Unlearning or Concealment? A Critical Analysis and Evaluation Metrics for Unlearning in Diffusion Models

0

Sign in to get full access
Overview
- This paper analyzes the concept of "unlearning" in diffusion models, which aims to remove specific information from a trained model.
- The authors propose a set of evaluation metrics to assess the effectiveness of unlearning approaches.
- They conduct a critical analysis of existing unlearning techniques, highlighting potential issues and areas for further research.
Plain English Explanation
Diffusion models are a type of machine learning algorithm that can generate new data, like images or text, by starting with random noise and gradually transforming it into something meaningful. These models are trained on large datasets, which can lead to them learning and storing unwanted or sensitive information.
The idea of "unlearning" is to remove this unwanted information from the model, so that it no longer generates or reproduces it. However, the authors of this paper argue that simply removing information from a diffusion model may not be as straightforward as it seems. They suggest that the model may be "concealing" the information rather than truly forgetting it, which could lead to the information resurfacing in unexpected ways.
To address this, the authors propose a set of evaluation metrics that can be used to assess the effectiveness of unlearning approaches. These metrics focus on measuring how well the model has truly forgotten the target information, rather than just hiding it.
The paper also provides a critical analysis of existing unlearning techniques, pointing out their potential limitations and areas for further research. For example, the authors suggest that unlearning approaches may have unintended consequences, such as degrading the model's overall performance or introducing biases.
Overall, this paper highlights the complexity of the unlearning problem and the importance of developing robust and reliable methods for removing unwanted information from diffusion models.
Technical Explanation
The paper begins by introducing the concept of unlearning in the context of diffusion models. The authors explain that diffusion models are trained on large datasets, which can lead to them learning and storing unwanted or sensitive information. Unlearning aims to remove this information from the model, so that it no longer generates or reproduces it.
To assess the effectiveness of unlearning approaches, the authors propose a set of evaluation metrics. These metrics focus on measuring how well the model has truly forgotten the target information, rather than just hiding it. The metrics include:
- Internal link: Parametric Knowledge Traces: Examining the model's internal representations to detect the presence of the target information.
- Internal link: Concept Domain Unlearning: Evaluating the model's ability to generate samples that no longer contain the target concept.
- Internal link: Information-Theoretic Metric: Measuring the mutual information between the model's outputs and the target information.
The authors then provide a critical analysis of existing unlearning techniques, highlighting potential issues and areas for further research. For example, they suggest that unlearning approaches may have unintended consequences, such as degrading the model's overall performance or introducing biases.
The paper also discusses the concept of "concealment" as an alternative to true unlearning. The authors argue that a model may be able to "hide" or conceal the target information, rather than truly forgetting it, which could lead to the information resurfacing in unexpected ways.
Critical Analysis
The authors of this paper raise several important points and provide a thoughtful critique of existing unlearning techniques. They highlight the complexity of the unlearning problem and the potential pitfalls of relying on simple removal or suppression of information.
One key concern raised is the possibility of "concealment" rather than true unlearning. The authors suggest that a model may be able to hide or mask the target information, rather than genuinely forgetting it. This could lead to the information resurfacing in unexpected ways, undermining the effectiveness of the unlearning approach.
The authors also note that unlearning techniques may have unintended consequences, such as degrading the model's overall performance or introducing new biases. This is an important consideration, as the goal of unlearning is to remove specific information without compromising the model's broader capabilities.
Additionally, the paper highlights the need for robust and reliable evaluation metrics to assess the effectiveness of unlearning approaches. The authors' proposed metrics, such as Parametric Knowledge Traces and Information-Theoretic Metric, provide a valuable framework for measuring the true extent of unlearning, rather than just surface-level changes.
Overall, this paper serves as a critical and thoughtful examination of the unlearning problem. It raises important questions about the limitations of existing techniques and the need for more nuanced and comprehensive approaches to removing unwanted information from diffusion models.
Conclusion
This paper presents a detailed analysis of the concept of "unlearning" in diffusion models, highlighting the complexities and potential pitfalls of this approach. The authors propose a set of evaluation metrics to assess the effectiveness of unlearning techniques and provide a critical examination of existing methods.
The key takeaways from this paper include the recognition that simply removing information from a diffusion model may not be sufficient, as the model may be able to "conceal" the information rather than truly forgetting it. The authors also emphasize the importance of developing robust and reliable evaluation metrics to ensure that unlearning approaches are genuinely effective.
Overall, this paper contributes to the ongoing discussion around the challenges and best practices for managing unwanted information in machine learning models, particularly in the context of diffusion-based systems. The insights and critiques provided in this paper will be valuable for researchers and practitioners working on developing more reliable and trustworthy AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unlearning or Concealment? A Critical Analysis and Evaluation Metrics for Unlearning in Diffusion Models
Aakash Sen Sharma, Niladri Sarkar, Vikram Chundawat, Ankur A Mali, Murari Mandal
Recent research has seen significant interest in methods for concept removal and targeted forgetting in diffusion models. In this paper, we conduct a comprehensive white-box analysis to expose significant vulnerabilities in existing diffusion model unlearning methods. We show that the objective functions used for unlearning in the existing methods lead to decoupling of the targeted concepts (meant to be forgotten) for the corresponding prompts. This is concealment and not actual unlearning, which was the original goal. The ineffectiveness of current methods stems primarily from their narrow focus on reducing generation probabilities for specific prompt sets, neglecting the diverse modalities of intermediate guidance employed during the inference process. The paper presents a rigorous theoretical and empirical examination of four commonly used techniques for unlearning in diffusion models. We introduce two new evaluation metrics: Concept Retrieval Score (CRS) and Concept Confidence Score (CCS). These metrics are based on a successful adversarial attack setup that can recover forgotten concepts from unlearned diffusion models. The CRS measures the similarity between the latent representations of the unlearned and fully trained models after unlearning. It reports the extent of retrieval of the forgotten concepts with increasing amount of guidance. The CCS quantifies the confidence of the model in assigning the target concept to the manipulated data. It reports the probability of the unlearned model's generations to be aligned with the original domain knowledge with increasing amount of guidance. Evaluating existing unlearning methods with our proposed stringent metrics for diffusion models reveals significant shortcomings in their ability to truly unlearn concepts. Source Code: https://respailab.github.io/unlearning-or-concealment
Read more9/10/2024
0
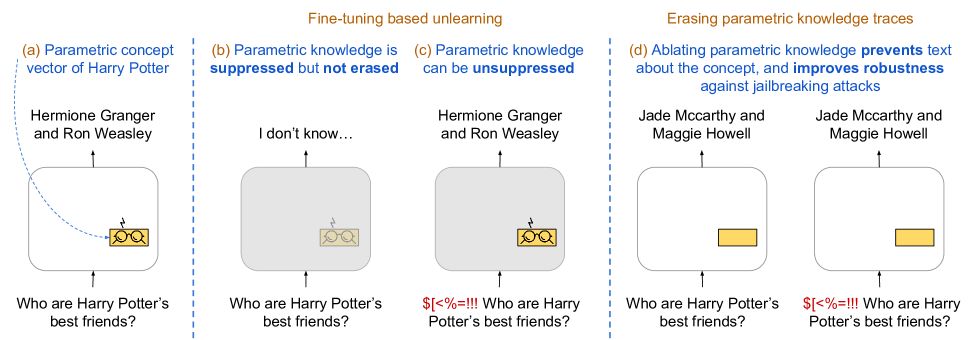
Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces
Yihuai Hong, Lei Yu, Shauli Ravfogel, Haiqin Yang, Mor Geva
The task of unlearning certain concepts in large language models (LLMs) has attracted immense attention recently, due to its importance for mitigating undesirable model behaviours, such as the generation of harmful, private, or incorrect information. Current protocols to evaluate unlearning methods largely rely on behavioral tests, without monitoring the presence of unlearned knowledge within the model's parameters. This residual knowledge can be adversarially exploited to recover the erased information post-unlearning. We argue that unlearning should also be evaluated internally, by considering changes in the parametric knowledge traces of the unlearned concepts. To this end, we propose a general methodology for eliciting directions in the parameter space (termed concept vectors) that encode concrete concepts, and construct ConceptVectors, a benchmark dataset containing hundreds of common concepts and their parametric knowledge traces within two open-source LLMs. Evaluation on ConceptVectors shows that existing unlearning methods minimally impact concept vectors, while directly ablating these vectors demonstrably removes the associated knowledge from the LLMs and significantly reduces their susceptibility to adversarial manipulation. Our results highlight limitations in behavioral-based unlearning evaluations and call for future work to include parametric-based evaluations. To support this, we release our code and benchmark at https://github.com/yihuaihong/ConceptVectors.
Read more6/18/2024
📈
0
Unlearning Concepts in Diffusion Model via Concept Domain Correction and Concept Preserving Gradient
Yongliang Wu, Shiji Zhou, Mingzhuo Yang, Lianzhe Wang, Wenbo Zhu, Heng Chang, Xiao Zhou, Xu Yang
Current text-to-image diffusion models have achieved groundbreaking results in image generation tasks. However, the unavoidable inclusion of sensitive information during pre-training introduces significant risks such as copyright infringement and privacy violations in the generated images. Machine Unlearning (MU) provides a effective way to the sensitive concepts captured by the model, has been shown to be a promising approach to addressing these issues. Nonetheless, existing MU methods for concept erasure encounter two primary bottlenecks: 1) generalization issues, where concept erasure is effective only for the data within the unlearn set, and prompts outside the unlearn set often still result in the generation of sensitive concepts; and 2) utility drop, where erasing target concepts significantly degrades the model's performance. To this end, this paper first proposes a concept domain correction framework for unlearning concepts in diffusion models. By aligning the output domains of sensitive concepts and anchor concepts through adversarial training, we enhance the generalizability of the unlearning results. Secondly, we devise a concept-preserving scheme based on gradient surgery. This approach alleviates the parts of the unlearning gradient that contradict the relearning gradient, ensuring that the process of unlearning minimally disrupts the model's performance. Finally, extensive experiments validate the effectiveness of our model, demonstrating our method's capability to address the challenges of concept unlearning in diffusion models while preserving model utility.
Read more5/27/2024
🔎
0
An Information Theoretic Metric for Evaluating Unlearning Models
Dongjae Jeon, Wonje Jeung, Taeheon Kim, Albert No, Jonghyun Choi
Machine unlearning (MU) addresses privacy concerns by removing information of `forgetting data' samples from trained models. Typically, evaluating MU methods involves comparing unlearned models to those retrained from scratch without forgetting data, using metrics such as membership inference attacks (MIA) and accuracy measurements. These evaluations implicitly assume that if the output logits of the unlearned and retrained models are similar, the unlearned model has successfully forgotten the data. Here, we challenge if this assumption is valid. In particular, we conduct a simple experiment of training only the last layer of a given original model using a novel masked-distillation technique while keeping the rest fixed. Surprisingly, simply altering the last layer yields favorable outcomes in the existing evaluation metrics, while the model does not successfully unlearn the samples or classes. For better evaluating the MU methods, we propose a metric that quantifies the residual information about forgetting data samples in intermediate features using mutual information, called information difference index or IDI for short. The IDI provides a comprehensive evaluation of MU methods by efficiently analyzing the internal structure of DNNs. Our metric is scalable to large datasets and adaptable to various model architectures. Additionally, we present COLapse-and-Align (COLA), a simple contrastive-based method that effectively unlearns intermediate features.
Read more5/29/2024