Exploring prompts to elicit memorization in masked language model-based named entity recognition

0
Sign in to get full access
Overview
- The paper explores the use of prompts to elicit memorization in masked language model-based named entity recognition (NER) systems.
- It investigates how prompts can be designed to encourage language models to rely more on memorized knowledge rather than contextual clues.
- The researchers experiment with different prompt styles and evaluate their impact on NER performance and the model's ability to recall entity information.
Plain English Explanation
Named entity recognition (NER) is a natural language processing task that identifies and classifies important words or phrases in text, such as people, organizations, or locations. Typically, language models use contextual information to perform NER, but this can lead to over-reliance on surface-level patterns and a lack of true understanding.
This paper explores ways to design prompts that encourage language models to draw more on their memorized knowledge when performing NER, rather than just using contextual clues. By experimenting with different prompt styles, the researchers aim to find techniques that help models better recall and apply their learned entity information.
The goal is to create NER systems that have a deeper, more robust understanding of entities, rather than ones that simply pattern-match based on surface features. This could lead to more accurate and reliable entity recognition, which has important applications in areas like information extraction, question answering, and knowledge base construction.
Technical Explanation
The paper evaluates different prompting strategies for masked language model-based named entity recognition. The researchers experiment with three main prompt types:
- Entity-focused prompts: These explicitly mention the target entity type and encourage the model to recall associated information.
- Cloze-style prompts: These use a masked token to elicit the entity mention, forcing the model to actively recall the relevant knowledge.
- Conversational prompts: These frame the task as a dialogue, potentially triggering more natural language use and memorization.
The authors assess the impact of these prompts on NER performance, as well as the model's ability to correctly recall entity-related facts. Experiments are conducted on benchmark NER datasets using the BERT language model.
The results show that certain prompt designs, particularly the entity-focused and cloze-style prompts, can indeed increase the model's reliance on memorized knowledge rather than just contextual clues. This leads to improvements in NER accuracy and stronger entity recall, compared to standard prompting approaches.
Critical Analysis
The paper provides a thoughtful exploration of prompting techniques to enhance the memorization capabilities of language models in the context of NER. However, some potential limitations and areas for further research are worth noting:
- The experiments are limited to a single language model (BERT) and NER datasets. Evaluating a broader range of models and tasks would help establish the generalizability of the findings.
- The paper does not deeply analyze the specific mechanisms by which the prompts influence the model's learning and inference processes. Further research into the cognitive and behavioral effects of prompts would be valuable.
- The paper focuses on improving memorization, but it is unclear how this impacts the model's broader understanding and generalization capabilities. Balancing memorization and context-based reasoning may be an important consideration for practical applications.
- The authors do not discuss potential ethical or societal implications of their techniques, such as the risks of over-reliance on memorized knowledge or biases encoded in training data.
Overall, this paper presents a promising direction for enhancing the capabilities of language models, but further research is needed to fully understand the tradeoffs and implications of prompt-based memorization techniques.
Conclusion
This paper explores the use of prompts to encourage masked language models to rely more on their memorized knowledge when performing named entity recognition tasks. By experimenting with different prompt designs, the researchers demonstrate that certain prompting strategies can indeed increase the model's ability to recall and apply entity-related information, leading to improved NER performance.
The findings suggest that prompt engineering could be a valuable tool for developing language models with more robust and reliable understanding of entities and other key concepts. This has important implications for a wide range of natural language processing applications, from information extraction to question answering and beyond.
However, the research also highlights the need for further exploration of the cognitive and ethical considerations surrounding prompt-based memorization techniques. As the field of language model development continues to advance, maintaining a balanced, thoughtful approach will be crucial to ensuring these powerful technologies are used responsibly and for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploring prompts to elicit memorization in masked language model-based named entity recognition
Yuxi Xia, Anastasiia Sedova, Pedro Henrique Luz de Araujo, Vasiliki Kougia, Lisa Nu{ss}baumer, Benjamin Roth
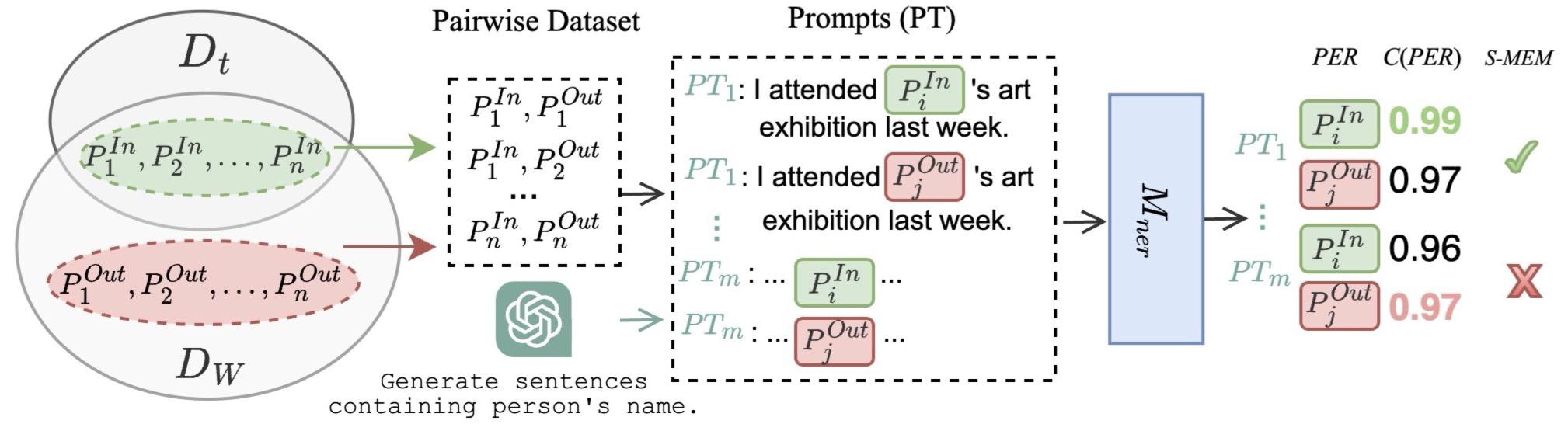
Training data memorization in language models impacts model capability (generalization) and safety (privacy risk). This paper focuses on analyzing prompts' impact on detecting the memorization of 6 masked language model-based named entity recognition models. Specifically, we employ a diverse set of 400 automatically generated prompts, and a pairwise dataset where each pair consists of one person's name from the training set and another name out of the set. A prompt completed with a person's name serves as input for getting the model's confidence in predicting this name. Finally, the prompt performance of detecting model memorization is quantified by the percentage of name pairs for which the model has higher confidence for the name from the training set. We show that the performance of different prompts varies by as much as 16 percentage points on the same model, and prompt engineering further increases the gap. Moreover, our experiments demonstrate that prompt performance is model-dependent but does generalize across different name sets. A comprehensive analysis indicates how prompt performance is influenced by prompt properties, contained tokens, and the model's self-attention weights on the prompt.
Read more5/7/2024

0
Unlocking Memorization in Large Language Models with Dynamic Soft Prompting
Zhepeng Wang, Runxue Bao, Yawen Wu, Jackson Taylor, Cao Xiao, Feng Zheng, Weiwen Jiang, Shangqian Gao, Yanfu Zhang
Pretrained large language models (LLMs) have revolutionized natural language processing (NLP) tasks such as summarization, question answering, and translation. However, LLMs pose significant security risks due to their tendency to memorize training data, leading to potential privacy breaches and copyright infringement. Accurate measurement of this memorization is essential to evaluate and mitigate these potential risks. However, previous attempts to characterize memorization are constrained by either using prefixes only or by prepending a constant soft prompt to the prefixes, which cannot react to changes in input. To address this challenge, we propose a novel method for estimating LLM memorization using dynamic, prefix-dependent soft prompts. Our approach involves training a transformer-based generator to produce soft prompts that adapt to changes in input, thereby enabling more accurate extraction of memorized data. Our method not only addresses the limitations of previous methods but also demonstrates superior performance in diverse experimental settings compared to state-of-the-art techniques. In particular, our method can achieve the maximum relative improvement of 112.75% and 32.26% over the vanilla baseline in terms of discoverable memorization rate for the text generation task and code generation task respectively.
Read more9/24/2024
💬
0
Demystifying Prompts in Language Models via Perplexity Estimation
Hila Gonen, Srini Iyer, Terra Blevins, Noah A. Smith, Luke Zettlemoyer
Language models can be prompted to perform a wide variety of zero- and few-shot learning problems. However, performance varies significantly with the choice of prompt, and we do not yet understand why this happens or how to pick the best prompts. In this work, we analyze the factors that contribute to this variance and establish a new empirical hypothesis: the performance of a prompt is coupled with the extent to which the model is familiar with the language it contains. Over a wide range of tasks, we show that the lower the perplexity of the prompt is, the better the prompt is able to perform the task. As a result, we devise a method for creating prompts: (1) automatically extend a small seed set of manually written prompts by paraphrasing using GPT3 and backtranslation and (2) choose the lowest perplexity prompts to get significant gains in performance.
Read more9/16/2024

0
DePrompt: Desensitization and Evaluation of Personal Identifiable Information in Large Language Model Prompts
Xiongtao Sun, Gan Liu, Zhipeng He, Hui Li, Xiaoguang Li
Prompt serves as a crucial link in interacting with large language models (LLMs), widely impacting the accuracy and interpretability of model outputs. However, acquiring accurate and high-quality responses necessitates precise prompts, which inevitably pose significant risks of personal identifiable information (PII) leakage. Therefore, this paper proposes DePrompt, a desensitization protection and effectiveness evaluation framework for prompt, enabling users to safely and transparently utilize LLMs. Specifically, by leveraging large model fine-tuning techniques as the underlying privacy protection method, we integrate contextual attributes to define privacy types, achieving high-precision PII entity identification. Additionally, through the analysis of key features in prompt desensitization scenarios, we devise adversarial generative desensitization methods that retain important semantic content while disrupting the link between identifiers and privacy attributes. Furthermore, we present utility evaluation metrics for prompt to better gauge and balance privacy and usability. Our framework is adaptable to prompts and can be extended to text usability-dependent scenarios. Through comparison with benchmarks and other model methods, experimental evaluations demonstrate that our desensitized prompt exhibit superior privacy protection utility and model inference results.
Read more8/20/2024