Unraveling the Dilemma of AI Errors: Exploring the Effectiveness of Human and Machine Explanations for Large Language Models
2404.07725
0
0

Abstract
The field of eXplainable artificial intelligence (XAI) has produced a plethora of methods (e.g., saliency-maps) to gain insight into artificial intelligence (AI) models, and has exploded with the rise of deep learning (DL). However, human-participant studies question the efficacy of these methods, particularly when the AI output is wrong. In this study, we collected and analyzed 156 human-generated text and saliency-based explanations collected in a question-answering task (N=40) and compared them empirically to state-of-the-art XAI explanations (integrated gradients, conservative LRP, and ChatGPT) in a human-participant study (N=136). Our findings show that participants found human saliency maps to be more helpful in explaining AI answers than machine saliency maps, but performance negatively correlated with trust in the AI model and explanations. This finding hints at the dilemma of AI errors in explanation, where helpful explanations can lead to lower task performance when they support wrong AI predictions.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the dilemma of explaining errors made by AI systems, particularly large language models (LLMs), in the context of a question-answering task.
- The researchers investigate the challenges in providing explanations that are both informative and align with human expectations.
- They conduct a human-participant study to evaluate the effectiveness of different types of explanations, including saliency maps and text-based explanations, in confirming or correcting AI errors.
Plain English Explanation
When AI systems, such as large language models, make mistakes, it's important to understand why those errors occurred and how to address them. This paper explores the difficulties in providing explanations for AI errors that are both informative and align with how humans expect the system to explain its decisions.
The researchers set up an experiment where participants were asked to evaluate the answers provided by an AI system on a question-answering task, similar to the Stanford Question Answering Dataset (SQuAD 1.1v). The participants were shown the AI's answer, along with different types of explanations, such as saliency maps that highlight the important parts of the input, and text-based explanations that describe the AI's reasoning.
The study found that the type of explanation provided can significantly impact whether the participants confirm or correct the AI's errors. Some explanations may actually reinforce the user's belief in the AI's incorrect answer, a phenomenon known as "explanation confirmation bias." This suggests that the way explanations are presented can be just as important as the explanations themselves in helping humans understand and correct AI errors.
The findings highlight the need for more research into explainable AI (XAI) and the development of explanation techniques that better align with human expectations and facilitate the correction of AI errors.
Technical Explanation
The paper investigates the challenges in providing explanations for errors made by AI systems, particularly large language models (LLMs), in the context of a question-answering task.
The researchers conducted a human-participant study to evaluate the effectiveness of different types of explanations, including saliency maps and text-based explanations, in confirming or correcting AI errors. Participants were presented with an AI's answer to a question, along with one of three types of explanations: saliency map, text-based explanation, or no explanation.
The study found that the type of explanation provided can significantly impact whether participants confirm or correct the AI's errors. Saliency maps, which highlight the important parts of the input that influenced the AI's answer, were more effective in helping participants identify and correct errors compared to text-based explanations. However, in some cases, the explanations actually reinforced the participants' belief in the AI's incorrect answer, a phenomenon known as "explanation confirmation bias."
These findings suggest that the way explanations are presented can be just as important as the explanations themselves in helping humans understand and correct AI errors. The paper highlights the need for more research into explainable AI (XAI) and the development of explanation techniques that better align with human expectations and facilitate the correction of AI errors.
Critical Analysis
The paper raises important concerns about the challenges in providing effective explanations for AI errors, particularly in the context of question-answering tasks. The researchers acknowledge that their study has limitations, such as the use of a specific dataset (SQuAD 1.1v) and the potential for participant biases.
One key limitation is the finding that saliency maps, while more effective in identifying errors, can also lead to "explanation confirmation bias" in some cases. This suggests that the design and presentation of explanations is crucial and that more research is needed to understand the factors that influence how humans interpret and respond to different types of explanations.
Additionally, the paper does not address the potential trade-offs between model performance and explanation quality, which is an important consideration in the development of explainable AI (XAI) systems.
Further research could explore the generalizability of the findings to other types of AI tasks and systems, as well as investigate the long-term impacts of different explanation strategies on user trust, understanding, and decision-making.
Conclusion
This paper highlights the complexities involved in providing effective explanations for AI errors, particularly in the context of question-answering tasks. The findings suggest that the way explanations are presented can significantly impact whether users confirm or correct AI errors, and that "explanation confirmation bias" is a real challenge that needs to be addressed.
The research underscores the importance of continued work in the field of explainable AI (XAI), with a focus on developing explanation techniques that better align with human expectations and facilitate the correction of AI errors. As AI systems become more prevalent in decision-making processes, understanding and addressing the dilemma of AI errors will be crucial for building trust and ensuring the responsible deployment of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
LLMs for XAI: Future Directions for Explaining Explanations
Alexandra Zytek, Sara Pid`o, Kalyan Veeramachaneni
0
0
In response to the demand for Explainable Artificial Intelligence (XAI), we investigate the use of Large Language Models (LLMs) to transform ML explanations into natural, human-readable narratives. Rather than directly explaining ML models using LLMs, we focus on refining explanations computed using existing XAI algorithms. We outline several research directions, including defining evaluation metrics, prompt design, comparing LLM models, exploring further training methods, and integrating external data. Initial experiments and user study suggest that LLMs offer a promising way to enhance the interpretability and usability of XAI.
5/13/2024
🤖
How explainable AI affects human performance: A systematic review of the behavioural consequences of saliency maps
Romy Muller
0
0
Saliency maps can explain how deep neural networks classify images. But are they actually useful for humans? The present systematic review of 68 user studies found that while saliency maps can enhance human performance, null effects or even costs are quite common. To investigate what modulates these effects, the empirical outcomes were organised along several factors related to the human tasks, AI performance, XAI methods, images to be classified, human participants and comparison conditions. In image-focused tasks, benefits were less common than in AI-focused tasks, but the effects depended on the specific cognitive requirements. Moreover, benefits were usually restricted to incorrect AI predictions in AI-focused tasks but to correct ones in image-focused tasks. XAI-related factors had surprisingly little impact. The evidence was limited for image- and human-related factors and the effects were highly dependent on the comparison conditions. These findings may support the design of future user studies.
4/29/2024
🔍
Distance-Restricted Explanations: Theoretical Underpinnings & Efficient Implementation
Yacine Izza, Xuanxiang Huang, Antonio Morgado, Jordi Planes, Alexey Ignatiev, Joao Marques-Silva
0
0
The uses of machine learning (ML) have snowballed in recent years. In many cases, ML models are highly complex, and their operation is beyond the understanding of human decision-makers. Nevertheless, some uses of ML models involve high-stakes and safety-critical applications. Explainable artificial intelligence (XAI) aims to help human decision-makers in understanding the operation of such complex ML models, thus eliciting trust in their operation. Unfortunately, the majority of past XAI work is based on informal approaches, that offer no guarantees of rigor. Unsurprisingly, there exists comprehensive experimental and theoretical evidence confirming that informal methods of XAI can provide human-decision makers with erroneous information. Logic-based XAI represents a rigorous approach to explainability; it is model-based and offers the strongest guarantees of rigor of computed explanations. However, a well-known drawback of logic-based XAI is the complexity of logic reasoning, especially for highly complex ML models. Recent work proposed distance-restricted explanations, i.e. explanations that are rigorous provided the distance to a given input is small enough. Distance-restricted explainability is tightly related with adversarial robustness, and it has been shown to scale for moderately complex ML models, but the number of inputs still represents a key limiting factor. This paper investigates novel algorithms for scaling up the performance of logic-based explainers when computing and enumerating ML model explanations with a large number of inputs.
5/15/2024
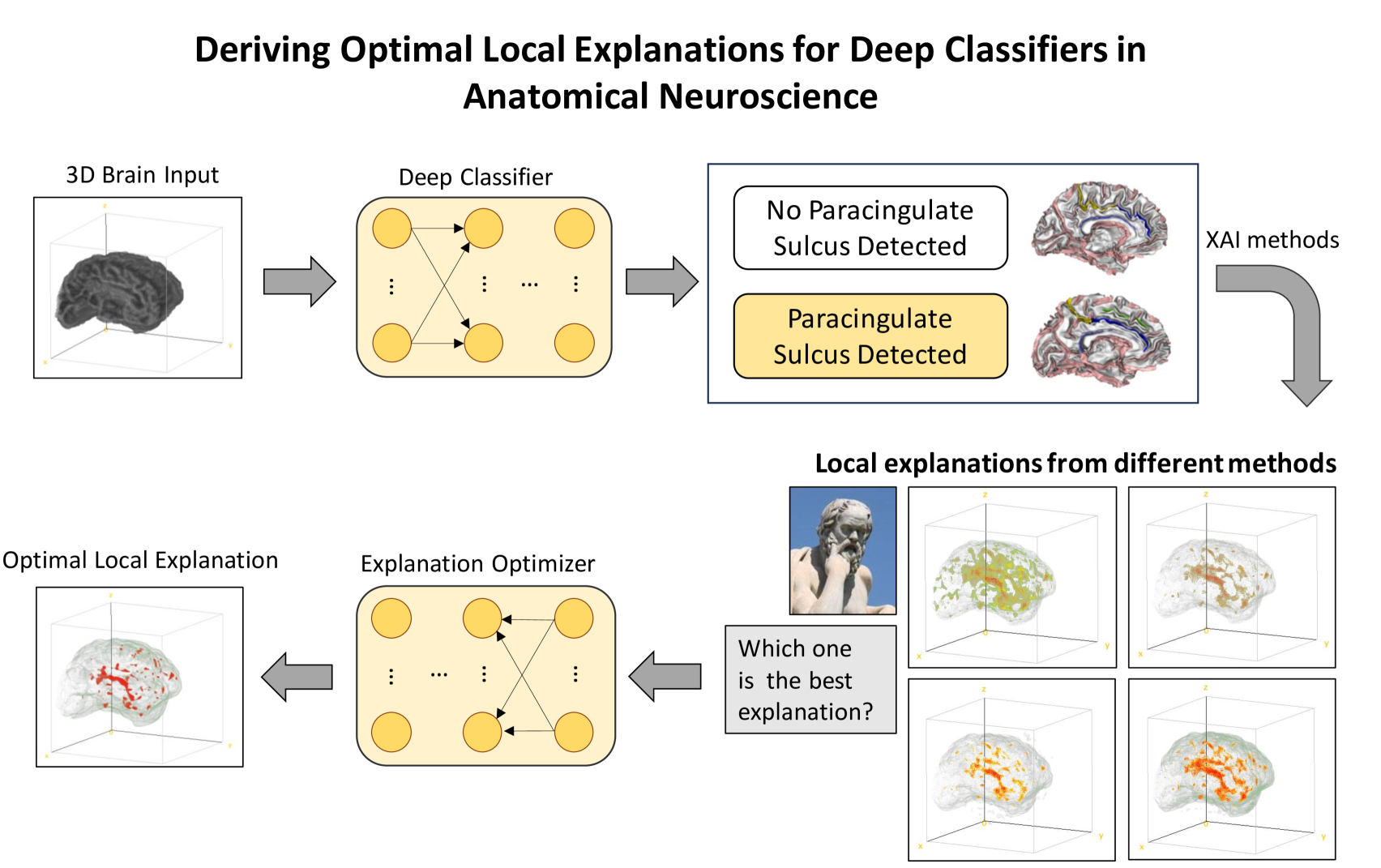
New!Solving the enigma: Deriving optimal explanations of deep networks
Michail Mamalakis, Antonios Mamalakis, Ingrid Agartz, Lynn Egeland M{o}rch-Johnsen, Graham Murray, John Suckling, Pietro Lio
0
0
The accelerated progress of artificial intelligence (AI) has popularized deep learning models across domains, yet their inherent opacity poses challenges, notably in critical fields like healthcare, medicine and the geosciences. Explainable AI (XAI) has emerged to shed light on these black box models, helping decipher their decision making process. Nevertheless, different XAI methods yield highly different explanations. This inter-method variability increases uncertainty and lowers trust in deep networks' predictions. In this study, for the first time, we propose a novel framework designed to enhance the explainability of deep networks, by maximizing both the accuracy and the comprehensibility of the explanations. Our framework integrates various explanations from established XAI methods and employs a non-linear explanation optimizer to construct a unique and optimal explanation. Through experiments on multi-class and binary classification tasks in 2D object and 3D neuroscience imaging, we validate the efficacy of our approach. Our explanation optimizer achieved superior faithfulness scores, averaging 155% and 63% higher than the best performing XAI method in the 3D and 2D applications, respectively. Additionally, our approach yielded lower complexity, increasing comprehensibility. Our results suggest that optimal explanations based on specific criteria are derivable and address the issue of inter-method variability in the current XAI literature.
5/17/2024