Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces

0
Sign in to get full access
Overview
- This paper introduces a new method for evaluating the unlearning capabilities of machine learning models, called "Parametric Knowledge Traces."
- The authors argue that existing methods for evaluating unlearning have limitations, and their proposed approach aims to provide a more intrinsic and comprehensive assessment.
- The core idea is to track the evolution of model parameters during the unlearning process and use these "parametric knowledge traces" to measure the extent of unlearning.
Plain English Explanation
Machine learning models can sometimes "remember" or learn things that we don't want them to, like sensitive information or biases. "Unlearning" is the process of removing this unwanted knowledge from the model. Towards Reliable Empirical Machine Unlearning Evaluation and Unlearning Traces: Influential Training Data in Language Models have explored ways to measure how well models can unlearn.
In this paper, the authors propose a new method called "Parametric Knowledge Traces" to evaluate unlearning. The idea is to track how the model's internal parameters (the numbers that define how the model works) change during the unlearning process. By looking at these "traces" of parameter changes, the authors believe they can get a more detailed and accurate picture of how much the model has truly forgotten.
The authors argue that this approach is better than just looking at the model's performance on certain tasks, which is how unlearning is typically evaluated today. Their method can provide a more intrinsic and comprehensive assessment of the unlearning process.
Technical Explanation
The key innovation in this paper is the concept of "Parametric Knowledge Traces" for evaluating machine unlearning. Rather than just looking at the model's performance on certain tasks before and after unlearning, as is typically done, the authors propose tracking the evolution of the model's internal parameters throughout the unlearning process.
The authors argue that this approach provides a more detailed and accurate picture of the unlearning process. By analyzing these "parametric knowledge traces," they can gain insights into how much of the model's original knowledge has truly been forgotten, rather than just relying on coarse performance metrics.
The authors demonstrate their method on several machine learning models and unlearning scenarios, including Rethinking Machine Unlearning in Large Language Models, Unlearning Control: Assessing the Real-World Utility of Large Language Model Unlearning, and Are We Making Progress on Unlearning? Findings from Large Language Models. Their results show that parametric knowledge traces can provide valuable insights that are not captured by standard unlearning evaluations.
Critical Analysis
One potential limitation of the parametric knowledge trace approach is that it requires access to the internal model parameters, which may not always be practical or possible, especially for large, complex models. The authors acknowledge this and discuss potential workarounds, but this could still be a barrier to widespread adoption.
Additionally, the interpretability and meaningfulness of the parametric knowledge traces may vary depending on the model architecture and the specific unlearning task. The authors do not explore this issue in depth, and further research may be needed to understand the strengths and limitations of their approach across different scenarios.
It's also worth noting that while parametric knowledge traces can provide a more intrinsic view of the unlearning process, they don't necessarily translate directly to real-world utility or impact. The authors acknowledge this and encourage further research to connect their findings to practical implications.
Conclusion
This paper introduces a novel approach for evaluating machine unlearning called "Parametric Knowledge Traces." By tracking the evolution of a model's internal parameters during the unlearning process, the authors argue that this method can provide a more comprehensive and intrinsic assessment of how much a model has truly forgotten.
The authors demonstrate the potential of their approach through several case studies, showing that parametric knowledge traces can reveal insights not captured by standard unlearning evaluations. While there are some limitations to consider, this work represents an important step forward in understanding and measuring the unlearning capabilities of machine learning models.
As machine learning systems become more pervasive and influential, the ability to reliably unlearn unwanted knowledge will only become more critical. The ideas presented in this paper could help pave the way for more robust and trustworthy machine learning models that can adapt and evolve without retaining harmful or sensitive information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Intrinsic Evaluation of Unlearning Using Parametric Knowledge Traces
Yihuai Hong, Lei Yu, Shauli Ravfogel, Haiqin Yang, Mor Geva
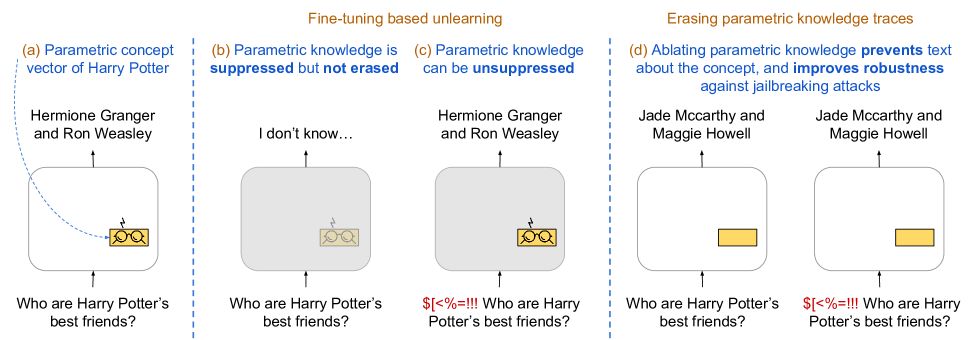
The task of unlearning certain concepts in large language models (LLMs) has attracted immense attention recently, due to its importance for mitigating undesirable model behaviours, such as the generation of harmful, private, or incorrect information. Current protocols to evaluate unlearning methods largely rely on behavioral tests, without monitoring the presence of unlearned knowledge within the model's parameters. This residual knowledge can be adversarially exploited to recover the erased information post-unlearning. We argue that unlearning should also be evaluated internally, by considering changes in the parametric knowledge traces of the unlearned concepts. To this end, we propose a general methodology for eliciting directions in the parameter space (termed concept vectors) that encode concrete concepts, and construct ConceptVectors, a benchmark dataset containing hundreds of common concepts and their parametric knowledge traces within two open-source LLMs. Evaluation on ConceptVectors shows that existing unlearning methods minimally impact concept vectors, while directly ablating these vectors demonstrably removes the associated knowledge from the LLMs and significantly reduces their susceptibility to adversarial manipulation. Our results highlight limitations in behavioral-based unlearning evaluations and call for future work to include parametric-based evaluations. To support this, we release our code and benchmark at https://github.com/yihuaihong/ConceptVectors.
Read more6/18/2024

0
Unlearning or Concealment? A Critical Analysis and Evaluation Metrics for Unlearning in Diffusion Models
Aakash Sen Sharma, Niladri Sarkar, Vikram Chundawat, Ankur A Mali, Murari Mandal
Recent research has seen significant interest in methods for concept removal and targeted forgetting in diffusion models. In this paper, we conduct a comprehensive white-box analysis to expose significant vulnerabilities in existing diffusion model unlearning methods. We show that the objective functions used for unlearning in the existing methods lead to decoupling of the targeted concepts (meant to be forgotten) for the corresponding prompts. This is concealment and not actual unlearning, which was the original goal. The ineffectiveness of current methods stems primarily from their narrow focus on reducing generation probabilities for specific prompt sets, neglecting the diverse modalities of intermediate guidance employed during the inference process. The paper presents a rigorous theoretical and empirical examination of four commonly used techniques for unlearning in diffusion models. We introduce two new evaluation metrics: Concept Retrieval Score (CRS) and Concept Confidence Score (CCS). These metrics are based on a successful adversarial attack setup that can recover forgotten concepts from unlearned diffusion models. The CRS measures the similarity between the latent representations of the unlearned and fully trained models after unlearning. It reports the extent of retrieval of the forgotten concepts with increasing amount of guidance. The CCS quantifies the confidence of the model in assigning the target concept to the manipulated data. It reports the probability of the unlearned model's generations to be aligned with the original domain knowledge with increasing amount of guidance. Evaluating existing unlearning methods with our proposed stringent metrics for diffusion models reveals significant shortcomings in their ability to truly unlearn concepts. Source Code: https://respailab.github.io/unlearning-or-concealment
Read more9/10/2024
0
Towards Reliable Empirical Machine Unlearning Evaluation: A Game-Theoretic View
Yiwen Tu, Pingbang Hu, Jiaqi Ma
Machine unlearning is the process of updating machine learning models to remove the information of specific training data samples, in order to comply with data protection regulations that allow individuals to request the removal of their personal data. Despite the recent development of numerous unlearning algorithms, reliable evaluation of these algorithms remains an open research question. In this work, we focus on membership inference attack (MIA) based evaluation, one of the most common approaches for evaluating unlearning algorithms, and address various pitfalls of existing evaluation metrics that lack reliability. Specifically, we propose a game-theoretic framework that formalizes the evaluation process as a game between unlearning algorithms and MIA adversaries, measuring the data removal efficacy of unlearning algorithms by the capability of the MIA adversaries. Through careful design of the game, we demonstrate that the natural evaluation metric induced from the game enjoys provable guarantees that the existing evaluation metrics fail to satisfy. Furthermore, we propose a practical and efficient algorithm to estimate the evaluation metric induced from the game, and demonstrate its effectiveness through both theoretical analysis and empirical experiments. This work presents a novel and reliable approach to empirically evaluating unlearning algorithms, paving the way for the development of more effective unlearning techniques.
Read more6/13/2024

0
Rethinking Machine Unlearning for Large Language Models
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, Kush R. Varshney, Mohit Bansal, Sanmi Koyejo, Yang Liu
We explore machine unlearning (MU) in the domain of large language models (LLMs), referred to as LLM unlearning. This initiative aims to eliminate undesirable data influence (e.g., sensitive or illegal information) and the associated model capabilities, while maintaining the integrity of essential knowledge generation and not affecting causally unrelated information. We envision LLM unlearning becoming a pivotal element in the life-cycle management of LLMs, potentially standing as an essential foundation for developing generative AI that is not only safe, secure, and trustworthy, but also resource-efficient without the need of full retraining. We navigate the unlearning landscape in LLMs from conceptual formulation, methodologies, metrics, and applications. In particular, we highlight the often-overlooked aspects of existing LLM unlearning research, e.g., unlearning scope, data-model interaction, and multifaceted efficacy assessment. We also draw connections between LLM unlearning and related areas such as model editing, influence functions, model explanation, adversarial training, and reinforcement learning. Furthermore, we outline an effective assessment framework for LLM unlearning and explore its applications in copyright and privacy safeguards and sociotechnical harm reduction.
Read more7/16/2024