Unveiling Hidden Factors: Explainable AI for Feature Boosting in Speech Emotion Recognition
2406.01624
0
0

Abstract
Speech emotion recognition (SER) has gained significant attention due to its several application fields, such as mental health, education, and human-computer interaction. However, the accuracy of SER systems is hindered by high-dimensional feature sets that may contain irrelevant and redundant information. To overcome this challenge, this study proposes an iterative feature boosting approach for SER that emphasizes feature relevance and explainability to enhance machine learning model performance. Our approach involves meticulous feature selection and analysis to build efficient SER systems. In addressing our main problem through model explainability, we employ a feature evaluation loop with Shapley values to iteratively refine feature sets. This process strikes a balance between model performance and transparency, which enables a comprehensive understanding of the model's predictions. The proposed approach offers several advantages, including the identification and removal of irrelevant and redundant features, leading to a more effective model. Additionally, it promotes explainability, facilitating comprehension of the model's predictions and the identification of crucial features for emotion determination. The effectiveness of the proposed method is validated on the SER benchmarks of the Toronto emotional speech set (TESS), Berlin Database of Emotional Speech (EMO-DB), Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS), and Surrey Audio-Visual Expressed Emotion (SAVEE) datasets, outperforming state-of-the-art methods. To the best of our knowledge, this is the first work to incorporate model explainability into an SER framework. The source code of this paper is publicly available via this https://github.com/alaaNfissi/Unveiling-Hidden-Factors-Explainable-AI-for-Feature-Boosting-in-Speech-Emotion-Recognition.
Create account to get full access
Overview
- The paper presents an explainable AI approach for boosting the performance of speech emotion recognition models.
- It proposes an "Iterative Feature Boosting" technique that identifies and leverages important audio features to improve emotion classification accuracy.
- The approach also provides interpretable insights into which features contribute most to the model's predictions, allowing for more transparent and trustworthy speech emotion recognition systems.
Plain English Explanation
The paper focuses on the field of speech emotion recognition, which is the process of automatically detecting a person's emotional state from their voice. This is an important technology with applications in areas like customer service, mental health monitoring, and human-robot interaction.
One of the challenges in this field is that the audio features (like pitch, volume, and tone) that are most relevant for recognizing emotions can be complex and difficult to identify. The researchers tackle this problem by developing a new technique called "Iterative Feature Boosting."
This approach systematically tests different combinations of audio features to find the ones that are most predictive of emotion. It then uses these key features to train a more accurate emotion recognition model. Importantly, the technique also provides clear explanations of which features are driving the model's decisions, making the system more transparent and trustworthy.
Compared to prior work, this approach offers significant improvements in emotion classification accuracy. By unveiling the hidden factors that contribute to emotion recognition, it paves the way for more robust and explainable speech emotion technologies.
Technical Explanation
The paper proposes an "Iterative Feature Boosting" (IFB) technique to enhance the performance of speech emotion recognition models. The key steps of the IFB approach are:
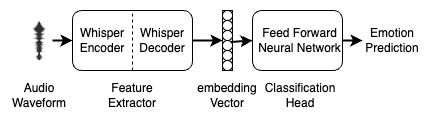
- Feature Extraction: A wide range of low-level acoustic features (e.g. pitch, energy, spectral) are extracted from the speech samples.
- Feature Selection: An iterative process is used to systematically evaluate different combinations of features and identify the most informative ones for emotion classification.
- Model Training: The selected features are used to train a speech emotion recognition model, such as a Support Vector Machine (SVM) or Neural Network.
- Explainability: The trained model provides interpretable insights into which features contribute most to its predictions, enabling a better understanding of the underlying factors driving emotion recognition.
The paper evaluates the IFB approach on multiple speech emotion datasets and compares its performance to other state-of-the-art methods. The results demonstrate significant improvements in emotion classification accuracy, as well as the ability to provide clear explanations for the model's decisions.
This work builds upon prior research in explainable AI for speech emotion recognition and other domains. The iterative feature selection process and interpretability of the trained models are key innovations that differentiate this approach from earlier techniques.
Critical Analysis
The paper presents a well-designed and rigorous study, with a clear methodology and thorough evaluation. The proposed IFB technique appears to be a promising approach for enhancing the performance and interpretability of speech emotion recognition models.
One potential limitation is that the feature selection process, while systematic, may still miss important interactions between different audio features. Future work could explore more advanced feature engineering or selection methods to further improve the model's predictive power.
Additionally, the paper only evaluates the approach on a limited set of datasets and emotion categories. Further testing on more diverse and realistic speech emotion datasets would be valuable to assess the technique's real-world applicability and robustness.
Overall, the research represents a thoughtful and innovative contribution to the field of explainable AI for speech emotion recognition. The IFB method's ability to identify and leverage key audio features, while also providing interpretable insights, is a significant advancement that warrants further investigation and refinement.
Conclusion
This paper introduces an "Iterative Feature Boosting" technique that enhances the performance and interpretability of speech emotion recognition models. By systematically identifying the most informative audio features for emotion classification, the approach achieves notable improvements in accuracy compared to prior methods.
Importantly, the technique also provides clear explanations of the factors driving the model's predictions, making the speech emotion recognition system more transparent and trustworthy. This advance in explainable AI for speech emotion recognition has important implications for real-world applications in areas like customer service, mental health, and human-robot interaction.
Overall, the research represents a significant step forward in developing more robust and interpretable speech emotion recognition technologies, paving the way for more reliable and user-friendly systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Iterative Feature Boosting for Explainable Speech Emotion Recognition
Alaa Nfissi, Wassim Bouachir, Nizar Bouguila, Brian Mishara
0
0
In speech emotion recognition (SER), using predefined features without considering their practical importance may lead to high dimensional datasets, including redundant and irrelevant information. Consequently, high-dimensional learning often results in decreasing model accuracy while increasing computational complexity. Our work underlines the importance of carefully considering and analyzing features in order to build efficient SER systems. We present a new supervised SER method based on an efficient feature engineering approach. We pay particular attention to the explainability of results to evaluate feature relevance and refine feature sets. This is performed iteratively through feature evaluation loop, using Shapley values to boost feature selection and improve overall framework performance. Our approach allows thus to balance the benefits between model performance and transparency. The proposed method outperforms human-level performance (HLP) and state-of-the-art machine learning methods in emotion recognition on the TESS dataset. The source code of this paper is publicly available at https://github.com/alaaNfissi/Iterative-Feature-Boosting-for-Explainable-Speech-Emotion-Recognition.
6/7/2024

Exploring Self-Supervised Multi-view Contrastive Learning for Speech Emotion Recognition with Limited Annotations
Bulat Khaertdinov, Pedro Jeuris, Annanda Sousa, Enrique Hortal
0
0
Recent advancements in Deep and Self-Supervised Learning (SSL) have led to substantial improvements in Speech Emotion Recognition (SER) performance, reaching unprecedented levels. However, obtaining sufficient amounts of accurately labeled data for training or fine-tuning the models remains a costly and challenging task. In this paper, we propose a multi-view SSL pre-training technique that can be applied to various representations of speech, including the ones generated by large speech models, to improve SER performance in scenarios where annotations are limited. Our experiments, based on wav2vec 2.0, spectral and paralinguistic features, demonstrate that the proposed framework boosts the SER performance, by up to 10% in Unweighted Average Recall, in settings with extremely sparse data annotations.
6/13/2024
What Does it Take to Generalize SER Model Across Datasets? A Comprehensive Benchmark
Adham Ibrahim, Shady Shehata, Ajinkya Kulkarni, Mukhtar Mohamed, Muhammad Abdul-Mageed
0
0
Speech emotion recognition (SER) is essential for enhancing human-computer interaction in speech-based applications. Despite improvements in specific emotional datasets, there is still a research gap in SER's capability to generalize across real-world situations. In this paper, we investigate approaches to generalize the SER system across different emotion datasets. In particular, we incorporate 11 emotional speech datasets and illustrate a comprehensive benchmark on the SER task. We also address the challenge of imbalanced data distribution using over-sampling methods when combining SER datasets for training. Furthermore, we explore various evaluation protocols for adeptness in the generalization of SER. Building on this, we explore the potential of Whisper for SER, emphasizing the importance of thorough evaluation. Our approach is designed to advance SER technology by integrating speaker-independent methods.
6/17/2024

INTERSPEECH 2009 Emotion Challenge Revisited: Benchmarking 15 Years of Progress in Speech Emotion Recognition
Andreas Triantafyllopoulos, Anton Batliner, Simon Rampp, Manuel Milling, Bjorn Schuller
0
0
We revisit the INTERSPEECH 2009 Emotion Challenge -- the first ever speech emotion recognition (SER) challenge -- and evaluate a series of deep learning models that are representative of the major advances in SER research in the time since then. We start by training each model using a fixed set of hyperparameters, and further fine-tune the best-performing models of that initial setup with a grid search. Results are always reported on the official test set with a separate validation set only used for early stopping. Most models score below or close to the official baseline, while they marginally outperform the original challenge winners after hyperparameter tuning. Our work illustrates that, despite recent progress, FAU-AIBO remains a very challenging benchmark. An interesting corollary is that newer methods do not consistently outperform older ones, showing that progress towards `solving' SER is not necessarily monotonic.
6/11/2024