Unveiling Induction Heads: Provable Training Dynamics and Feature Learning in Transformers

0
🏋️
Sign in to get full access
Overview
- In-context learning (ICL) is a core capability of large language models (LLMs), but its underlying mechanisms are not well understood.
- Most existing work only explains how the attention mechanism facilitates ICL under certain data models.
- This paper aims to understand how the other components of the transformer architecture contribute to ICL.
Plain English Explanation
The paper looks at how a two-attention-layer transformer model is trained to perform in-context learning (ICL) on n-gram Markov chain data, where each token depends on the previous n tokens.
The transformer model has several key components:
- Relative positional embedding: Encodes the relative positions of tokens
- Multi-head softmax attention: Allows the model to attend to different parts of the input
- Feed-forward layer with normalization: Processes the attended information
The researchers analyze how the gradient flow of the ICL loss function causes these components to work together in a specific way:
- The first attention layer acts as a "copier", copying past tokens within a window to each position.
- The feed-forward network with normalization acts as a "selector", generating a feature vector by looking at only the relevant past tokens.
- The second attention layer is a "classifier" that compares these features to the target and generates the output.
This specific arrangement of the transformer components allows the model to effectively learn the Markov chain structure and perform ICL.
Technical Explanation
The paper studies a two-attention-layer transformer model trained to perform ICL on n-gram Markov chain data. The model includes:
- Relative positional embedding: Encodes the relative positions of tokens in the input sequence.
- Multi-head softmax attention: Allows the model to attend to different parts of the input when generating each output token.
- Feed-forward layer with normalization: Processes the attended information before passing it to the next attention layer.
The key insight is that the gradient flow of the ICL loss function causes these components to work together in a specific way:
- The first attention layer acts as a "copier", copying past tokens within a given window to each position in the sequence.
- The feed-forward network with normalization acts as a "selector", generating a feature vector by only looking at the informationally relevant past tokens in the window.
- The second attention layer is a "classifier" that compares these features to the target and uses the similarity scores to generate the desired output.
This specific arrangement of the transformer components allows the model to effectively learn the Markov chain structure and perform ICL. The researchers prove this result mathematically and validate it with experiments.
Critical Analysis
The paper provides a detailed theoretical analysis of how the transformer architecture facilitates ICL on Markov chain data. This is an important step towards a better understanding of the inner workings of large language models.
One potential limitation is that the analysis is focused on a relatively simple Markov chain data model, and it's unclear how the insights would generalize to more complex natural language data. The researchers acknowledge this and suggest further investigation is needed.
Additionally, the paper does not address potential issues with the scalability of the proposed approach or its robustness to distributional shifts in the data. These are important practical considerations for deploying such models in real-world applications.
Overall, the paper makes a valuable contribution to the theoretical understanding of in-context learning in transformers, but there is still more work to be done to fully elucidate the capabilities and limitations of these models.
Conclusion
This paper provides a detailed theoretical analysis of how the different components of a transformer architecture work together to enable in-context learning on Markov chain data. The researchers identify specific roles for the attention layers and feed-forward network, showing how they combine to effectively learn the statistical structure of the input.
While the analysis is limited to a simplified data model, the insights gained here represent an important step towards a deeper understanding of the inner workings of large language models. Further research is needed to extend these findings to more complex, natural language data, and to explore the practical implications for real-world applications of in-context learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
Unveiling Induction Heads: Provable Training Dynamics and Feature Learning in Transformers
Siyu Chen, Heejune Sheen, Tianhao Wang, Zhuoran Yang
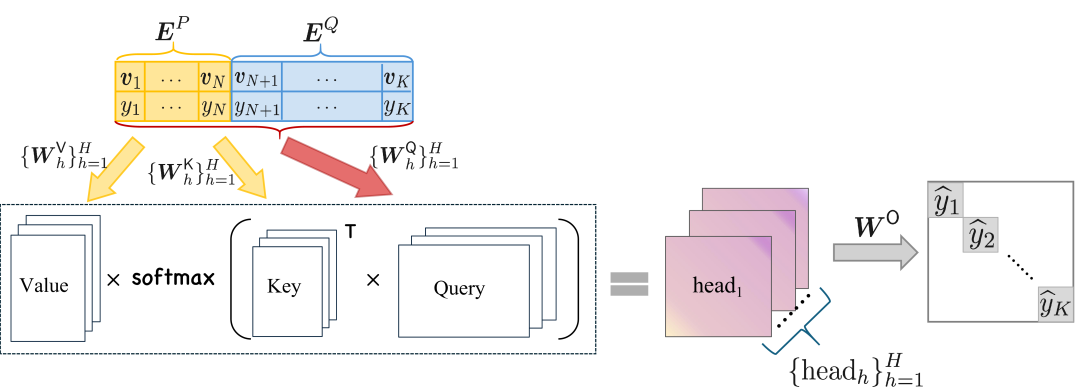
In-context learning (ICL) is a cornerstone of large language model (LLM) functionality, yet its theoretical foundations remain elusive due to the complexity of transformer architectures. In particular, most existing work only theoretically explains how the attention mechanism facilitates ICL under certain data models. It remains unclear how the other building blocks of the transformer contribute to ICL. To address this question, we study how a two-attention-layer transformer is trained to perform ICL on $n$-gram Markov chain data, where each token in the Markov chain statistically depends on the previous $n$ tokens. We analyze a sophisticated transformer model featuring relative positional embedding, multi-head softmax attention, and a feed-forward layer with normalization. We prove that the gradient flow with respect to a cross-entropy ICL loss converges to a limiting model that performs a generalized version of the induction head mechanism with a learned feature, resulting from the congruous contribution of all the building blocks. In the limiting model, the first attention layer acts as a $mathit{copier}$, copying past tokens within a given window to each position, and the feed-forward network with normalization acts as a $mathit{selector}$ that generates a feature vector by only looking at informationally relevant parents from the window. Finally, the second attention layer is a $mathit{classifier}$ that compares these features with the feature at the output position, and uses the resulting similarity scores to generate the desired output. Our theory is further validated by experiments.
Read more9/18/2024
📉
0
How Do Nonlinear Transformers Learn and Generalize in In-Context Learning?
Hongkang Li, Meng Wang, Songtao Lu, Xiaodong Cui, Pin-Yu Chen
Transformer-based large language models have displayed impressive in-context learning capabilities, where a pre-trained model can handle new tasks without fine-tuning by simply augmenting the query with some input-output examples from that task. Despite the empirical success, the mechanics of how to train a Transformer to achieve ICL and the corresponding ICL capacity is mostly elusive due to the technical challenges of analyzing the nonconvex training problems resulting from the nonlinear self-attention and nonlinear activation in Transformers. To the best of our knowledge, this paper provides the first theoretical analysis of the training dynamics of Transformers with nonlinear self-attention and nonlinear MLP, together with the ICL generalization capability of the resulting model. Focusing on a group of binary classification tasks, we train Transformers using data from a subset of these tasks and quantify the impact of various factors on the ICL generalization performance on the remaining unseen tasks with and without data distribution shifts. We also analyze how different components in the learned Transformers contribute to the ICL performance. Furthermore, we provide the first theoretical analysis of how model pruning affects ICL performance and prove that proper magnitude-based pruning can have a minimal impact on ICL while reducing inference costs. These theoretical findings are justified through numerical experiments.
Read more6/18/2024
0
In-Context Learning with Representations: Contextual Generalization of Trained Transformers
Tong Yang, Yu Huang, Yingbin Liang, Yuejie Chi
In-context learning (ICL) refers to a remarkable capability of pretrained large language models, which can learn a new task given a few examples during inference. However, theoretical understanding of ICL is largely under-explored, particularly whether transformers can be trained to generalize to unseen examples in a prompt, which will require the model to acquire contextual knowledge of the prompt for generalization. This paper investigates the training dynamics of transformers by gradient descent through the lens of non-linear regression tasks. The contextual generalization here can be attained via learning the template function for each task in-context, where all template functions lie in a linear space with $m$ basis functions. We analyze the training dynamics of one-layer multi-head transformers to in-contextly predict unlabeled inputs given partially labeled prompts, where the labels contain Gaussian noise and the number of examples in each prompt are not sufficient to determine the template. Under mild assumptions, we show that the training loss for a one-layer multi-head transformer converges linearly to a global minimum. Moreover, the transformer effectively learns to perform ridge regression over the basis functions. To our knowledge, this study is the first provable demonstration that transformers can learn contextual (i.e., template) information to generalize to both unseen examples and tasks when prompts contain only a small number of query-answer pairs.
Read more9/27/2024
🤔
0
Theoretical Understanding of In-Context Learning in Shallow Transformers with Unstructured Data
Yue Xing, Xiaofeng Lin, Chenheng Xu, Namjoon Suh, Qifan Song, Guang Cheng
Large language models (LLMs) are powerful models that can learn concepts at the inference stage via in-context learning (ICL). While theoretical studies, e.g., cite{zhang2023trained}, attempt to explain the mechanism of ICL, they assume the input $x_i$ and the output $y_i$ of each demonstration example are in the same token (i.e., structured data). However, in real practice, the examples are usually text input, and all words, regardless of their logic relationship, are stored in different tokens (i.e., unstructured data cite{wibisono2023role}). To understand how LLMs learn from the unstructured data in ICL, this paper studies the role of each component in the transformer architecture and provides a theoretical understanding to explain the success of the architecture. In particular, we consider a simple transformer with one/two attention layers and linear regression tasks for the ICL prediction. We observe that (1) a transformer with two layers of (self-)attentions with a look-ahead attention mask can learn from the prompt in the unstructured data, and (2) positional encoding can match the $x_i$ and $y_i$ tokens to achieve a better ICL performance.
Read more6/19/2024