FastMem: Fast Memorization of Prompt Improves Context Awareness of Large Language Models

0
Sign in to get full access
Overview
- The paper proposes a technique called "FastMem" to improve the context awareness of large language models (LLMs) by enabling fast memorization of prompts.
- FastMem allows LLMs to quickly remember and reuse relevant information from previous interactions, enhancing their ability to maintain context and provide more coherent responses.
- The technique is inspired by recent advancements in memory-sharing, prompt caching, and efficient context processing for LLMs.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can engage in human-like conversations and perform a wide range of tasks. However, these models can sometimes struggle to maintain context and provide coherent responses, especially when dealing with long or complex interactions.
The FastMem technique aims to address this issue by allowing LLMs to quickly remember and reuse relevant information from previous interactions. This is similar to how humans can quickly recall relevant details when having a conversation, which helps us stay focused and provide more meaningful responses.
By enabling LLMs to "memorize" prompts and reuse that information, FastMem can enhance the models' context awareness and their ability to have more natural, coherent conversations. This can be particularly useful in applications where maintaining context is important, such as virtual assistants or self-updatable language models.
Technical Explanation
The FastMem technique works by creating a dedicated "fast memory" module within the LLM architecture. This module is responsible for quickly storing and retrieving relevant information from previous interactions, such as key details, context, and the model's own internal state.
When a new prompt is received, the FastMem module first checks if it can find any relevant information in the fast memory. If so, it can quickly retrieve and incorporate that information into the model's response, helping to maintain context and provide more coherent output.
The authors of the paper evaluate FastMem on several benchmark tasks and find that it can significantly improve the context awareness and response quality of LLMs, particularly in long-form conversations and multi-step tasks. The technique is shown to be effective with different LLM architectures and can be easily integrated into existing models.
Critical Analysis
The FastMem technique is a promising approach to improving the context awareness of LLMs, but it does have some potential limitations and areas for further research:
- The paper does not provide a detailed analysis of the computational and memory overhead of the FastMem module, which could be an important consideration for real-world deployment.
- The evaluation is focused on academic benchmarks, and more research may be needed to understand the real-world performance and practical applications of FastMem.
- The paper does not explore the potential for adversarial attacks or biases that could arise from the FastMem module, which is an important consideration for the responsible development of LLMs.
Overall, the FastMem technique represents an interesting and potentially impactful contribution to the field of large language models. However, as with any new technology, it is important to consider the potential risks and limitations, and to continue researching ways to improve the safety, robustness, and real-world applicability of these systems.
Conclusion
The FastMem technique proposed in this paper is a novel approach to enhancing the context awareness of large language models. By enabling LLMs to quickly memorize and reuse relevant information from previous interactions, FastMem can help these models maintain coherence and provide more meaningful responses, particularly in long-form conversations and multi-step tasks.
The findings of the paper suggest that this technique could have significant implications for the development of more advanced and user-friendly language models, with potential applications in areas such as virtual assistants, conversational AI, and self-updatable language models. As the field of large language models continues to evolve, techniques like FastMem may play an increasingly important role in enhancing the context awareness and real-world applicability of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FastMem: Fast Memorization of Prompt Improves Context Awareness of Large Language Models
Junyi Zhu, Shuochen Liu, Yu Yu, Bo Tang, Yibo Yan, Zhiyu Li, Feiyu Xiong, Tong Xu, Matthew B. Blaschko
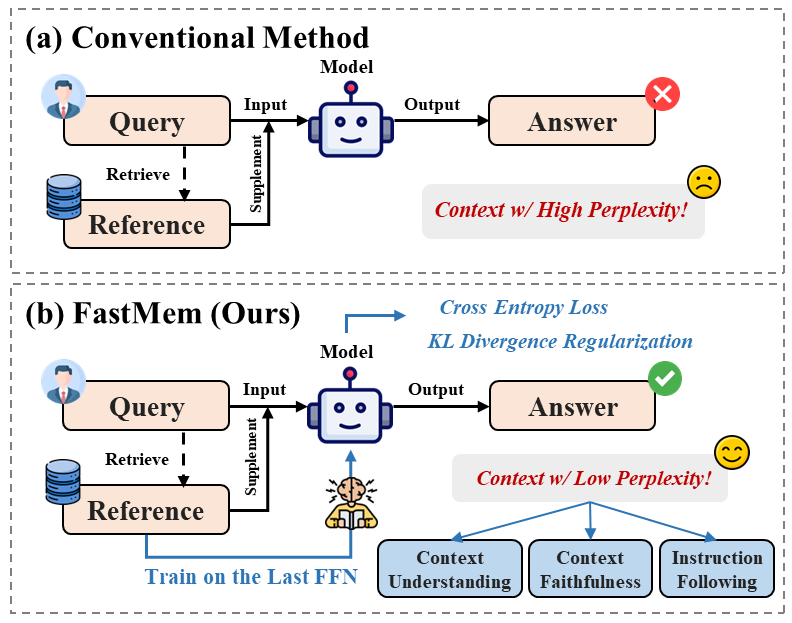
Large language models (LLMs) excel in generating coherent text, but they often struggle with context awareness, leading to inaccuracies in tasks requiring faithful adherence to provided information. We introduce FastMem, a novel method designed to enhance instruction fine-tuned LLMs' context awareness through fast memorization of the prompt. FastMem maximizes the likelihood of the prompt before inference by fine-tuning only the last Feed-Forward Network (FFN) module. This targeted approach ensures efficient optimization without overfitting, significantly improving the model's ability to comprehend and accurately follow the context. Our experiments demonstrate substantial gains in reading comprehension, text summarization and adherence to output structures. For instance, FastMem improves the accuracy of Llama 3-8B-Inst on the NQ-SWAP dataset from 59.1% to 71.6%, and reduces the output structure failure rate of Qwen 1.5-4B-Chat from 34.9% to 25.5%. Extensive experimental results highlight FastMem's potential to offer a robust solution to enhance the reliability and accuracy of LLMs in various applications. Our code is available at: https://github.com/IAAR-Shanghai/FastMem
Read more9/4/2024

0
Unlocking Memorization in Large Language Models with Dynamic Soft Prompting
Zhepeng Wang, Runxue Bao, Yawen Wu, Jackson Taylor, Cao Xiao, Feng Zheng, Weiwen Jiang, Shangqian Gao, Yanfu Zhang
Pretrained large language models (LLMs) have revolutionized natural language processing (NLP) tasks such as summarization, question answering, and translation. However, LLMs pose significant security risks due to their tendency to memorize training data, leading to potential privacy breaches and copyright infringement. Accurate measurement of this memorization is essential to evaluate and mitigate these potential risks. However, previous attempts to characterize memorization are constrained by either using prefixes only or by prepending a constant soft prompt to the prefixes, which cannot react to changes in input. To address this challenge, we propose a novel method for estimating LLM memorization using dynamic, prefix-dependent soft prompts. Our approach involves training a transformer-based generator to produce soft prompts that adapt to changes in input, thereby enabling more accurate extraction of memorized data. Our method not only addresses the limitations of previous methods but also demonstrates superior performance in diverse experimental settings compared to state-of-the-art techniques. In particular, our method can achieve the maximum relative improvement of 112.75% and 32.26% over the vanilla baseline in terms of discoverable memorization rate for the text generation task and code generation task respectively.
Read more9/24/2024
0
Memory Sharing for Large Language Model based Agents
Hang Gao, Yongfeng Zhang
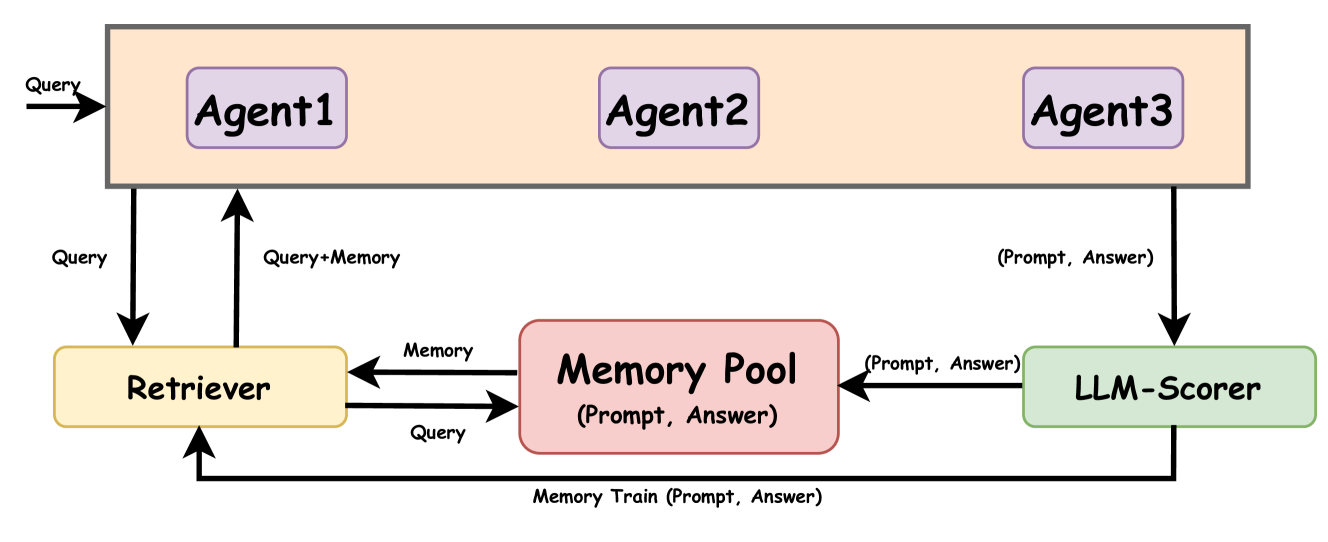
The adaptation of Large Language Model (LLM)-based agents to execute tasks via natural language prompts represents a significant advancement, notably eliminating the need for explicit retraining or fine tuning, but are constrained by the comprehensiveness and diversity of the provided examples, leading to outputs that often diverge significantly from expected results, especially when it comes to the open-ended questions. This paper introduces the Memory Sharing, a framework which integrates the real-time memory filter, storage and retrieval to enhance the In-Context Learning process. This framework allows for the sharing of memories among multiple agents, whereby the interactions and shared memories between different agents effectively enhance the diversity of the memories. The collective self-enhancement through interactive learning among multiple agents facilitates the evolution from individual intelligence to collective intelligence. Besides, the dynamically growing memory pool is utilized not only to improve the quality of responses but also to train and enhance the retriever. We evaluated our framework across three distinct domains involving specialized tasks of agents. The experimental results demonstrate that the MS framework significantly improves the agents' performance in addressing open-ended questions.
Read more7/8/2024

0
MemLong: Memory-Augmented Retrieval for Long Text Modeling
Weijie Liu, Zecheng Tang, Juntao Li, Kehai Chen, Min Zhang
Recent advancements in Large Language Models (LLMs) have yielded remarkable success across diverse fields. However, handling long contexts remains a significant challenge for LLMs due to the quadratic time and space complexity of attention mechanisms and the growing memory consumption of the key-value cache during generation. This work introduces MemLong: Memory-Augmented Retrieval for Long Text Generation, a method designed to enhance the capabilities of long-context language modeling by utilizing an external retriever for historical information retrieval. MemLong combines a non-differentiable ``ret-mem'' module with a partially trainable decoder-only language model and introduces a fine-grained, controllable retrieval attention mechanism that leverages semantic-level relevant chunks. Comprehensive evaluations on multiple long-context language modeling benchmarks demonstrate that MemLong consistently outperforms other state-of-the-art LLMs. More importantly, MemLong can extend the context length on a single 3090 GPU from 4k up to 80k. Our code is available at https://github.com/Bui1dMySea/MemLong
Read more9/2/2024