Unifying 3D Vision-Language Understanding via Promptable Queries

0

Sign in to get full access
Overview
- This paper introduces a new approach called Unifying 3D Vision-Language Understanding via Promptable Queries (UNIM-OV3D) that aims to unify 3D vision and language understanding tasks.
- The key idea is to enable a single model to handle a wide range of 3D vision-language tasks through the use of promptable queries, which allow the model to be instructed to perform different tasks.
- This builds on previous work on unified scene representation and reconstruction, language-image models for 3D understanding, and making large multimodal models understand.
Plain English Explanation
The paper introduces a new way to create AI models that can understand and work with both 3D visual information and language. The key idea is to give the model instructions in the form of prompts that tell it what task to perform, such as describing an object, finding an object, or answering a question about a 3D scene.
This is an important advancement because previous AI models were often specialized for a single task, like just describing images or just answering questions. By making a more flexible model that can handle a wide range of 3D vision and language tasks through prompts, the researchers hope to create AI systems that are more useful and adaptable in the real world.
The paper builds on previous work that has looked at ways to combine 3D and language understanding, represent 3D scenes in a unified way, and make large multimodal models (that work with multiple data types) more capable.
Technical Explanation
The UNIM-OV3D model is built on a transformer-based architecture that takes in both 3D visual data (e.g. point clouds or meshes) and language prompts.
The key innovation is the use of promptable queries, which allow the model to be instructed to perform different tasks through natural language prompts. For example, the model could be prompted to "Find the red chair in the scene" or "Describe the object in the top left corner."
This flexible prompt-based approach enables the model to handle a wide range of 3D vision-language tasks, such as:
- 3D object detection and segmentation
- 3D scene understanding and reasoning
- Multimodal retrieval and generation
The paper describes extensive experiments demonstrating the model's strong performance on a variety of 3D vision-language benchmarks, including 3D visual grounding tasks.
Critical Analysis
The UNIM-OV3D approach represents an important step forward in unifying 3D vision and language understanding. By enabling a single model to handle a diverse set of tasks through prompts, it has the potential to lead to more flexible and versatile AI systems.
However, the paper acknowledges some limitations. For example, the model may struggle with prompts that require complex reasoning or grounding to the specific 3D scene. There is also a need for further research to improve the model's performance on tasks like 3D object manipulation and interaction.
Additionally, the reliance on prompts raises questions about the model's robustness and generalization. It's not clear how well the model would perform on entirely novel prompts or tasks that diverge significantly from its training.
Overall, the UNIM-OV3D approach is a promising step forward, but continued research will be needed to fully realize the potential of unifying 3D vision and language understanding.
Conclusion
This paper presents an innovative approach called UNIM-OV3D that aims to unify 3D vision and language understanding tasks through the use of promptable queries. By enabling a single model to handle a wide range of 3D vision-language challenges, the researchers hope to create more flexible and useful AI systems.
The key ideas build on previous work in unified scene representation, language-image models for 3D understanding, and making large multimodal models more capable. While the UNIM-OV3D model shows strong performance, there are still important challenges to address around robustness and generalization.
Overall, this research represents an exciting step forward in the quest to create AI systems that can seamlessly combine 3D visual perception and language understanding, with broad implications for applications like robotics, augmented reality, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unifying 3D Vision-Language Understanding via Promptable Queries
Ziyu Zhu, Zhuofan Zhang, Xiaojian Ma, Xuesong Niu, Yixin Chen, Baoxiong Jia, Zhidong Deng, Siyuan Huang, Qing Li
A unified model for 3D vision-language (3D-VL) understanding is expected to take various scene representations and perform a wide range of tasks in a 3D scene. However, a considerable gap exists between existing methods and such a unified model, due to the independent application of representation and insufficient exploration of 3D multi-task training. In this paper, we introduce PQ3D, a unified model capable of using Promptable Queries to tackle a wide range of 3D-VL tasks, from low-level instance segmentation to high-level reasoning and planning. This is achieved through three key innovations: (1) unifying various 3D scene representations (i.e., voxels, point clouds, multi-view images) into a shared 3D coordinate space by segment-level grouping, (2) an attention-based query decoder for task-specific information retrieval guided by prompts, and (3) universal output heads for different tasks to support multi-task training. Tested across ten diverse 3D-VL datasets, PQ3D demonstrates impressive performance on these tasks, setting new records on most benchmarks. Particularly, PQ3D improves the state-of-the-art on ScanNet200 by 4.9% (AP25), ScanRefer by 5.4% ([email protected]), Multi3DRefer by 11.7% ([email protected]), and Scan2Cap by 13.4% ([email protected]). Moreover, PQ3D supports flexible inference with individual or combined forms of available 3D representations, e.g., solely voxel input.
Read more7/25/2024

0
UniM-OV3D: Uni-Modality Open-Vocabulary 3D Scene Understanding with Fine-Grained Feature Representation
Qingdong He, Jinlong Peng, Zhengkai Jiang, Kai Wu, Xiaozhong Ji, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Mingang Chen, Yunsheng Wu
3D open-vocabulary scene understanding aims to recognize arbitrary novel categories beyond the base label space. However, existing works not only fail to fully utilize all the available modal information in the 3D domain but also lack sufficient granularity in representing the features of each modality. In this paper, we propose a unified multimodal 3D open-vocabulary scene understanding network, namely UniM-OV3D, which aligns point clouds with image, language and depth. To better integrate global and local features of the point clouds, we design a hierarchical point cloud feature extraction module that learns comprehensive fine-grained feature representations. Further, to facilitate the learning of coarse-to-fine point-semantic representations from captions, we propose the utilization of hierarchical 3D caption pairs, capitalizing on geometric constraints across various viewpoints of 3D scenes. Extensive experimental results demonstrate the effectiveness and superiority of our method in open-vocabulary semantic and instance segmentation, which achieves state-of-the-art performance on both indoor and outdoor benchmarks such as ScanNet, ScanNet200, S3IDS and nuScenes. Code is available at https://github.com/hithqd/UniM-OV3D.
Read more4/23/2024
0
Unified Scene Representation and Reconstruction for 3D Large Language Models
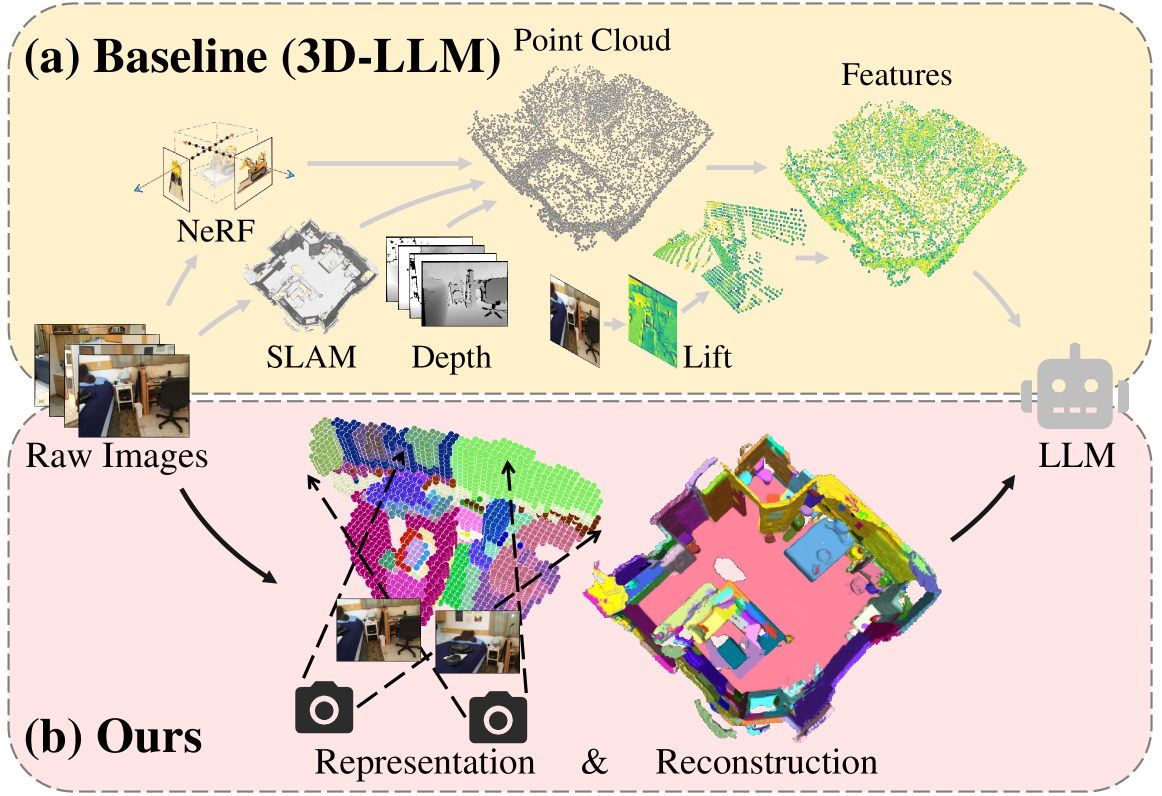
Tao Chu, Pan Zhang, Xiaoyi Dong, Yuhang Zang, Qiong Liu, Jiaqi Wang
Enabling Large Language Models (LLMs) to interact with 3D environments is challenging. Existing approaches extract point clouds either from ground truth (GT) geometry or 3D scenes reconstructed by auxiliary models. Text-image aligned 2D features from CLIP are then lifted to point clouds, which serve as inputs for LLMs. However, this solution lacks the establishment of 3D point-to-point connections, leading to a deficiency of spatial structure information. Concurrently, the absence of integration and unification between the geometric and semantic representations of the scene culminates in a diminished level of 3D scene understanding. In this paper, we demonstrate the importance of having a unified scene representation and reconstruction framework, which is essential for LLMs in 3D scenes. Specifically, we introduce Uni3DR^2 extracts 3D geometric and semantic aware representation features via the frozen pre-trained 2D foundation models (e.g., CLIP and SAM) and a multi-scale aggregate 3D decoder. Our learned 3D representations not only contribute to the reconstruction process but also provide valuable knowledge for LLMs. Experimental results validate that our Uni3DR^2 yields convincing gains over the baseline on the 3D reconstruction dataset ScanNet (increasing F-Score by +1.8%). When applied to LLMs, our Uni3DR^2-LLM exhibits superior performance over the baseline on the 3D vision-language understanding dataset ScanQA (increasing BLEU-1 by +4.0% and +4.2% on the val set and test set, respectively). Furthermore, it outperforms the state-of-the-art method that uses additional GT point clouds on both ScanQA and 3DMV-VQA.
Read more4/22/2024
0
A Unified Framework for 3D Scene Understanding
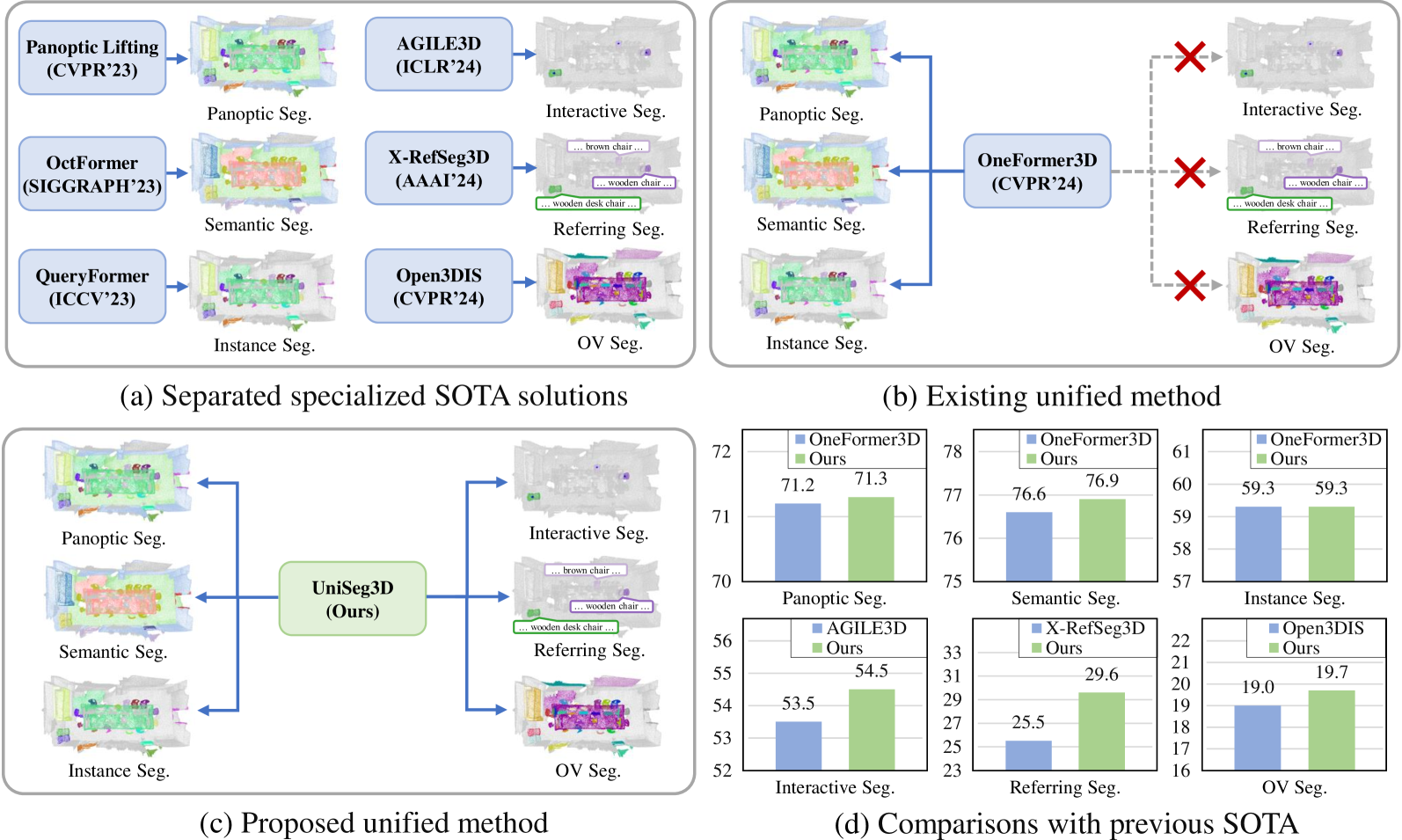
Wei Xu, Chunsheng Shi, Sifan Tu, Xin Zhou, Dingkang Liang, Xiang Bai
We propose UniSeg3D, a unified 3D segmentation framework that achieves panoptic, semantic, instance, interactive, referring, and open-vocabulary semantic segmentation tasks within a single model. Most previous 3D segmentation approaches are specialized for a specific task, thereby limiting their understanding of 3D scenes to a task-specific perspective. In contrast, the proposed method unifies six tasks into unified representations processed by the same Transformer. It facilitates inter-task knowledge sharing and, therefore, promotes comprehensive 3D scene understanding. To take advantage of multi-task unification, we enhance the performance by leveraging task connections. Specifically, we design a knowledge distillation method and a contrastive learning method to transfer task-specific knowledge across different tasks. Benefiting from extensive inter-task knowledge sharing, our UniSeg3D becomes more powerful. Experiments on three benchmarks, including the ScanNet20, ScanRefer, and ScanNet200, demonstrate that the UniSeg3D consistently outperforms current SOTA methods, even those specialized for individual tasks. We hope UniSeg3D can serve as a solid unified baseline and inspire future work. The code will be available at https://dk-liang.github.io/UniSeg3D/.
Read more7/4/2024