Unleashing the Power of Meta-tuning for Few-shot Generalization Through Sparse Interpolated Experts
2403.08477
0
0

Abstract
Recent successes suggest that parameter-efficient fine-tuning of foundation models as the state-of-the-art method for transfer learning in vision, replacing the rich literature of alternatives such as meta-learning. In trying to harness the best of both worlds, meta-tuning introduces a subsequent optimization stage of foundation models but has so far only shown limited success and crucially tends to underperform on out-of-distribution (OOD) tasks. In this paper, we introduce Sparse MetA-Tuning (SMAT), a method inspired by sparse mixture-of-experts approaches and trained to isolate subsets of pre-trained parameters automatically for meta-tuning on each task. SMAT successfully overcomes OOD sensitivity and delivers on the promise of enhancing the transfer abilities of vision foundation models beyond parameter-efficient fine-tuning. We establish new state-of-the-art results on a challenging combination of Meta-Dataset augmented with additional OOD tasks in both zero-shot and gradient-based adaptation settings. In addition, we provide a thorough analysis of the superiority of learned over hand-designed sparsity patterns for sparse expert methods and the pivotal importance of the sparsity level in balancing between in-distribution and out-of-distribution generalization. Our code is publicly available.
Create account to get full access
Overview
- This paper proposes a novel meta-tuning approach called "SMAT" (Sparse MetA-Tuning) to achieve few-shot generalization.
- SMAT leverages a sparse mixture of experts model to efficiently fine-tune a large language model on diverse tasks.
- The key idea is to learn a small number of specialized "expert" sub-models that can be dynamically combined to adapt the model to new tasks.
- This sparse and modular architecture allows for faster and more efficient fine-tuning compared to standard fine-tuning approaches.
Plain English Explanation
The paper introduces a new technique called "SMAT" (Sparse MetA-Tuning) that aims to make it easier for AI models to adapt to new tasks with only a small amount of training data. This is an important challenge, as many real-world applications require models to work well on new tasks without extensive retraining.
The core idea behind SMAT is to create a set of specialized "expert" sub-models that can be selectively combined to quickly adapt the main AI model to a new task. Instead of fine-tuning the entire model, SMAT only updates a sparse subset of the parameters, making the process more efficient.
To do this, SMAT learns a small number of these expert sub-models during an initial training phase. When faced with a new task, the model can then intelligently select and combine the relevant experts to achieve good performance with only a few training examples. This allows the model to "meta-tune" itself to the new task in a more targeted and efficient way.
The authors show that SMAT outperforms standard fine-tuning approaches on a variety of few-shot learning benchmarks, demonstrating its potential to enable more flexible and data-efficient AI systems.
Technical Explanation
The key innovation in SMAT is the use of a sparse matrix-based mixture of experts architecture. During the meta-training phase, SMAT learns a set of specialized "expert" sub-models that can each handle different aspects of the learning tasks.
Rather than updating all the parameters of the main model when adapting to a new task, SMAT selectively updates only the relevant expert sub-models. This sparse fine-tuning approach allows for faster and more efficient adaptation compared to standard fine-tuning.
The expert sub-models are combined using a learned gating network, which determines the appropriate mixture of experts to apply for a given task. This mixture of experts architecture enables SMAT to efficiently leverage a small number of specialized sub-models to handle a diverse range of learning tasks.
The authors demonstrate the effectiveness of SMAT on several few-shot learning benchmarks, showing that it can outperform standard fine-tuning approaches by a significant margin. This suggests that the sparse and modular nature of the SMAT architecture can be a powerful tool for enabling flexible and data-efficient AI systems.
Critical Analysis
The SMAT approach presented in this paper is a promising step towards more efficient and adaptable AI systems. By leveraging a sparse mixture of experts, the model can rapidly fine-tune to new tasks without having to update all of its parameters.
However, the paper does not address some potential limitations of this approach. For example, it's unclear how well SMAT would scale to an extremely large number of tasks or experts, as the complexity of the gating network could become unwieldy. There may also be challenges in ensuring that the experts remain sufficiently specialized and non-overlapping as the model is trained on more diverse data.
Additionally, the authors do not explore potential negative societal impacts of this technology, such as concerns around the transparency and interpretability of these complex, modular AI systems. Sparse is Enough: Fine-Tuning Pre-Trained Transformers for Few-Shot Learning and Sparse Matrix-Based Large Language Model Fine-Tuning may provide further insights into these issues.
Overall, the SMAT approach represents an interesting and potentially valuable contribution to the field of few-shot learning. However, further research is needed to fully understand its strengths, limitations, and societal implications.
Conclusion
The SMAT (Sparse MetA-Tuning) approach proposed in this paper is a novel technique for enabling few-shot generalization in AI models. By leveraging a sparse mixture of expert sub-models, SMAT can efficiently fine-tune a large language model to adapt to new tasks with only a small amount of training data.
The key innovation of SMAT is its ability to selectively update only the relevant expert sub-models during fine-tuning, rather than updating the entire model. This sparse and modular architecture allows for faster and more efficient adaptation compared to standard fine-tuning approaches.
The authors demonstrate the effectiveness of SMAT on several few-shot learning benchmarks, showing that it can outperform existing methods. This suggests that the SMAT approach has the potential to enable more flexible and data-efficient AI systems that can be rapidly deployed in a wide range of real-world applications.
While the SMAT approach is promising, further research is needed to fully understand its limitations and potential societal implications. Nonetheless, this work represents an important step forward in the field of few-shot learning and meta-learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Sparse is Enough in Fine-tuning Pre-trained Large Language Models
Weixi Song, Zuchao Li, Lefei Zhang, Hai Zhao, Bo Du
0
0
With the prevalence of pre-training-fine-tuning paradigm, how to efficiently adapt the pre-trained model to the downstream tasks has been an intriguing issue. Parameter-Efficient Fine-Tuning (PEFT) methods have been proposed for low-cost adaptation. Although PEFT has demonstrated effectiveness and been widely applied, the underlying principles are still unclear. In this paper, we adopt the PAC-Bayesian generalization error bound, viewing pre-training as a shift of prior distribution which leads to a tighter bound for generalization error. We validate this shift from the perspectives of oscillations in the loss landscape and the quasi-sparsity in gradient distribution. Based on this, we propose a gradient-based sparse fine-tuning algorithm, named Sparse Increment Fine-Tuning (SIFT), and validate its effectiveness on a range of tasks including the GLUE Benchmark and Instruction-tuning. The code is accessible at https://github.com/song-wx/SIFT/.
6/11/2024
🔍
Omni-SMoLA: Boosting Generalist Multimodal Models with Soft Mixture of Low-rank Experts
Jialin Wu, Xia Hu, Yaqing Wang, Bo Pang, Radu Soricut
0
0
Large multi-modal models (LMMs) exhibit remarkable performance across numerous tasks. However, generalist LMMs often suffer from performance degradation when tuned over a large collection of tasks. Recent research suggests that Mixture of Experts (MoE) architectures are useful for instruction tuning, but for LMMs of parameter size around O(50-100B), the prohibitive cost of replicating and storing the expert models severely limits the number of experts we can use. We propose Omni-SMoLA, an architecture that uses the Soft MoE approach to (softly) mix many multimodal low rank experts, and avoids introducing a significant number of new parameters compared to conventional MoE models. The core intuition here is that the large model provides a foundational backbone, while different lightweight experts residually learn specialized knowledge, either per-modality or multimodally. Extensive experiments demonstrate that the SMoLA approach helps improve the generalist performance across a broad range of generative vision-and-language tasks, achieving new SoTA generalist performance that often matches or outperforms single specialized LMM baselines, as well as new SoTA specialist performance.
4/4/2024
🔄
Dynamic Mixture of Experts: An Auto-Tuning Approach for Efficient Transformer Models
Yongxin Guo, Zhenglin Cheng, Xiaoying Tang, Tao Lin
0
0
The Sparse Mixture of Experts (SMoE) has been widely employed to enhance the efficiency of training and inference for Transformer-based foundational models, yielding promising results. However, the performance of SMoE heavily depends on the choice of hyper-parameters, such as the number of experts and the number of experts to be activated (referred to as top-k), resulting in significant computational overhead due to the extensive model training by searching over various hyper-parameter configurations. As a remedy, we introduce the Dynamic Mixture of Experts (DynMoE) technique. DynMoE incorporates (1) a novel gating method that enables each token to automatically determine the number of experts to activate. (2) An adaptive process automatically adjusts the number of experts during training. Extensive numerical results across Vision, Language, and Vision-Language tasks demonstrate the effectiveness of our approach to achieve competitive performance compared to GMoE for vision and language tasks, and MoE-LLaVA for vision-language tasks, while maintaining efficiency by activating fewer parameters. Our code is available at https://github.com/LINs-lab/DynMoE.
5/24/2024
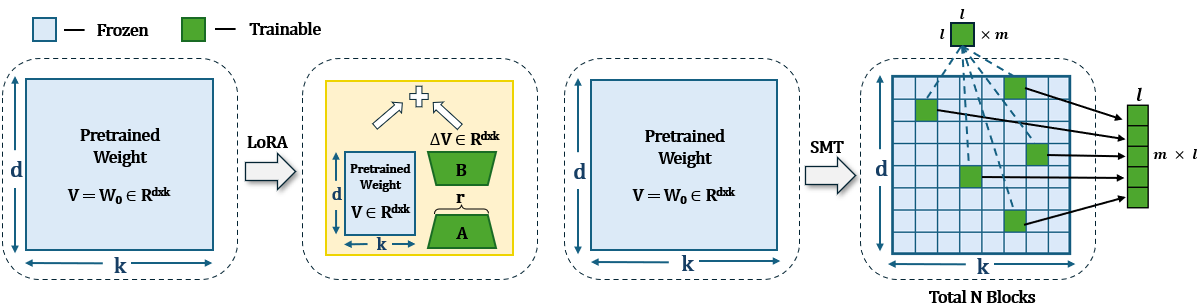
Sparse Matrix in Large Language Model Fine-tuning
Haoze He, Juncheng Billy Li, Xuan Jiang, Heather Miller
0
0
LoRA and its variants have become popular parameter-efficient fine-tuning (PEFT) methods due to their ability to avoid excessive computational costs. However, an accuracy gap often exists between PEFT methods and full fine-tuning (FT), and this gap has yet to be systematically studied. In this work, we introduce a method for selecting sparse sub-matrices that aim to minimize the performance gap between PEFT vs. full fine-tuning (FT) while also reducing both fine-tuning computational cost and memory cost. Our Sparse Matrix Tuning (SMT) method begins by identifying the most significant sub-matrices in the gradient update, updating only these blocks during the fine-tuning process. In our experiments, we demonstrate that SMT consistently surpasses other PEFT baseline (e.g. LoRA and DoRA) in fine-tuning popular large language models such as LLaMA across a broad spectrum of tasks, while reducing the GPU memory footprint by 67% compared to FT. We also examine how the performance of LoRA and DoRA tends to plateau and decline as the number of trainable parameters increases, in contrast, our SMT method does not suffer from such issue.
5/31/2024