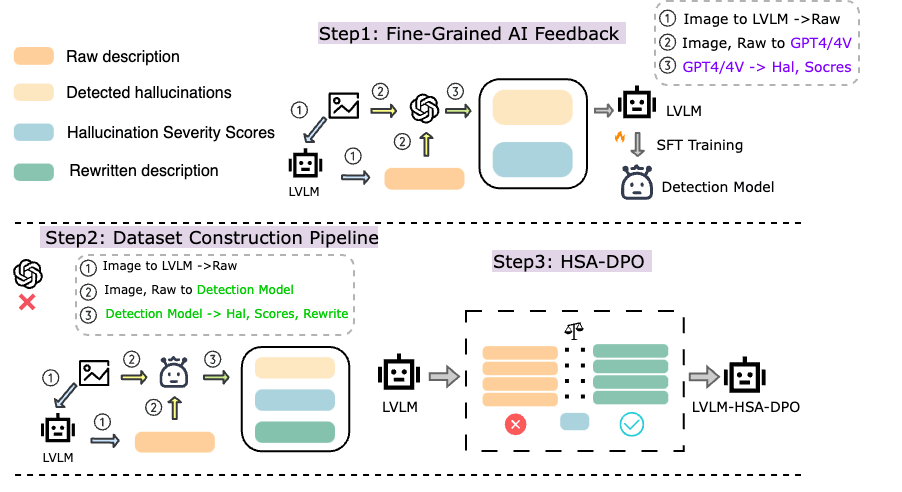
0
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Wenyi Xiao, Ziwei Huang, Leilei Gan, Wanggui He, Haoyuan Li, Zhelun Yu, Hao Jiang, Fei Wu, Linchao Zhu
The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
Read more4/23/2024