Unraveling overoptimism and publication bias in ML-driven science
2405.14422
0
0
🔄
Abstract
Machine Learning (ML) is increasingly used across many disciplines with impressive reported results across many domain areas. However, recent studies suggest that the published performance of ML models are often overoptimistic. Validity concerns are underscored by findings of an inverse relationship between sample size and reported accuracy in published ML models, contrasting with the theory of learning curves where accuracy should improve or remain stable with increasing sample size. This paper investigates factors contributing to overoptimistic accuracy reports in ML-driven science, focusing on data leakage and publication bias. We introduce a novel stochastic model for observed accuracy, integrating parametric learning curves and the aforementioned biases. We then construct an estimator that corrects for these biases in observed data. Theoretical and empirical results show that our framework can estimate the underlying learning curve, providing realistic performance assessments from published results. Applying the model to meta-analyses in ML-driven science, including neuroimaging-based and speech-based classifications of neurological conditions, we find prevalent overoptimism and estimate the inherent limits of ML-based prediction in each domain.
Create account to get full access
Overview
- Machine learning (ML) is being used increasingly across many fields, with impressive reported results.
- However, recent studies suggest that the published performance of ML models is often overoptimistic and not reflective of their true accuracy when deployed.
- This paper investigates the factors contributing to overoptimistic accuracy reports in ML-based science, focusing on data leakage and publication bias.
- The paper introduces a novel statistical model to estimate the underlying learning curve and provide more realistic performance assessments of ML models from published results.
Plain English Explanation
Machine learning (ML) is a powerful tool that is being used more and more in various industries and scientific fields. Researchers often report impressive results when using ML models to solve problems. However, recent studies suggest that the performance of these ML models may be overly optimistic and not reflect their true accuracy when actually deployed in the real world.
This paper investigates why the reported performance of ML models is often higher than their true accuracy. The researchers focus on two main issues: data leakage and publication bias. Data leakage occurs when information from the test data "leaks" into the training process, leading to artificially high performance. Publication bias means that studies with negative or disappointing results are less likely to be published, skewing the overall picture.
To address these problems, the researchers developed a new statistical model that can estimate the underlying "learning curve" of an ML model - how its accuracy improves as the amount of training data increases. This model can then be used to correct for the biases in the published results, providing a more realistic assessment of the model's true performance.
The researchers apply this framework to several case studies in the field of digital health, including using neuroimaging and speech-based classification of neurological conditions. Their results indicate that the reported performance in these fields is often overly optimistic, and they provide estimates of the inherent limits of ML-based prediction in these domains.
Technical Explanation
The paper introduces a novel stochastic model for observed accuracy in machine learning (ML) studies. This model integrates parametric learning curves, which describe how a model's accuracy improves with increasing training data, as well as the effects of data leakage and publication bias.
The researchers then construct an estimator based on this model that can correct for these biases in the observed data. This allows them to estimate the underlying learning curve that gives rise to the overoptimistic results typically reported in published ML studies.
Theoretical and empirical results demonstrate that this framework can provide more realistic performance assessments of ML models from a collection of published results. The researchers apply the model to various meta-analyses in the digital health literature, including neuroimaging-based and speech-based classifications of several neurological conditions.
Critical Analysis
The paper makes an important contribution by highlighting the widespread issue of overoptimistic reporting of ML model performance in the literature. The researchers' statistical framework for estimating the underlying learning curve and correcting for biases is a valuable tool for providing more realistic assessments of ML capabilities.
However, the paper does not delve into the specific mechanisms behind data leakage and publication bias in great detail. A more in-depth exploration of these issues and potential mitigation strategies could strengthen the work.
Additionally, the application of the framework to digital health case studies is informative, but the researchers acknowledge that further validation across other domains would be beneficial. Extending the analysis to a wider range of ML applications would help solidify the generalizability of their findings.
Finally, the paper does not address the ethical implications of overoptimistic ML performance reporting, such as the potential for misleading the public or influencing important decision-making. Exploring these societal concerns could enhance the paper's impact and relevance.
Conclusion
This paper makes a significant contribution to the field of machine learning by shedding light on the widespread issue of overoptimistic reporting of model performance in the published literature. The researchers' novel statistical framework provides a valuable tool for correcting for the biases of data leakage and publication bias, allowing for more realistic assessments of ML capabilities.
The application of this framework to digital health case studies highlights the potential limits of ML-based prediction in these domains, underscoring the importance of critically evaluating the true performance of ML models before deployment. As the use of machine learning continues to grow across various industries and disciplines, this work serves as an important reminder of the need for rigor and transparency in reporting ML results.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
A Structured Review of Literature on Uncertainty in Machine Learning & Deep Learning
Fahimeh Fakour, Ali Mosleh, Ramin Ramezani
0
0
The adaptation and use of Machine Learning (ML) in our daily lives has led to concerns in lack of transparency, privacy, reliability, among others. As a result, we are seeing research in niche areas such as interpretability, causality, bias and fairness, and reliability. In this survey paper, we focus on a critical concern for adaptation of ML in risk-sensitive applications, namely understanding and quantifying uncertainty. Our paper approaches this topic in a structured way, providing a review of the literature in the various facets that uncertainty is enveloped in the ML process. We begin by defining uncertainty and its categories (e.g., aleatoric and epistemic), understanding sources of uncertainty (e.g., data and model), and how uncertainty can be assessed in terms of uncertainty quantification techniques (Ensembles, Bayesian Neural Networks, etc.). As part of our assessment and understanding of uncertainty in the ML realm, we cover metrics for uncertainty quantification for a single sample, dataset, and metrics for accuracy of the uncertainty estimation itself. This is followed by discussions on calibration (model and uncertainty), and decision making under uncertainty. Thus, we provide a more complete treatment of uncertainty: from the sources of uncertainty to the decision-making process. We have focused the review of uncertainty quantification methods on Deep Learning (DL), while providing the necessary background for uncertainty discussion within ML in general. Key contributions in this review are broadening the scope of uncertainty discussion, as well as an updated review of uncertainty quantification methods in DL.
6/4/2024

A Systematic Bias of Machine Learning Regression Models and Its Correction: an Application to Imaging-based Brain Age Prediction
Hwiyoung Lee, Shuo Chen
0
0
Machine learning models for continuous outcomes often yield systematically biased predictions, particularly for values that largely deviate from the mean. Specifically, predictions for large-valued outcomes tend to be negatively biased, while those for small-valued outcomes are positively biased. We refer to this linear central tendency warped bias as the systematic bias of machine learning regression. In this paper, we first demonstrate that this issue persists across various machine learning models, and then delve into its theoretical underpinnings. We propose a general constrained optimization approach designed to correct this bias and develop a computationally efficient algorithm to implement our method. Our simulation results indicate that our correction method effectively eliminates the bias from the predicted outcomes. We apply the proposed approach to the prediction of brain age using neuroimaging data. In comparison to competing machine learning models, our method effectively addresses the longstanding issue of systematic bias of machine learning regression in neuroimaging-based brain age calculation, yielding unbiased predictions of brain age.
5/28/2024
🏷️
Beyond development: Challenges in deploying machine learning models for structural engineering applications
Mohsen Zaker Esteghamati, Brennan Bean, Henry V. Burton, M. Z. Naser
0
0
Machine learning (ML)-based solutions are rapidly changing the landscape of many fields, including structural engineering. Despite their promising performance, these approaches are usually only demonstrated as proof-of-concept in structural engineering, and are rarely deployed for real-world applications. This paper aims to illustrate the challenges of developing ML models suitable for deployment through two illustrative examples. Among various pitfalls, the presented discussion focuses on model overfitting and underspecification, training data representativeness, variable omission bias, and cross-validation. The results highlight the importance of implementing rigorous model validation techniques through adaptive sampling, careful physics-informed feature selection, and considerations of both model complexity and generalizability.
4/22/2024
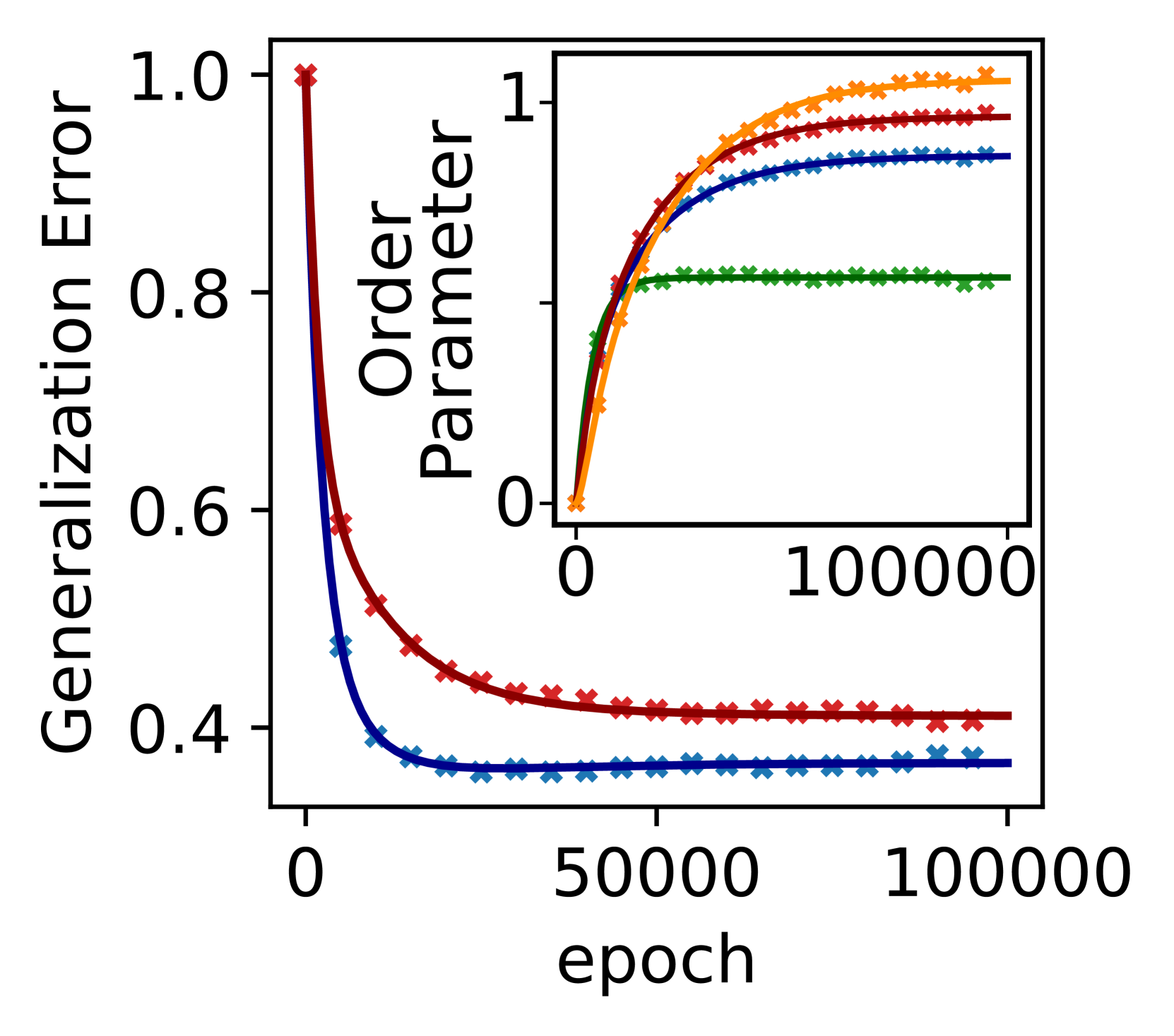
Bias in Motion: Theoretical Insights into the Dynamics of Bias in SGD Training
Anchit Jain, Rozhin Nobahari, Aristide Baratin, Stefano Sarao Mannelli
0
0
Machine learning systems often acquire biases by leveraging undesired features in the data, impacting accuracy variably across different sub-populations. Current understanding of bias formation mostly focuses on the initial and final stages of learning, leaving a gap in knowledge regarding the transient dynamics. To address this gap, this paper explores the evolution of bias in a teacher-student setup modeling different data sub-populations with a Gaussian-mixture model. We provide an analytical description of the stochastic gradient descent dynamics of a linear classifier in this setting, which we prove to be exact in high dimension. Notably, our analysis reveals how different properties of sub-populations influence bias at different timescales, showing a shifting preference of the classifier during training. Applying our findings to fairness and robustness, we delineate how and when heterogeneous data and spurious features can generate and amplify bias. We empirically validate our results in more complex scenarios by training deeper networks on synthetic and real datasets, including CIFAR10, MNIST, and CelebA.
5/29/2024