Unveiling and Mitigating Bias in Audio Visual Segmentation

0
Sign in to get full access
Overview
- Explores bias in audio-visual segmentation models
- Unveils and mitigates biases through a novel approach
- Evaluates the model's performance across various datasets
Plain English Explanation
Audio-visual segmentation is the process of identifying and separating different elements in a video, such as objects, people, and sounds. However, these models can sometimes be biased, meaning they may perform better on certain types of data than others.
The researchers in this paper set out to unveil and mitigate bias in audio-visual segmentation models. They developed a novel approach to address this issue, which involved training the model to be more robust and fair across different types of data.
The researchers evaluated their model's performance on various datasets and found that it was able to reduce bias and improve overall accuracy. This is an important advancement in the field of audio-visual segmentation, as it can help ensure that these models work equally well for different types of people and scenarios.
Technical Explanation
The paper begins by discussing the challenges of bias in audio-visual segmentation models. The authors note that these models can often perform better on certain types of data, such as videos with a dominant speaker or clear audio-visual correspondences.
To address this issue, the researchers developed a novel approach called Multimodal Bias Mitigation (MBM). This involves training the model to be more robust and fair across different types of data by incorporating various techniques, such as adversarial training and attention-based modulation.
The researchers then evaluated their model's performance on several datasets, including those with different levels of audio-visual correspondence and speaker dominance. The results showed that their approach was able to significantly reduce bias and improve overall accuracy compared to other state-of-the-art models.
Critical Analysis
The paper acknowledges some limitations of their approach, such as the need for further research on how to effectively balance the trade-off between bias mitigation and overall performance. Additionally, the authors suggest exploring more advanced techniques for handling biases in audio-visual segmentation, such as [leveraging textual semantics or cross-modal cognitive consensus](https://aimodels.fyi/papers/arxiv/can-textual-semantics-mitigate-sounding-object-segmentation, https://aimodels.fyi/papers/arxiv/cross-modal-cognitive-consensus-guided-audio-visual).
While the paper presents a promising approach for addressing bias in audio-visual segmentation, it would be valuable to see further research on the long-term implications and potential societal impacts of this technology, particularly in terms of ensuring fairness and inclusivity.
Conclusion
This paper makes a significant contribution to the field of audio-visual segmentation by unveiling and mitigating bias in these models. The researchers' novel approach, Multimodal Bias Mitigation (MBM), demonstrates the potential to develop more robust and fair audio-visual segmentation models that can benefit a wide range of users and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unveiling and Mitigating Bias in Audio Visual Segmentation
Peiwen Sun, Honggang Zhang, Di Hu
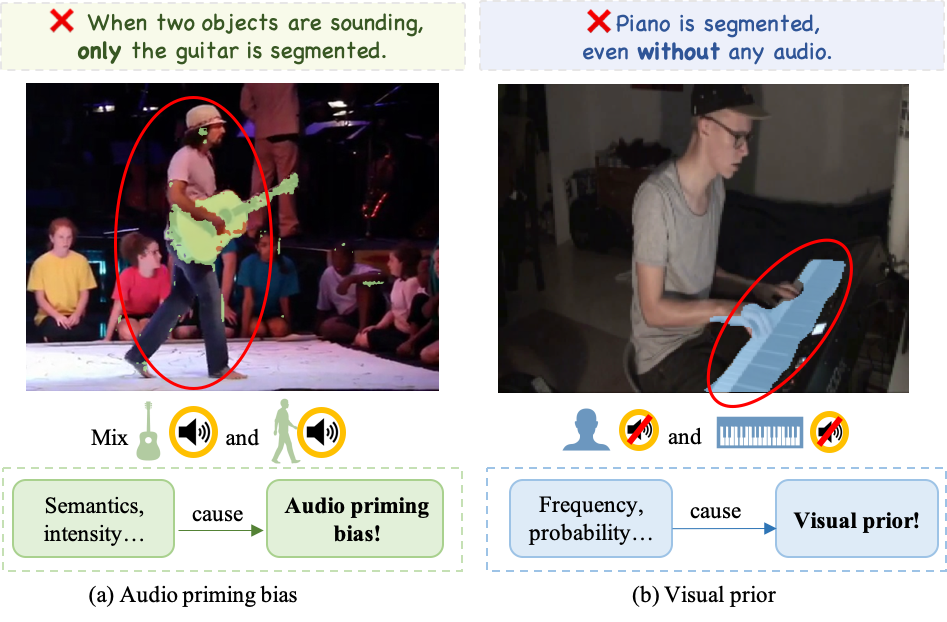
Community researchers have developed a range of advanced audio-visual segmentation models aimed at improving the quality of sounding objects' masks. While masks created by these models may initially appear plausible, they occasionally exhibit anomalies with incorrect grounding logic. We attribute this to real-world inherent preferences and distributions as a simpler signal for learning than the complex audio-visual grounding, which leads to the disregard of important modality information. Generally, the anomalous phenomena are often complex and cannot be directly observed systematically. In this study, we made a pioneering effort with the proper synthetic data to categorize and analyze phenomena as two types audio priming bias and visual prior according to the source of anomalies. For audio priming bias, to enhance audio sensitivity to different intensities and semantics, a perception module specifically for audio perceives the latent semantic information and incorporates information into a limited set of queries, namely active queries. Moreover, the interaction mechanism related to such active queries in the transformer decoder is customized to adapt to the need for interaction regulating among audio semantics. For visual prior, multiple contrastive training strategies are explored to optimize the model by incorporating a biased branch, without even changing the structure of the model. During experiments, observation demonstrates the presence and the impact that has been produced by the biases of the existing model. Finally, through experimental evaluation of AVS benchmarks, we demonstrate the effectiveness of our methods in handling both types of biases, achieving competitive performance across all three subsets.
Read more7/24/2024

0
Unveiling Visual Biases in Audio-Visual Localization Benchmarks
Liangyu Chen, Zihao Yue, Boshen Xu, Qin Jin
Audio-Visual Source Localization (AVSL) aims to localize the source of sound within a video. In this paper, we identify a significant issue in existing benchmarks: the sounding objects are often easily recognized based solely on visual cues, which we refer to as visual bias. Such biases hinder these benchmarks from effectively evaluating AVSL models. To further validate our hypothesis regarding visual biases, we examine two representative AVSL benchmarks, VGG-SS and EpicSounding-Object, where the vision-only models outperform all audiovisual baselines. Our findings suggest that existing AVSL benchmarks need further refinement to facilitate audio-visual learning.
Read more9/12/2024

0
Progressive Confident Masking Attention Network for Audio-Visual Segmentation
Yuxuan Wang, Feng Dong, Jinchao Zhu
Audio and visual signals typically occur simultaneously, and humans possess an innate ability to correlate and synchronize information from these two modalities. Recently, a challenging problem known as Audio-Visual Segmentation (AVS) has emerged, intending to produce segmentation maps for sounding objects within a scene. However, the methods proposed so far have not sufficiently integrated audio and visual information, and the computational costs have been extremely high. Additionally, the outputs of different stages have not been fully utilized. To facilitate this research, we introduce a novel Progressive Confident Masking Attention Network (PMCANet). It leverages attention mechanisms to uncover the intrinsic correlations between audio signals and visual frames. Furthermore, we design an efficient and effective cross-attention module to enhance semantic perception by selecting query tokens. This selection is determined through confidence-driven units based on the network's multi-stage predictive outputs. Experiments demonstrate that our network outperforms other AVS methods while requiring less computational resources.
Read more6/5/2024

0
Look, Listen, and Answer: Overcoming Biases for Audio-Visual Question Answering
Jie Ma, Min Hu, Pinghui Wang, Wangchun Sun, Lingyun Song, Hongbin Pei, Jun Liu, Youtian Du
Audio-Visual Question Answering (AVQA) is a complex multi-modal reasoning task, demanding intelligent systems to accurately respond to natural language queries based on audio-video input pairs. Nevertheless, prevalent AVQA approaches are prone to overlearning dataset biases, resulting in poor robustness. Furthermore, current datasets may not provide a precise diagnostic for these methods. To tackle these challenges, firstly, we propose a novel dataset, textit{MUSIC-AVQA-R}, crafted in two steps: rephrasing questions within the test split of a public dataset (textit{MUSIC-AVQA}) and subsequently introducing distribution shifts to split questions. The former leads to a large, diverse test space, while the latter results in a comprehensive robustness evaluation on rare, frequent, and overall questions. Secondly, we propose a robust architecture that utilizes a multifaceted cycle collaborative debiasing strategy to overcome bias learning. Experimental results show that this architecture achieves state-of-the-art performance on both datasets, especially obtaining a significant improvement of 9.32% on the proposed dataset. Extensive ablation experiments are conducted on these two datasets to validate the effectiveness of the debiasing strategy. Additionally, we highlight the limited robustness of existing multi-modal QA methods through the evaluation on our dataset.
Read more5/21/2024