VSCode: General Visual Salient and Camouflaged Object Detection with 2D Prompt Learning

0

Sign in to get full access
Overview
- The paper presents a novel approach for general visual salient and camouflaged object detection using 2D prompt learning.
- The proposed method, called VSCode, combines deep learning with prompt engineering to enable efficient and effective detection of both salient and camouflaged objects.
- The paper explores the potential of large foundation models and shows how they can be leveraged for open-vocabulary object detection tasks.
Plain English Explanation
The research paper introduces a new technique called VSCode that can help computers identify both visually striking and well-hidden objects in images. Traditionally, computer vision systems have struggled to detect objects that blend into their surroundings, a problem known as camouflage. VSCode aims to address this challenge by combining advanced deep learning models with a technique called "prompt engineering".
Prompt engineering involves carefully crafting the instructions or "prompts" that are given to large language models, like CODA: Instructive Chain for Domain Adaptation and Severity-Aware Object Detection or Exploring the Potential of Large Foundation Models for Open-Vocabulary Tasks. By using the right prompts, the researchers were able to fine-tune these powerful models to accurately identify both visually salient and camouflaged objects, going beyond what traditional object detectors are capable of.
The key insight of the VSCode approach is that large foundation models, when properly prompted, can learn to detect a wide range of objects without being limited to a predefined set. This opens up the possibility of "open-vocabulary" object detection, where the system can identify any object that a human can describe, rather than just a limited number of predetermined categories. The paper demonstrates the effectiveness of this approach on several benchmark datasets, showing significant improvements over existing state-of-the-art methods.
Technical Explanation
The paper introduces a novel approach called VSCode: General Visual Salient and Camouflaged Object Detection with 2D Prompt Learning. The key idea is to leverage the power of large foundation models, such as those used in Open-Vocabulary 6D Pose Estimation via Prompt Learning, and fine-tune them using carefully crafted 2D prompts to enable efficient and effective detection of both salient and camouflaged objects.
The authors first conduct a comprehensive analysis of the limitations of existing salient object detection (SOD) and camouflaged object detection (COD) methods. They identify the need for a more general and adaptable approach that can handle a diverse range of object types and appearances.
To address this, the researchers propose the VSCode framework, which consists of a prompt-based feature extractor and a prompt-based object detector. The feature extractor uses a Stronger Visual Saliency Transformer to capture both low-level visual cues and high-level semantic information. The object detector then leverages these features, along with the prompts, to accurately identify salient and camouflaged objects.
The paper presents extensive experiments on multiple benchmark datasets, demonstrating the superior performance of VSCode compared to state-of-the-art SOD and COD methods. The researchers also analyze the impact of different prompt engineering strategies and the potential of large foundation models for open-vocabulary object detection tasks.
Critical Analysis
The VSCode approach presented in the paper represents a significant step forward in the field of object detection, particularly in the challenging domain of camouflaged object detection. The researchers have successfully demonstrated the potential of large foundation models and prompt engineering to enable more general and adaptable object detection systems.
One key strength of the VSCode approach is its ability to handle a wide range of object types and appearances, going beyond the limitations of traditional object detectors. By leveraging the open-vocabulary capabilities of large foundation models, the system can potentially identify any object that a user can describe, rather than being restricted to a predefined set of categories.
However, the paper does not fully address the potential limitations and caveats of this approach. For example, the performance and robustness of the system in real-world, dynamic environments, where objects may be occluded or undergo significant changes in appearance, remains to be thoroughly investigated. Additionally, the computational and memory requirements of the VSCode framework, especially when scaling to larger foundation models, could be a concern for practical deployment.
Further research is needed to explore the long-term implications and potential societal impacts of open-vocabulary object detection systems. Questions around bias, fairness, and the ethical use of such technology should be carefully considered as the field advances.
Conclusion
The VSCode paper presents a promising approach for general visual salient and camouflaged object detection, leveraging the power of large foundation models and prompt engineering. By combining advanced deep learning techniques with carefully crafted prompts, the researchers have developed a more adaptable and effective object detection system that can identify a wide range of objects, including those that are well-camouflaged.
The findings of this study contribute to the ongoing efforts to improve computer vision capabilities, particularly in challenging scenarios where traditional object detectors struggle. The potential of open-vocabulary object detection, as demonstrated by VSCode, opens up new possibilities for more flexible and versatile applications in areas such as autonomous systems, assistive technologies, and image analysis.
As the field of AI continues to evolve, it will be crucial to address the potential limitations and ethical considerations surrounding these advanced object detection techniques. Ongoing research and collaboration between academia, industry, and policymakers will be essential to ensure that these technologies are developed and deployed in a responsible and beneficial manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VSCode: General Visual Salient and Camouflaged Object Detection with 2D Prompt Learning
Ziyang Luo, Nian Liu, Wangbo Zhao, Xuguang Yang, Dingwen Zhang, Deng-Ping Fan, Fahad Khan, Junwei Han
Salient object detection (SOD) and camouflaged object detection (COD) are related yet distinct binary mapping tasks. These tasks involve multiple modalities, sharing commonalities and unique cues. Existing research often employs intricate task-specific specialist models, potentially leading to redundancy and suboptimal results. We introduce VSCode, a generalist model with novel 2D prompt learning, to jointly address four SOD tasks and three COD tasks. We utilize VST as the foundation model and introduce 2D prompts within the encoder-decoder architecture to learn domain and task-specific knowledge on two separate dimensions. A prompt discrimination loss helps disentangle peculiarities to benefit model optimization. VSCode outperforms state-of-the-art methods across six tasks on 26 datasets and exhibits zero-shot generalization to unseen tasks by combining 2D prompts, such as RGB-D COD. Source code has been available at https://github.com/Sssssuperior/VSCode.
Read more4/12/2024

0
Just a Hint: Point-Supervised Camouflaged Object Detection
Huafeng Chen, Dian Shao, Guangqian Guo, Shan Gao
Camouflaged Object Detection (COD) demands models to expeditiously and accurately distinguish objects which conceal themselves seamlessly in the environment. Owing to the subtle differences and ambiguous boundaries, COD is not only a remarkably challenging task for models but also for human annotators, requiring huge efforts to provide pixel-wise annotations. To alleviate the heavy annotation burden, we propose to fulfill this task with the help of only one point supervision. Specifically, by swiftly clicking on each object, we first adaptively expand the original point-based annotation to a reasonable hint area. Then, to avoid partial localization around discriminative parts, we propose an attention regulator to scatter model attention to the whole object through partially masking labeled regions. Moreover, to solve the unstable feature representation of camouflaged objects under only point-based annotation, we perform unsupervised contrastive learning based on differently augmented image pairs (e.g. changing color or doing translation). On three mainstream COD benchmarks, experimental results show that our model outperforms several weakly-supervised methods by a large margin across various metrics.
Read more8/21/2024

0
A Survey of Camouflaged Object Detection and Beyond
Fengyang Xiao, Sujie Hu, Yuqi Shen, Chengyu Fang, Jinfa Huang, Chunming He, Longxiang Tang, Ziyun Yang, Xiu Li
Camouflaged Object Detection (COD) refers to the task of identifying and segmenting objects that blend seamlessly into their surroundings, posing a significant challenge for computer vision systems. In recent years, COD has garnered widespread attention due to its potential applications in surveillance, wildlife conservation, autonomous systems, and more. While several surveys on COD exist, they often have limitations in terms of the number and scope of papers covered, particularly regarding the rapid advancements made in the field since mid-2023. To address this void, we present the most comprehensive review of COD to date, encompassing both theoretical frameworks and practical contributions to the field. This paper explores various COD methods across four domains, including both image-level and video-level solutions, from the perspectives of traditional and deep learning approaches. We thoroughly investigate the correlations between COD and other camouflaged scenario methods, thereby laying the theoretical foundation for subsequent analyses. Beyond object-level detection, we also summarize extended methods for instance-level tasks, including camouflaged instance segmentation, counting, and ranking. Additionally, we provide an overview of commonly used benchmarks and evaluation metrics in COD tasks, conducting a comprehensive evaluation of deep learning-based techniques in both image and video domains, considering both qualitative and quantitative performance. Finally, we discuss the limitations of current COD models and propose 9 promising directions for future research, focusing on addressing inherent challenges and exploring novel, meaningful technologies. For those interested, a curated list of COD-related techniques, datasets, and additional resources can be found at https://github.com/ChunmingHe/awesome-concealed-object-segmentation
Read more8/28/2024
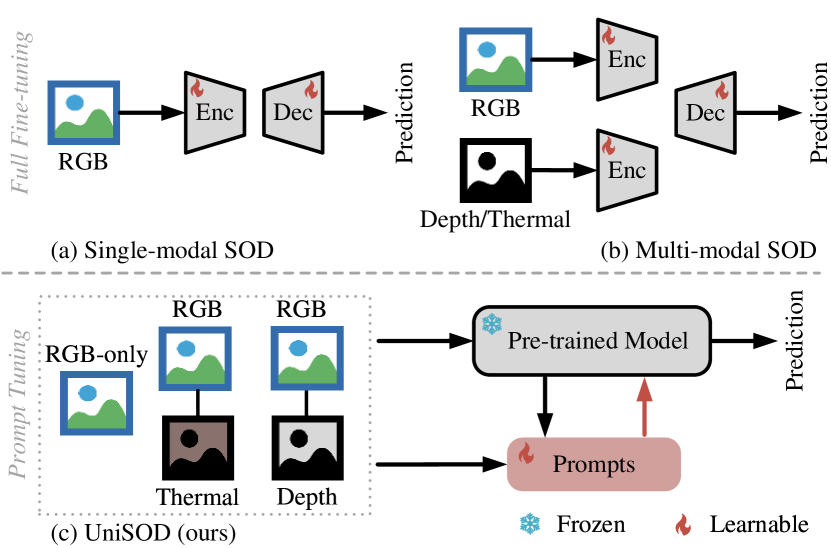
0
Unified-modal Salient Object Detection via Adaptive Prompt Learning
Kunpeng Wang, Chenglong Li, Zhengzheng Tu, Zhengyi Liu, Bin Luo
Existing single-modal and multi-modal salient object detection (SOD) methods focus on designing specific architectures tailored for their respective tasks. However, developing completely different models for different tasks leads to labor and time consumption, as well as high computational and practical deployment costs. In this paper, we attempt to address both single-modal and multi-modal SOD in a unified framework called UniSOD, which fully exploits the overlapping prior knowledge between different tasks. Nevertheless, assigning appropriate strategies to modality variable inputs is challenging. To this end, UniSOD learns modality-aware prompts with task-specific hints through adaptive prompt learning, which are plugged into the proposed pre-trained baseline SOD model to handle corresponding tasks, while only requiring few learnable parameters compared to training the entire model. Each modality-aware prompt is generated from a switchable prompt generation block, which adaptively performs structural switching based on single-modal and multi-modal inputs without human intervention. Through end-to-end joint training, UniSOD achieves overall performance improvement on 14 benchmark datasets for RGB, RGB-D, and RGB-T SOD, which demonstrates that our method effectively and efficiently unifies single-modal and multi-modal SOD tasks.The code and results are available at https://github.com/Angknpng/UniSOD.
Read more6/6/2024