External Prompt Features Enhanced Parameter-efficient Fine-tuning for Salient Object Detection

0
🔎
Sign in to get full access
Overview
- Salient object detection (SOD) aims to identify the most visually prominent objects in an image.
- Transformer-based models have shown promising performance in SOD due to their ability to capture global semantic understanding.
- However, these transformer models tend to be large and require a significant number of training parameters.
- To address this, the researchers propose a novel parameter-efficient fine-tuning method called ExPert, which aims to reduce the number of training parameters while enhancing salient object detection capabilities.
Plain English Explanation
The researchers are working on a problem called salient object detection (SOD), which is about finding the most important or noticeable objects in an image. Transformer-based models, which are a type of machine learning model, have done well at this task because they can understand the overall meaning and context of an image. However, these transformer models tend to be large and require a lot of training data, which can make them difficult to use in practice.
To address this, the researchers have developed a new method called ExPert. This method uses a special type of architecture with "adapter" and "injector" modules that can adapt a pre-trained transformer model to work better for SOD, while also using some extra information to help the model identify salient objects more accurately. The key idea is to make the model more efficient and effective at SOD without needing as much training data or computational power.
Technical Explanation
The proposed ExPert model features an encoder-decoder structure with adapter and injector modules interspersed between the layers of a frozen transformer encoder. The adapter modules adapt the pre-trained backbone to the SOD task, while the injector modules incorporate external prompt features to enhance the model's awareness of salient objects.
This approach allows the researchers to fine-tune the model for SOD using a relatively small number of parameters, compared to training a transformer model from scratch. The experiments demonstrate that ExPert outperforms previous state-of-the-art transformer-based and CNN-based models on several SOD datasets, achieving a mean absolute error of 0.215 on the ECSSD dataset with only 80.2M trained parameters.
Critical Analysis
The researchers acknowledge that their ExPert model still relies on a pre-trained transformer encoder, which may limit its flexibility and adaptability to different tasks. Additionally, the paper does not provide a detailed analysis of the computational efficiency of the model compared to other approaches.
One potential area for further research could be exploring the use of more efficient transformer architectures, such as VST or VSCODE, to further reduce the model size and inference time without sacrificing performance.
Additionally, the researchers could investigate the potential of unsupervised or self-supervised learning techniques, as seen in Unified Unsupervised Salient Object Detection, to enhance the model's ability to generalize to a wider range of salient object detection scenarios.
Conclusion
The ExPert model proposed in this paper demonstrates a novel approach to improving the efficiency and performance of transformer-based salient object detection. By incorporating adapter and injector modules, the researchers have been able to fine-tune a pre-trained transformer model with significantly fewer parameters, while still achieving state-of-the-art results on several benchmark datasets.
This work highlights the potential of parameter-efficient fine-tuning techniques to unlock the power of large, pre-trained models for specific tasks, such as salient object detection. As the field of computer vision continues to evolve, innovations like ExPert may pave the way for more accessible and practical applications of advanced deep learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
External Prompt Features Enhanced Parameter-efficient Fine-tuning for Salient Object Detection
Wen Liang, Peipei Ran, Mengchao Bai, Xiao Liu, P. Bilha Githinji, Wei Zhao, Peiwu Qin
Salient object detection (SOD) aims at finding the most salient objects in images and outputs pixel-level binary masks. Transformer-based methods achieve promising performance due to their global semantic understanding, crucial for identifying salient objects. However, these models tend to be large and require numerous training parameters. To better harness the potential of transformers for SOD, we propose a novel parameter-efficient fine-tuning method aimed at reducing the number of training parameters while enhancing the salient object detection capability. Our model, termed EXternal Prompt features Enhanced adapteR Tuning (ExPert), features an encoder-decoder structure with adapters and injectors interspersed between the layers of a frozen transformer encoder. The adapter modules adapt the pretrained backbone to SOD while the injector modules incorporate external prompt features to enhance the awareness of salient objects. Comprehensive experiments demonstrate the superiority of our method. Surpassing former state-of-the-art (SOTA) models across five SOD datasets, ExPert achieves 0.215 mean absolute error (MAE) in the ECSSD dataset with 80.2M trained parameters, 21% better than SelfReformer and 47% better than EGNet.
Read more8/27/2024

0
Modality Prompts for Arbitrary Modality Salient Object Detection
Nianchang Huang, Yang Yang, Qiang Zhang, Jungong Han, Jin Huang
This paper delves into the task of arbitrary modality salient object detection (AM SOD), aiming to detect salient objects from arbitrary modalities, eg RGB images, RGB-D images, and RGB-D-T images. A novel modality-adaptive Transformer (MAT) will be proposed to investigate two fundamental challenges of AM SOD, ie more diverse modality discrepancies caused by varying modality types that need to be processed, and dynamic fusion design caused by an uncertain number of modalities present in the inputs of multimodal fusion strategy. Specifically, inspired by prompt learning's ability of aligning the distributions of pre-trained models to the characteristic of downstream tasks by learning some prompts, MAT will first present a modality-adaptive feature extractor (MAFE) to tackle the diverse modality discrepancies by introducing a modality prompt for each modality. In the training stage, a new modality translation contractive (MTC) loss will be further designed to assist MAFE in learning those modality-distinguishable modality prompts. Accordingly, in the testing stage, MAFE can employ those learned modality prompts to adaptively adjust its feature space according to the characteristics of the input modalities, thus being able to extract discriminative unimodal features. Then, MAFE will present a channel-wise and spatial-wise fusion hybrid (CSFH) strategy to meet the demand for dynamic fusion. For that, CSFH dedicates a channel-wise dynamic fusion module (CDFM) and a novel spatial-wise dynamic fusion module (SDFM) to fuse the unimodal features from varying numbers of modalities and meanwhile effectively capture cross-modal complementary semantic and detail information, respectively. Moreover, CSFH will carefully align CDFM and SDFM to different levels of unimodal features based on their characteristics for more effective complementary information exploitation.
Read more5/7/2024
🔎
0
SODAWideNet++: Combining Attention and Convolutions for Salient Object Detection
Rohit Venkata Sai Dulam, Chandra Kambhamettu
Salient Object Detection (SOD) has traditionally relied on feature refinement modules that utilize the features of an ImageNet pre-trained backbone. However, this approach limits the possibility of pre-training the entire network because of the distinct nature of SOD and image classification. Additionally, the architecture of these backbones originally built for Image classification is sub-optimal for a dense prediction task like SOD. To address these issues, we propose a novel encoder-decoder-style neural network called SODAWideNet++ that is designed explicitly for SOD. Inspired by the vision transformers ability to attain a global receptive field from the initial stages, we introduce the Attention Guided Long Range Feature Extraction (AGLRFE) module, which combines large dilated convolutions and self-attention. Specifically, we use attention features to guide long-range information extracted by multiple dilated convolutions, thus taking advantage of the inductive biases of a convolution operation and the input dependency brought by self-attention. In contrast to the current paradigm of ImageNet pre-training, we modify 118K annotated images from the COCO semantic segmentation dataset by binarizing the annotations to pre-train the proposed model end-to-end. Further, we supervise the background predictions along with the foreground to push our model to generate accurate saliency predictions. SODAWideNet++ performs competitively on five different datasets while only containing 35% of the trainable parameters compared to the state-of-the-art models. The code and pre-computed saliency maps are provided at https://github.com/VimsLab/SODAWideNetPlusPlus.
Read more8/30/2024
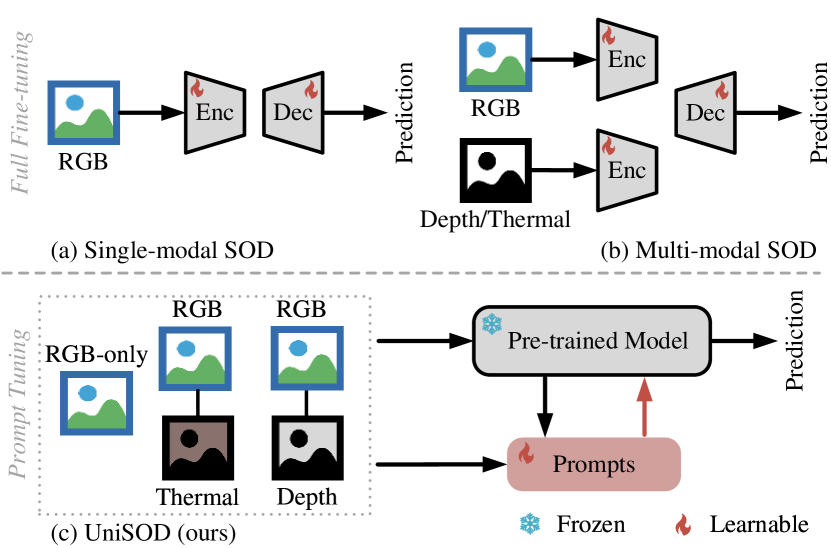
0
Unified-modal Salient Object Detection via Adaptive Prompt Learning
Kunpeng Wang, Chenglong Li, Zhengzheng Tu, Zhengyi Liu, Bin Luo
Existing single-modal and multi-modal salient object detection (SOD) methods focus on designing specific architectures tailored for their respective tasks. However, developing completely different models for different tasks leads to labor and time consumption, as well as high computational and practical deployment costs. In this paper, we attempt to address both single-modal and multi-modal SOD in a unified framework called UniSOD, which fully exploits the overlapping prior knowledge between different tasks. Nevertheless, assigning appropriate strategies to modality variable inputs is challenging. To this end, UniSOD learns modality-aware prompts with task-specific hints through adaptive prompt learning, which are plugged into the proposed pre-trained baseline SOD model to handle corresponding tasks, while only requiring few learnable parameters compared to training the entire model. Each modality-aware prompt is generated from a switchable prompt generation block, which adaptively performs structural switching based on single-modal and multi-modal inputs without human intervention. Through end-to-end joint training, UniSOD achieves overall performance improvement on 14 benchmark datasets for RGB, RGB-D, and RGB-T SOD, which demonstrates that our method effectively and efficiently unifies single-modal and multi-modal SOD tasks.The code and results are available at https://github.com/Angknpng/UniSOD.
Read more6/6/2024