Unlocking Memorization in Large Language Models with Dynamic Soft Prompting

0

Sign in to get full access
Overview
- Large language models (LLMs) have shown impressive capabilities, but struggle with memorization and retrieval of specific facts.
- This paper explores a technique called "dynamic soft prompting" to unlock the memorization abilities of LLMs.
- The approach allows LLMs to dynamically adjust their responses based on prompts, improving their ability to recall and apply memorized information.
Plain English Explanation
Unlocking Memorization in Large Language Models with Dynamic Soft Prompting investigates a method to help large language models (LLMs) better remember and use specific information. LLMs, such as GPT-3, are incredibly capable at understanding and generating human-like text. However, they can struggle to recall and apply precise facts or details that have been memorized.
The researchers propose a technique called "dynamic soft prompting" to address this challenge. This approach allows the LLM to dynamically adjust its responses based on the prompts it receives. By modifying the prompts, the model can more effectively retrieve and apply the information it has memorized, rather than relying solely on its general language understanding abilities.
For example, imagine an LLM that has memorized the capital of France is Paris. With dynamic soft prompting, the model could be prompted with "The capital of France is [BLANK]" and respond with "Paris", demonstrating its ability to recall and apply this specific piece of information. This contrasts with a more general prompt like "What is the capital of France?", where the model might struggle to retrieve the exact fact.
The key idea is that the dynamic soft prompting technique gives the LLM a way to access its internal memory and apply the information it has learned, rather than just generating text based on broad language patterns. This could be particularly useful for applications that require precise, factual responses, such as question-answering systems or knowledge-intensive tasks.
Technical Explanation
Unlocking Memorization in Large Language Models with Dynamic Soft Prompting presents a novel technique called "dynamic soft prompting" to improve the ability of large language models (LLMs) to retrieve and apply memorized information.
The researchers observe that while LLMs like GPT-3 have shown impressive capabilities in understanding and generating human-like text, they often struggle with memorization and retrieval of specific facts or details. To address this, the authors introduce dynamic soft prompting, which allows the LLM to dynamically adjust its responses based on the prompts it receives.
The core idea behind dynamic soft prompting is to provide the LLM with a prompt that contains a placeholder or "mask" where the model is expected to fill in the correct memorized information. By adjusting the prompts in this way, the LLM can more effectively retrieve and apply the specific facts or details it has learned, rather than relying solely on its broad language understanding capabilities.
The authors evaluate their approach on a range of benchmark tasks, including factual question-answering, commonsense reasoning, and knowledge-intensive language understanding. Their results demonstrate that dynamic soft prompting significantly outperforms standard prompting techniques, allowing the LLM to better leverage its memorized knowledge to provide accurate and relevant responses.
Furthermore, the authors analyze the inner workings of their approach, shedding light on how the dynamic soft prompting mechanism enables the LLM to access and utilize its internal memory more effectively. They also discuss potential limitations and future research directions, such as scaling the technique to larger datasets and exploring its applicability to other types of language models.
Critical Analysis
The paper "Unlocking Memorization in Large Language Models with Dynamic Soft Prompting" presents a promising approach to address the challenge of improving the memorization and retrieval capabilities of large language models (LLMs). The proposed dynamic soft prompting technique is a novel and well-designed solution that leverages the LLM's internal memory to provide more accurate and factual responses.
One strength of the research is the comprehensive evaluation on a diverse set of benchmark tasks, which demonstrates the broad applicability of the dynamic soft prompting method. The authors' analysis of the inner workings of the technique also provides valuable insights into how it enables the LLM to access and utilize its memorized knowledge more effectively.
However, the paper does not address potential limitations or caveats of the approach. For instance, it would be interesting to understand how the dynamic soft prompting mechanism scales to larger datasets or more complex memorization tasks, and whether there are any limitations in terms of the types of information that can be effectively retrieved.
Additionally, the paper does not discuss potential ethical considerations or societal implications of improving the memorization capabilities of LLMs. As these models become increasingly capable and integrated into various applications, it will be important to carefully consider the potential risks and mitigate any unintended consequences.
Overall, the research presented in this paper represents a significant contribution to the field of language model development and opens up new avenues for further exploration. By focusing on enhancing the memorization and retrieval abilities of LLMs, the authors have taken an important step towards unlocking the full potential of these powerful models.
Conclusion
Unlocking Memorization in Large Language Models with Dynamic Soft Prompting introduces a novel technique called "dynamic soft prompting" to improve the ability of large language models (LLMs) to retrieve and apply memorized information. The key insight is that by providing the LLM with prompts that contain placeholders or masks for the expected memorized information, the model can more effectively access its internal memory and provide accurate, fact-based responses.
The authors' comprehensive evaluation and analysis demonstrate the effectiveness of their approach, which significantly outperforms standard prompting techniques on a range of benchmark tasks. This research represents an important step forward in enhancing the memorization capabilities of LLMs, paving the way for more reliable and knowledge-intensive applications of these powerful models.
While the paper does not address potential limitations or ethical considerations, it opens up exciting future research directions. Exploring how dynamic soft prompting scales to larger datasets, assessing its applicability to other types of language models, and carefully considering the societal implications of improved memorization in LLMs are all important areas for further investigation.
Overall, this work represents a valuable contribution to the field of natural language processing and artificial intelligence, offering a promising solution to the long-standing challenge of unlocking the memorization potential of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unlocking Memorization in Large Language Models with Dynamic Soft Prompting
Zhepeng Wang, Runxue Bao, Yawen Wu, Jackson Taylor, Cao Xiao, Feng Zheng, Weiwen Jiang, Shangqian Gao, Yanfu Zhang
Pretrained large language models (LLMs) have revolutionized natural language processing (NLP) tasks such as summarization, question answering, and translation. However, LLMs pose significant security risks due to their tendency to memorize training data, leading to potential privacy breaches and copyright infringement. Accurate measurement of this memorization is essential to evaluate and mitigate these potential risks. However, previous attempts to characterize memorization are constrained by either using prefixes only or by prepending a constant soft prompt to the prefixes, which cannot react to changes in input. To address this challenge, we propose a novel method for estimating LLM memorization using dynamic, prefix-dependent soft prompts. Our approach involves training a transformer-based generator to produce soft prompts that adapt to changes in input, thereby enabling more accurate extraction of memorized data. Our method not only addresses the limitations of previous methods but also demonstrates superior performance in diverse experimental settings compared to state-of-the-art techniques. In particular, our method can achieve the maximum relative improvement of 112.75% and 32.26% over the vanilla baseline in terms of discoverable memorization rate for the text generation task and code generation task respectively.
Read more9/24/2024
0
Exploring prompts to elicit memorization in masked language model-based named entity recognition
Yuxi Xia, Anastasiia Sedova, Pedro Henrique Luz de Araujo, Vasiliki Kougia, Lisa Nu{ss}baumer, Benjamin Roth
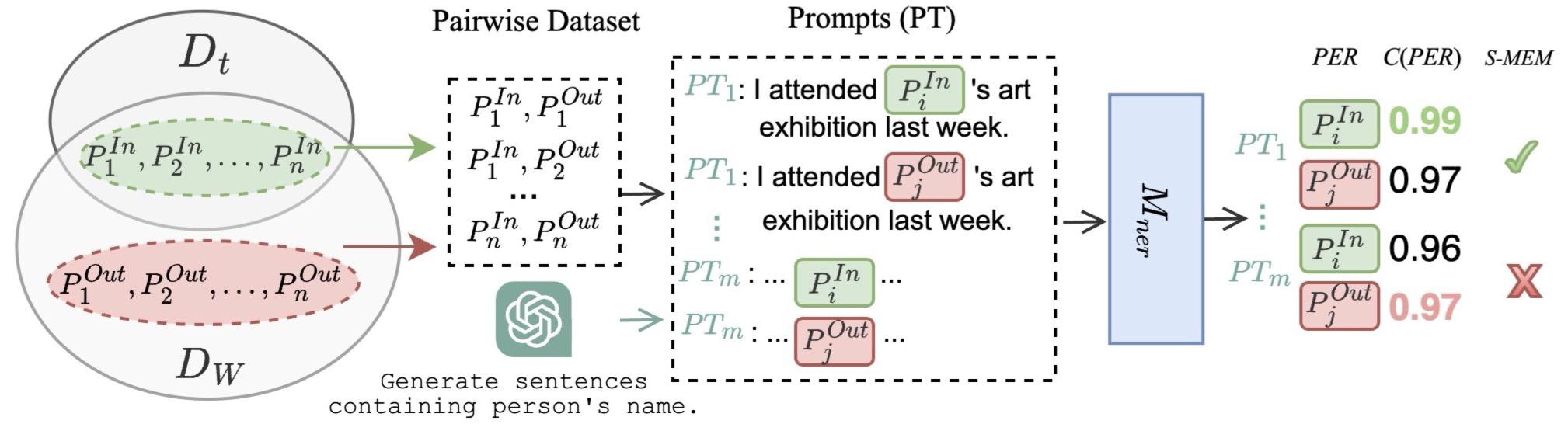
Training data memorization in language models impacts model capability (generalization) and safety (privacy risk). This paper focuses on analyzing prompts' impact on detecting the memorization of 6 masked language model-based named entity recognition models. Specifically, we employ a diverse set of 400 automatically generated prompts, and a pairwise dataset where each pair consists of one person's name from the training set and another name out of the set. A prompt completed with a person's name serves as input for getting the model's confidence in predicting this name. Finally, the prompt performance of detecting model memorization is quantified by the percentage of name pairs for which the model has higher confidence for the name from the training set. We show that the performance of different prompts varies by as much as 16 percentage points on the same model, and prompt engineering further increases the gap. Moreover, our experiments demonstrate that prompt performance is model-dependent but does generalize across different name sets. A comprehensive analysis indicates how prompt performance is influenced by prompt properties, contained tokens, and the model's self-attention weights on the prompt.
Read more5/7/2024
0
Soft Prompting for Unlearning in Large Language Models
Karuna Bhaila, Minh-Hao Van, Xintao Wu
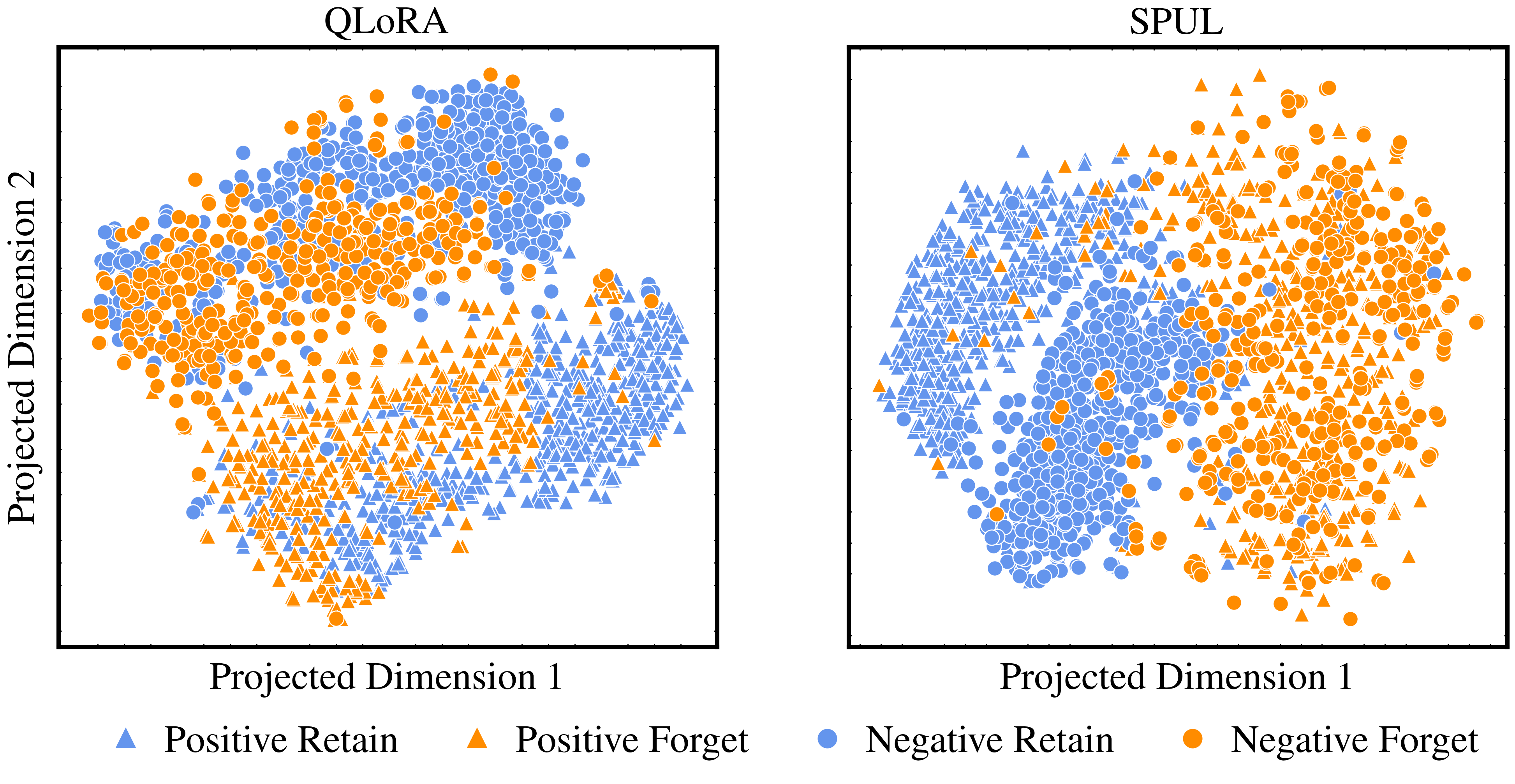
The widespread popularity of Large Language Models (LLMs), partly due to their unique ability to perform in-context learning, has also brought to light the importance of ethical and safety considerations when deploying these pre-trained models. In this work, we focus on investigating machine unlearning for LLMs motivated by data protection regulations. In contrast to the growing literature on fine-tuning methods to achieve unlearning, we focus on a comparatively lightweight alternative called soft prompting to realize the unlearning of a subset of training data. With losses designed to enforce forgetting as well as utility preservation, our framework textbf{S}oft textbf{P}rompting for textbf{U}ntextbf{l}earning (SPUL) learns prompt tokens that can be appended to an arbitrary query to induce unlearning of specific examples at inference time without updating LLM parameters. We conduct a rigorous evaluation of the proposed method and our results indicate that SPUL can significantly improve the trade-off between utility and forgetting in the context of text classification and question answering with LLMs. We further validate our method using multiple LLMs to highlight the scalability of our framework and provide detailed insights into the choice of hyperparameters and the influence of the size of unlearning data. Our implementation is available at url{https://github.com/karuna-bhaila/llm_unlearning}.
Read more8/7/2024
0
FastMem: Fast Memorization of Prompt Improves Context Awareness of Large Language Models
Junyi Zhu, Shuochen Liu, Yu Yu, Bo Tang, Yibo Yan, Zhiyu Li, Feiyu Xiong, Tong Xu, Matthew B. Blaschko
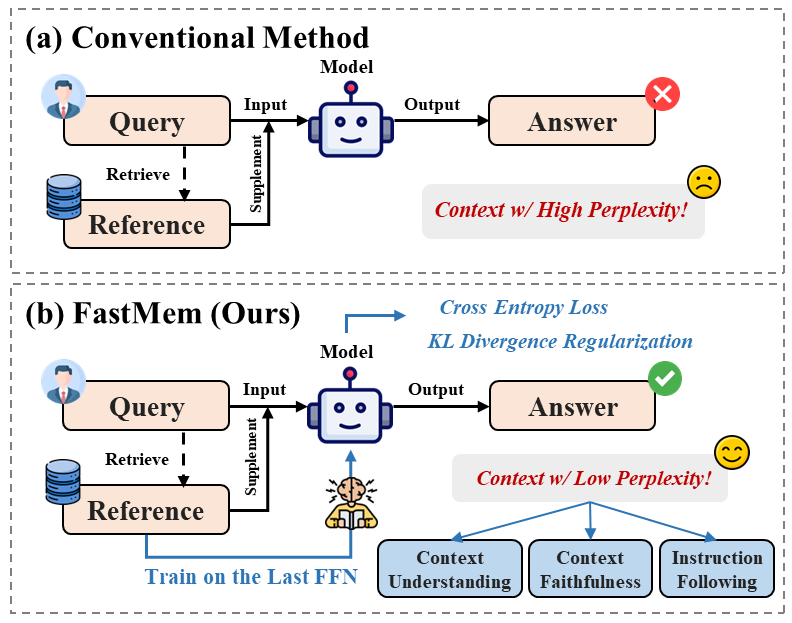
Large language models (LLMs) excel in generating coherent text, but they often struggle with context awareness, leading to inaccuracies in tasks requiring faithful adherence to provided information. We introduce FastMem, a novel method designed to enhance instruction fine-tuned LLMs' context awareness through fast memorization of the prompt. FastMem maximizes the likelihood of the prompt before inference by fine-tuning only the last Feed-Forward Network (FFN) module. This targeted approach ensures efficient optimization without overfitting, significantly improving the model's ability to comprehend and accurately follow the context. Our experiments demonstrate substantial gains in reading comprehension, text summarization and adherence to output structures. For instance, FastMem improves the accuracy of Llama 3-8B-Inst on the NQ-SWAP dataset from 59.1% to 71.6%, and reduces the output structure failure rate of Qwen 1.5-4B-Chat from 34.9% to 25.5%. Extensive experimental results highlight FastMem's potential to offer a robust solution to enhance the reliability and accuracy of LLMs in various applications. Our code is available at: https://github.com/IAAR-Shanghai/FastMem
Read more9/4/2024