Universal Score-based Speech Enhancement with High Content Preservation
2406.12194
0
0
Abstract
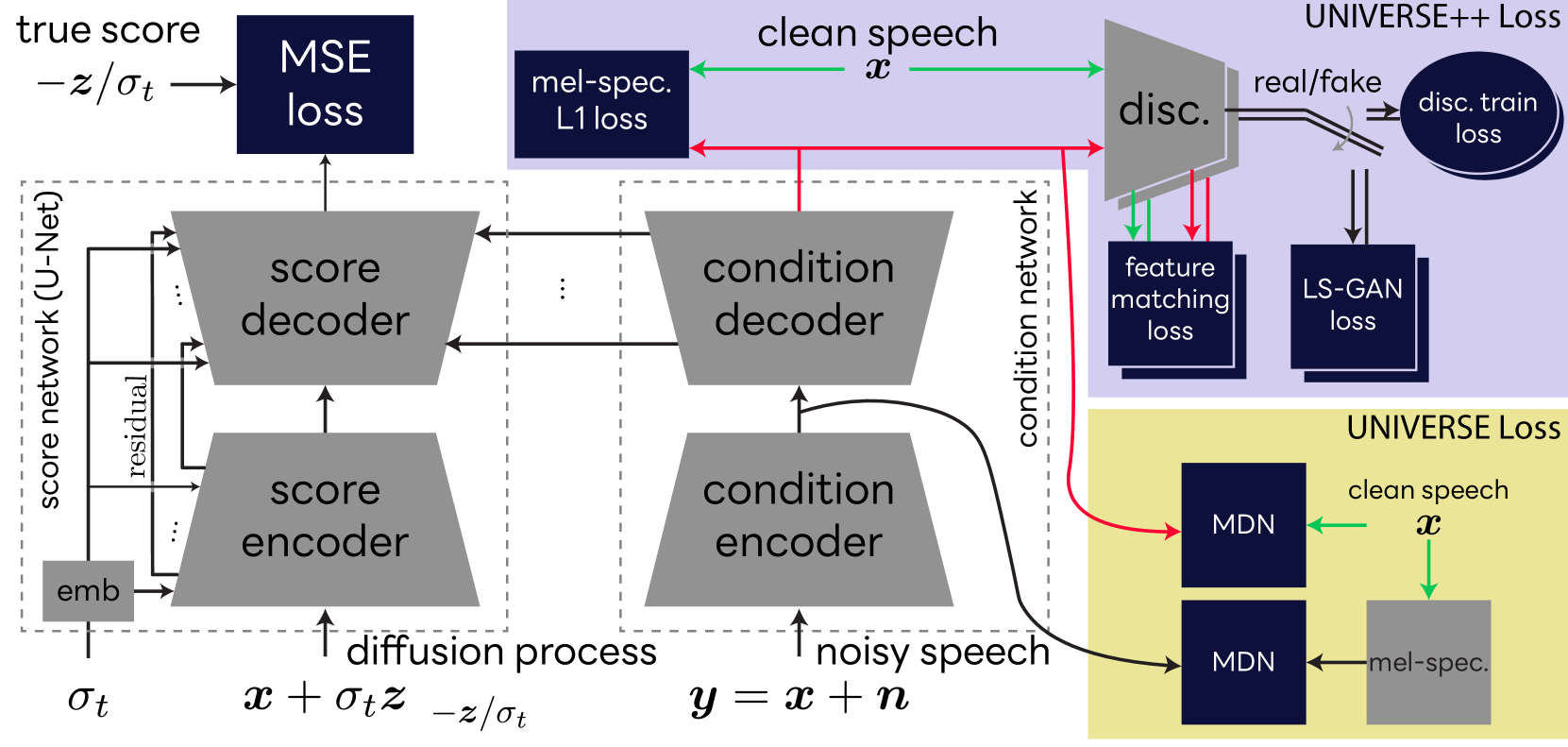
We propose UNIVERSE++, a universal speech enhancement method based on score-based diffusion and adversarial training. Specifically, we improve the existing UNIVERSE model that decouples clean speech feature extraction and diffusion. Our contributions are three-fold. First, we make several modifications to the network architecture, improving training stability and final performance. Second, we introduce an adversarial loss to promote learning high quality speech features. Third, we propose a low-rank adaptation scheme with a phoneme fidelity loss to improve content preservation in the enhanced speech. In the experiments, we train a universal enhancement model on a large scale dataset of speech degraded by noise, reverberation, and various distortions. The results on multiple public benchmark datasets demonstrate that UNIVERSE++ compares favorably to both discriminative and generative baselines for a wide range of qualitative and intelligibility metrics.
Create account to get full access
Overview
- This paper introduces a universal speech enhancement model that can improve the quality and intelligibility of speech signals while preserving the content and characteristics of the original speech.
- The proposed approach utilizes a score-based generative model, which is trained on a diverse dataset of speech signals and can be applied to various speech enhancement tasks without the need for task-specific fine-tuning.
- The model demonstrates high content preservation, meaning it can enhance the speech signal while retaining the speaker's identity, emotion, and other key features.
Plain English Explanation
The researchers have developed a new way to improve the quality of speech recordings, such as making them clearer or reducing background noise, while still keeping the original speaker's voice and characteristics intact. This is important because often speech enhancement techniques can change the sound of the voice, which can be problematic in applications like virtual assistants or video conferencing.
The key innovation is that this model is "universal," meaning it can be applied to many different speech enhancement tasks without needing to be specifically trained for each one. The model uses a score-based generative model, which is a type of AI that learns to model the underlying structure of speech signals. This allows the model to enhance the speech in a way that preserves the original content and speaker identity, rather than just making the audio louder or removing noise.
The researchers show that their universal speech enhancement model can outperform previous approaches that were more specialized and required retraining for different tasks. This makes the model more flexible and practical for real-world applications where the speech enhancement needs may vary.
Technical Explanation
The paper presents a universal score-based speech enhancement model that can improve the quality and intelligibility of speech signals while preserving the content and characteristics of the original speech. The key technical contributions are:
-
Score-based Generative Model: The model is based on a score-based generative approach, which learns to model the underlying structure of clean speech signals. This allows the model to generate enhanced speech that preserves the original content and speaker identity.
-
Universal Training: The model is trained on a diverse dataset of speech signals, enabling it to be applied to various speech enhancement tasks without the need for task-specific fine-tuning. This is in contrast to previous approaches that required retraining for different applications.
-
High Content Preservation: The model demonstrates the ability to enhance the speech signal while retaining the speaker's identity, emotion, and other key features. This is an important property for applications where preserving the original speech characteristics is crucial, such as in virtual assistants or video conferencing.
The researchers evaluate the proposed model on various speech enhancement tasks, including denoising, dereverberation, and joint denoising and dereverberation. The results show that the universal speech enhancement model outperforms previous state-of-the-art approaches that were more specialized and required retraining for different tasks.
Critical Analysis
The paper presents a compelling approach to speech enhancement that addresses the important challenge of preserving the content and characteristics of the original speech signal. The use of a score-based generative model is a novel and promising direction, as it allows the model to learn the underlying structure of clean speech rather than relying on task-specific heuristics or architectural choices.
One potential limitation of the study is the lack of evaluation on real-world, in-the-wild speech data. The experiments were conducted on synthetic datasets, which may not fully capture the complexity and variability of real-world speech signals. It would be valuable to see how the universal speech enhancement model performs on more diverse and challenging data, such as recordings from low-resource devices or multilingual speech.
Additionally, while the paper demonstrates the model's ability to preserve content and characteristics, it would be helpful to have a more detailed analysis of the specific aspects of speech that are being preserved (e.g., speaker identity, emotion, prosody, etc.) and how this compares to other state-of-the-art approaches.
Overall, the proposed universal speech enhancement model represents an important step forward in the field, and the authors' focus on content preservation is a valuable contribution. Further research to address the potential limitations and expand the evaluation of the model would help solidify its practical applicability and impact.
Conclusion
The paper introduces a novel universal speech enhancement model that can improve the quality and intelligibility of speech signals while preserving the content and characteristics of the original speech. The key innovation is the use of a score-based generative approach, which allows the model to be applied to various speech enhancement tasks without the need for task-specific fine-tuning.
The model's ability to enhance speech while retaining the speaker's identity, emotion, and other key features is a significant advancement, as it addresses an important challenge in speech enhancement. The universal nature of the model also makes it more flexible and practical for real-world applications where the speech enhancement needs may vary.
Overall, this research represents an important step forward in the field of speech enhancement, with the potential to enable more natural and user-friendly speech-based interfaces and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
URGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement
Wangyou Zhang, Robin Scheibler, Kohei Saijo, Samuele Cornell, Chenda Li, Zhaoheng Ni, Anurag Kumar, Jan Pirklbauer, Marvin Sach, Shinji Watanabe, Tim Fingscheidt, Yanmin Qian
0
0
The last decade has witnessed significant advancements in deep learning-based speech enhancement (SE). However, most existing SE research has limitations on the coverage of SE sub-tasks, data diversity and amount, and evaluation metrics. To fill this gap and promote research toward universal SE, we establish a new SE challenge, named URGENT, to focus on the universality, robustness, and generalizability of SE. We aim to extend the SE definition to cover different sub-tasks to explore the limits of SE models, starting from denoising, dereverberation, bandwidth extension, and declipping. A novel framework is proposed to unify all these sub-tasks in a single model, allowing the use of all existing SE approaches. We collected public speech and noise data from different domains to construct diverse evaluation data. Finally, we discuss the insights gained from our preliminary baseline experiments based on both generative and discriminative SE methods with 12 curated metrics.
6/10/2024
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
Wenbin Wang, Yang Song, Sanjay Jha
0
0
Conventional text-to-speech (TTS) research has predominantly focused on enhancing the quality of synthesized speech for speakers in the training dataset. The challenge of synthesizing lifelike speech for unseen, out-of-dataset speakers, especially those with limited reference data, remains a significant and unresolved problem. While zero-shot or few-shot speaker-adaptive TTS approaches have been explored, they have many limitations. Zero-shot approaches tend to suffer from insufficient generalization performance to reproduce the voice of speakers with heavy accents. While few-shot methods can reproduce highly varying accents, they bring a significant storage burden and the risk of overfitting and catastrophic forgetting. In addition, prior approaches only provide either zero-shot or few-shot adaptation, constraining their utility across varied real-world scenarios with different demands. Besides, most current evaluations of speaker-adaptive TTS are conducted only on datasets of native speakers, inadvertently neglecting a vast portion of non-native speakers with diverse accents. Our proposed framework unifies both zero-shot and few-shot speaker adaptation strategies, which we term as instant and fine-grained adaptations based on their merits. To alleviate the insufficient generalization performance observed in zero-shot speaker adaptation, we designed two innovative discriminators and introduced a memory mechanism for the speech decoder. To prevent catastrophic forgetting and reduce storage implications for few-shot speaker adaptation, we designed two adapters and a unique adaptation procedure.
4/30/2024
Speech enhancement deep-learning architecture for efficient edge processing
Monisankha Pal, Arvind Ramanathan, Ted Wada, Ashutosh Pandey
0
0
Deep learning has become a de facto method of choice for speech enhancement tasks with significant improvements in speech quality. However, real-time processing with reduced size and computations for low-power edge devices drastically degrades speech quality. Recently, transformer-based architectures have greatly reduced the memory requirements and provided ways to improve the model performance through local and global contexts. However, the transformer operations remain computationally heavy. In this work, we introduce WaveUNet squeeze-excitation Res2 (WSR)-based metric generative adversarial network (WSR-MGAN) architecture that can be efficiently implemented on low-power edge devices for noise suppression tasks while maintaining speech quality. We utilize multi-scale features using Res2Net blocks that can be related to spectral content used in speech-processing tasks. In the generator, we integrate squeeze-excitation blocks (SEB) with multi-scale features for maintaining local and global contexts along with gated recurrent units (GRUs). The proposed approach is optimized through a combined loss function calculated over raw waveform, multi-resolution magnitude spectrogram, and objective metrics using a metric discriminator. Experimental results in terms of various objective metrics on VoiceBank+DEMAND and DNS-2020 challenge datasets demonstrate that the proposed speech enhancement (SE) approach outperforms the baselines and achieves state-of-the-art (SOTA) performance in the time domain.
5/28/2024

Pre-training Feature Guided Diffusion Model for Speech Enhancement
Yiyuan Yang, Niki Trigoni, Andrew Markham
0
0
Speech enhancement significantly improves the clarity and intelligibility of speech in noisy environments, improving communication and listening experiences. In this paper, we introduce a novel pretraining feature-guided diffusion model tailored for efficient speech enhancement, addressing the limitations of existing discriminative and generative models. By integrating spectral features into a variational autoencoder (VAE) and leveraging pre-trained features for guidance during the reverse process, coupled with the utilization of the deterministic discrete integration method (DDIM) to streamline sampling steps, our model improves efficiency and speech enhancement quality. Demonstrating state-of-the-art results on two public datasets with different SNRs, our model outshines other baselines in efficiency and robustness. The proposed method not only optimizes performance but also enhances practical deployment capabilities, without increasing computational demands.
6/13/2024