Unifying Causal Representation Learning with the Invariance Principle

0
✨
Sign in to get full access
Overview
- Causal representation learning aims to uncover latent causal variables from high-dimensional observations to solve downstream causal tasks.
- Many causal representation learning methods have been developed, each with different problem settings and identifiability assumptions.
- The key contribution of this paper is to show that these methods are actually aligning representations to known data symmetries, not necessarily causal variables.
- This insight allows the authors to unify many existing approaches into a single method that can mix and match different assumptions, including non-causal ones, based on relevant invariances.
- The authors demonstrate improved treatment effect estimation on real-world high-dimensional ecological data, highlighting the practical benefits of their approach.
Plain English Explanation
Causal representation learning is a field of research that aims to uncover the underlying causal factors behind complex, high-dimensional data. The goal is to recover these latent causal variables, which can then be used to solve tasks like predicting the effects of new interventions or making more robust classifications.
Over the years, researchers have developed many different methods for causal representation learning, each with its own set of assumptions and problem settings. These different approaches are often linked to different levels of Pearl's causal hierarchy, which describes the various types of causal knowledge that can be extracted from data.
However, the key insight from this paper is that many of these existing causal representation learning methods are actually aligning the learned representations to known data symmetries, rather than necessarily uncovering the true causal variables. In other words, the identified variables may not always be causal in nature, but rather reflect patterns of invariance across different parts of the data.
This realization allows the authors to unify many of these existing approaches into a single, more flexible method. Their approach can mix and match different assumptions, including both causal and non-causal ones, based on the specific invariances that are relevant to the application at hand. The authors demonstrate the benefits of this approach by showing improved performance on a real-world task of estimating treatment effects from high-dimensional ecological data.
Overall, this paper provides an important shift in perspective, moving the focus away from the specific causal assumptions and towards the more general goal of preserving data symmetries. This has significant implications for the field of causal representation learning, opening up new avenues for developing more robust and applicable methods.
Technical Explanation
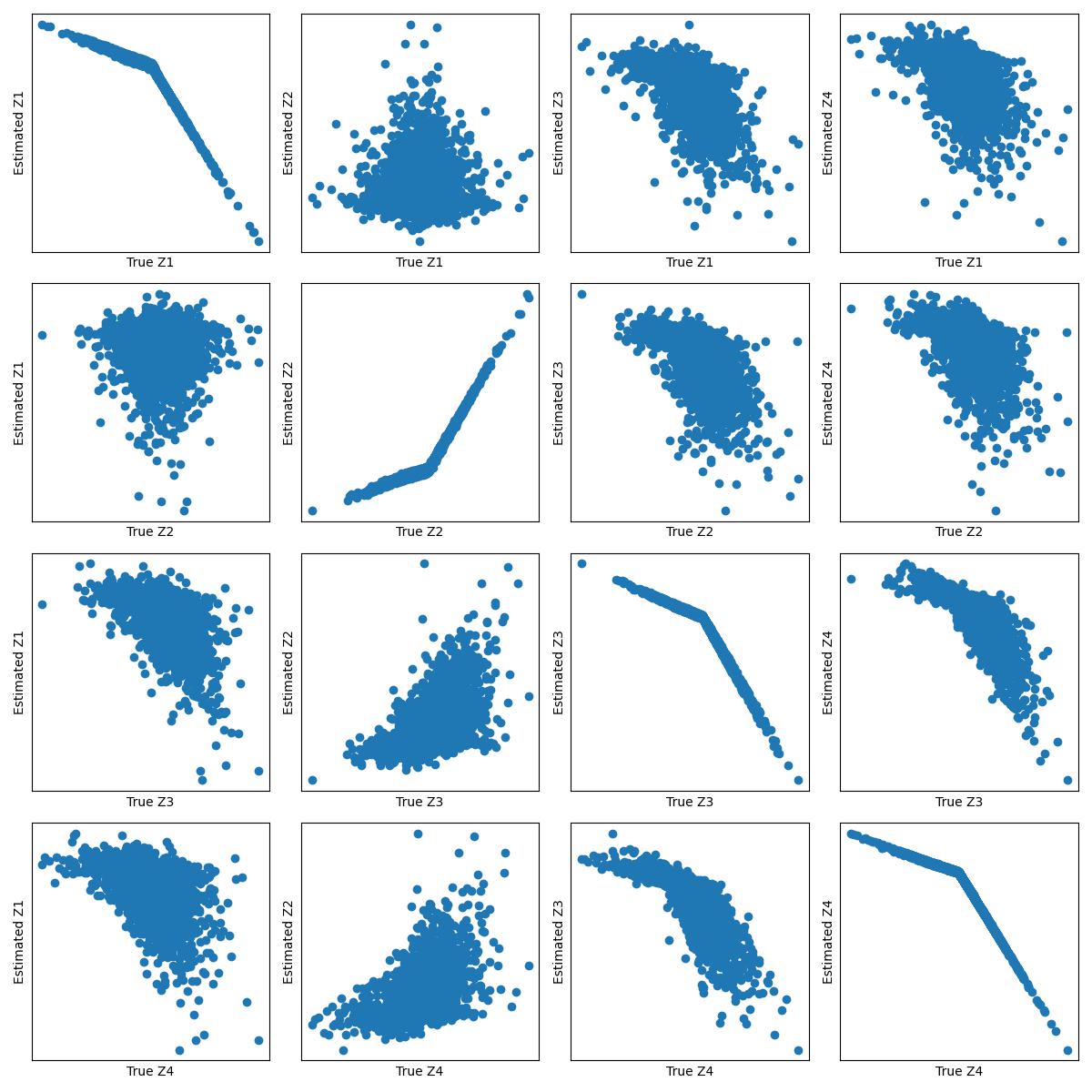
The key insight from this paper is that many existing causal representation learning methods are actually aligning the learned representations to known data symmetries, rather than necessarily recovering the true latent causal variables.
The authors show that the identification of variables in these methods is guided by equivalence classes across different data pockets, which are not necessarily causal in nature. This means that the discovered variables may reflect patterns of invariance in the data, but not necessarily the underlying causal structure.
To demonstrate this, the authors propose a unifying framework that can mix and match different assumptions, including both causal and non-causal ones, based on the relevant invariances in the data. They show that this approach can outperform specialized causal representation learning methods on a real-world task of estimating treatment effects from high-dimensional ecological data.
The authors' work significantly shifts the focus in causal representation learning away from the specific causal assumptions and towards the more general goal of preserving data symmetries. This has important implications, as it suggests that many existing causal representation learning methods may be effective not because they are recovering true causal variables, but because they are aligning the representations to relevant data patterns.
Critical Analysis
The authors' key insight about the role of data symmetries in causal representation learning is an important contribution to the field. By showing that many existing methods are not necessarily recovering true causal variables, but rather aligning representations to known invariances, the authors challenge some of the underlying assumptions in the field.
However, the paper does not fully address the potential limitations of this approach. For example, it is unclear how the authors' unified framework would perform in situations where the relevant data symmetries are not known a priori, or when the causal structure of the data is more complex and cannot be easily captured by simple invariances.
Additionally, the authors' demonstration of improved treatment effect estimation on the ecological data is promising, but it would be valuable to see how their approach compares to other state-of-the-art methods on a broader range of benchmark tasks and datasets. This would help to better understand the strengths and weaknesses of their unified framework.
Overall, the paper makes an important conceptual contribution by shifting the focus in causal representation learning towards data symmetries, but there is still room for further exploration and validation of the authors' ideas, particularly in more challenging real-world scenarios.
Conclusion
This paper presents a significant shift in perspective for the field of causal representation learning. By showing that many existing methods are actually aligning representations to known data symmetries, rather than recovering true causal variables, the authors challenge some of the fundamental assumptions in the field.
The authors' proposed unified framework, which can mix and match different assumptions based on relevant invariances, demonstrates the practical benefits of this new approach. The improved performance on a real-world task of treatment effect estimation suggests that preserving data symmetries may be a more effective strategy than strictly enforcing causal assumptions.
Overall, this paper opens up new avenues for research in causal representation learning, moving the focus away from the specific causal hierarchy and towards the more general goal of uncovering and preserving the underlying structure of the data. As the field continues to evolve, this shift in perspective may lead to the development of more robust and applicable methods for solving a wide range of causal downstream tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✨
0
Unifying Causal Representation Learning with the Invariance Principle
Dingling Yao, Dario Rancati, Riccardo Cadei, Marco Fumero, Francesco Locatello
Causal representation learning aims at recovering latent causal variables from high-dimensional observations to solve causal downstream tasks, such as predicting the effect of new interventions or more robust classification. A plethora of methods have been developed, each tackling carefully crafted problem settings that lead to different types of identifiability. The folklore is that these different settings are important, as they are often linked to different rungs of Pearl's causal hierarchy, although not all neatly fit. Our main contribution is to show that many existing causal representation learning approaches methodologically align the representation to known data symmetries. Identification of the variables is guided by equivalence classes across different data pockets that are not necessarily causal. This result suggests important implications, allowing us to unify many existing approaches in a single method that can mix and match different assumptions, including non-causal ones, based on the invariances relevant to our application. It also significantly benefits applicability, which we demonstrate by improving treatment effect estimation on real-world high-dimensional ecological data. Overall, this paper clarifies the role of causality assumptions in the discovery of causal variables and shifts the focus to preserving data symmetries.
Read more9/5/2024
🔎
0
Identifiable Causal Representation Learning: Unsupervised, Multi-View, and Multi-Environment
Julius von Kugelgen
Causal models provide rich descriptions of complex systems as sets of mechanisms by which each variable is influenced by its direct causes. They support reasoning about manipulating parts of the system and thus hold promise for addressing some of the open challenges of artificial intelligence (AI), such as planning, transferring knowledge in changing environments, or robustness to distribution shifts. However, a key obstacle to more widespread use of causal models in AI is the requirement that the relevant variables be specified a priori, which is typically not the case for the high-dimensional, unstructured data processed by modern AI systems. At the same time, machine learning (ML) has proven quite successful at automatically extracting useful and compact representations of such complex data. Causal representation learning (CRL) aims to combine the core strengths of ML and causality by learning representations in the form of latent variables endowed with causal model semantics. In this thesis, we study and present new results for different CRL settings. A central theme is the question of identifiability: Given infinite data, when are representations satisfying the same learning objective guaranteed to be equivalent? This is an important prerequisite for CRL, as it formally characterises if and when a learning task is, at least in principle, feasible. Since learning causal models, even without a representation learning component, is notoriously difficult, we require additional assumptions on the model class or rich data beyond the classical i.i.d. setting. By partially characterising identifiability for different settings, this thesis investigates what is possible for CRL without direct supervision, and thus contributes to its theoretical foundations. Ideally, the developed insights can help inform data collection practices or inspire the design of new practical estimation methods.
Read more6/21/2024
0
Causal Representation Learning from Multiple Distributions: A General Setting
Kun Zhang, Shaoan Xie, Ignavier Ng, Yujia Zheng
In many problems, the measured variables (e.g., image pixels) are just mathematical functions of the latent causal variables (e.g., the underlying concepts or objects). For the purpose of making predictions in changing environments or making proper changes to the system, it is helpful to recover the latent causal variables $Z_i$ and their causal relations represented by graph $mathcal{G}_Z$. This problem has recently been known as causal representation learning. This paper is concerned with a general, completely nonparametric setting of causal representation learning from multiple distributions (arising from heterogeneous data or nonstationary time series), without assuming hard interventions behind distribution changes. We aim to develop general solutions in this fundamental case; as a by product, this helps see the unique benefit offered by other assumptions such as parametric causal models or hard interventions. We show that under the sparsity constraint on the recovered graph over the latent variables and suitable sufficient change conditions on the causal influences, interestingly, one can recover the moralized graph of the underlying directed acyclic graph, and the recovered latent variables and their relations are related to the underlying causal model in a specific, nontrivial way. In some cases, most latent variables can even be recovered up to component-wise transformations. Experimental results verify our theoretical claims.
Read more8/13/2024
🔎
0
Causal Representation Learning Made Identifiable by Grouping of Observational Variables
Hiroshi Morioka, Aapo Hyvarinen
A topic of great current interest is Causal Representation Learning (CRL), whose goal is to learn a causal model for hidden features in a data-driven manner. Unfortunately, CRL is severely ill-posed since it is a combination of the two notoriously ill-posed problems of representation learning and causal discovery. Yet, finding practical identifiability conditions that guarantee a unique solution is crucial for its practical applicability. Most approaches so far have been based on assumptions on the latent causal mechanisms, such as temporal causality, or existence of supervision or interventions; these can be too restrictive in actual applications. Here, we show identifiability based on novel, weak constraints, which requires no temporal structure, intervention, nor weak supervision. The approach is based on assuming the observational mixing exhibits a suitable grouping of the observational variables. We also propose a novel self-supervised estimation framework consistent with the model, prove its statistical consistency, and experimentally show its superior CRL performances compared to the state-of-the-art baselines. We further demonstrate its robustness against latent confounders and causal cycles.
Read more6/10/2024