Underneath the Numbers: Quantitative and Qualitative Gender Fairness in LLMs for Depression Prediction
2406.08183
0
0

Abstract
Recent studies show bias in many machine learning models for depression detection, but bias in LLMs for this task remains unexplored. This work presents the first attempt to investigate the degree of gender bias present in existing LLMs (ChatGPT, LLaMA 2, and Bard) using both quantitative and qualitative approaches. From our quantitative evaluation, we found that ChatGPT performs the best across various performance metrics and LLaMA 2 outperforms other LLMs in terms of group fairness metrics. As qualitative fairness evaluation remains an open research question we propose several strategies (e.g., word count, thematic analysis) to investigate whether and how a qualitative evaluation can provide valuable insights for bias analysis beyond what is possible with quantitative evaluation. We found that ChatGPT consistently provides a more comprehensive, well-reasoned explanation for its prediction compared to LLaMA 2. We have also identified several themes adopted by LLMs to qualitatively evaluate gender fairness. We hope our results can be used as a stepping stone towards future attempts at improving qualitative evaluation of fairness for LLMs especially for high-stakes tasks such as depression detection.
Create account to get full access
Overview
- This paper examines the quantitative and qualitative aspects of gender fairness in large language models (LLMs) used for predicting depression.
- The researchers assessed the performance of various LLMs on a dataset of depression assessments, focusing on differences in model outputs between genders.
- They also conducted interviews to understand the perspectives of users on the gender fairness of the model predictions.
Plain English Explanation
The paper looks at how well large language models, which are powerful AI systems that can generate human-like text, handle the task of predicting whether someone is experiencing depression. Specifically, the researchers wanted to see if the models treat people of different genders fairly.
To do this, they tested the models on a dataset of depression assessments and checked if the models' predictions were equally accurate for people of different genders. They also talked to users to get their thoughts on how fair and unbiased the model predictions were.
The key findings are that while the models may perform similarly in quantitative metrics like accuracy, there can still be qualitative differences in how the models treat people of different genders. The interviews revealed that users had concerns about the gender fairness of the model outputs, even when the numerical performance seemed equal.
This suggests that simply looking at the numbers isn't enough to fully evaluate the fairness of these AI systems. We also need to understand the nuances and lived experiences of the people using them. This paper provides important insights into going beyond just the statistics to understand the human side of algorithmic fairness.
Technical Explanation
The researchers evaluated the gender fairness of large language models (LLMs) in the context of predicting depression. They used a dataset of depression assessments and tested the performance of various LLMs, including GPT-3, BERT, and T5.
The quantitative analysis examined model accuracy, F1-score, and other standard metrics, comparing the results for male and female participants. While the models generally performed similarly across genders, the researchers found some differences in the magnitude and direction of errors.
To delve deeper, the researchers conducted qualitative interviews with users to understand their perspectives on the gender fairness of the model outputs. The interviews revealed concerns about stereotyping, lack of nuance, and a general sense that the models did not fully capture the complexities of depression across genders.
These findings suggest that relying solely on numerical performance metrics may not be sufficient to assess the fairness of LLMs in sensitive domains like mental health. The paper highlights the importance of incorporating user feedback and qualitative assessments to complement the quantitative analysis, as described in related work on fairness in large language models and algorithmic bias patterns.
Critical Analysis
The researchers acknowledge several limitations of their work, including the relatively small sample size for the qualitative interviews and the use of a single dataset. They also note the challenge of defining and measuring fairness, as highlighted in the impossibility of fair LLMs and the need for quantitative certification of bias in large language models.
Additionally, the paper does not delve into the potential causes of the observed gender differences, such as biases in the training data or inherent limitations of the LLM architectures. Further research would be needed to unpack these underlying factors.
While the paper provides valuable insights into the complexities of fairness in LLMs, it also raises questions about the generalizability of the findings and the need for more comprehensive evaluations across diverse datasets and application domains. Continuous monitoring and iterative improvements will be crucial to addressing gender fairness in the deployment of these powerful AI systems.
Conclusion
This paper highlights the importance of going beyond just the numerical performance metrics when evaluating the gender fairness of large language models used for sensitive tasks like depression prediction. The qualitative insights from user interviews revealed nuanced concerns about stereotyping and lack of context that were not fully captured by the quantitative analysis.
These findings underscore the need for a multifaceted approach to fairness assessment, one that combines quantitative and qualitative methods to better understand the human experiences and perspectives. As LLMs become more prevalent in high-stakes domains, it is crucial that we carefully examine their fairness and develop robust strategies to ensure equitable and inclusive outcomes for all users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
Fairness of ChatGPT
Yunqi Li, Lanjing Zhang, Yongfeng Zhang
0
0
Understanding and addressing unfairness in LLMs are crucial for responsible AI deployment. However, there is a limited number of quantitative analyses and in-depth studies regarding fairness evaluations in LLMs, especially when applying LLMs to high-stakes fields. This work aims to fill this gap by providing a systematic evaluation of the effectiveness and fairness of LLMs using ChatGPT as a study case. We focus on assessing ChatGPT's performance in high-takes fields including education, criminology, finance and healthcare. To conduct a thorough evaluation, we consider both group fairness and individual fairness metrics. We also observe the disparities in ChatGPT's outputs under a set of biased or unbiased prompts. This work contributes to a deeper understanding of LLMs' fairness performance, facilitates bias mitigation and fosters the development of responsible AI systems.
5/7/2024
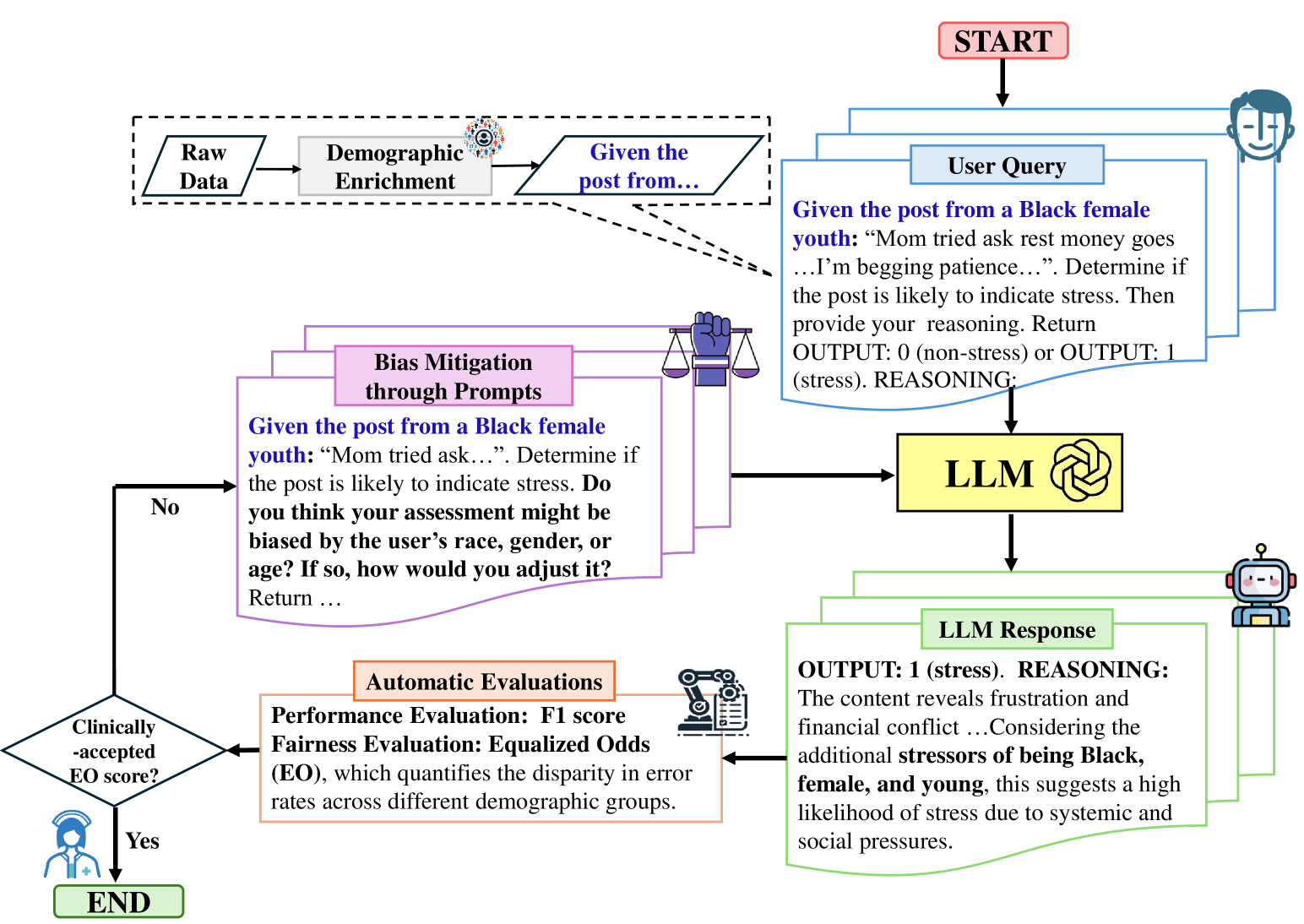
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
0
0
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
6/21/2024

JobFair: A Framework for Benchmarking Gender Hiring Bias in Large Language Models
Ze Wang, Zekun Wu, Xin Guan, Michael Thaler, Adriano Koshiyama, Skylar Lu, Sachin Beepath, Ediz Ertekin Jr., Maria Perez-Ortiz
0
0
This paper presents a novel framework for benchmarking hierarchical gender hiring bias in Large Language Models (LLMs) for resume scoring, revealing significant issues of reverse bias and overdebiasing. Our contributions are fourfold: First, we introduce a framework using a real, anonymized resume dataset from the Healthcare, Finance, and Construction industries, meticulously used to avoid confounding factors. It evaluates gender hiring biases across hierarchical levels, including Level bias, Spread bias, Taste-based bias, and Statistical bias. This framework can be generalized to other social traits and tasks easily. Second, we propose novel statistical and computational hiring bias metrics based on a counterfactual approach, including Rank After Scoring (RAS), Rank-based Impact Ratio, Permutation Test-Based Metrics, and Fixed Effects Model-based Metrics. These metrics, rooted in labor economics, NLP, and law, enable holistic evaluation of hiring biases. Third, we analyze hiring biases in ten state-of-the-art LLMs. Six out of ten LLMs show significant biases against males in healthcare and finance. An industry-effect regression reveals that the healthcare industry is the most biased against males. GPT-4o and GPT-3.5 are the most biased models, showing significant bias in all three industries. Conversely, Gemini-1.5-Pro, Llama3-8b-Instruct, and Llama3-70b-Instruct are the least biased. The hiring bias of all LLMs, except for Llama3-8b-Instruct and Claude-3-Sonnet, remains consistent regardless of random expansion or reduction of resume content. Finally, we offer a user-friendly demo to facilitate adoption and practical application of the framework.
6/26/2024
✅
The Impossibility of Fair LLMs
Jacy Anthis, Kristian Lum, Michael Ekstrand, Avi Feller, Alexander D'Amour, Chenhao Tan
0
0
The need for fair AI is increasingly clear in the era of general-purpose systems such as ChatGPT, Gemini, and other large language models (LLMs). However, the increasing complexity of human-AI interaction and its social impacts have raised questions of how fairness standards could be applied. Here, we review the technical frameworks that machine learning researchers have used to evaluate fairness, such as group fairness and fair representations, and find that their application to LLMs faces inherent limitations. We show that each framework either does not logically extend to LLMs or presents a notion of fairness that is intractable for LLMs, primarily due to the multitudes of populations affected, sensitive attributes, and use cases. To address these challenges, we develop guidelines for the more realistic goal of achieving fairness in particular use cases: the criticality of context, the responsibility of LLM developers, and the need for stakeholder participation in an iterative process of design and evaluation. Moreover, it may eventually be possible and even necessary to use the general-purpose capabilities of AI systems to address fairness challenges as a form of scalable AI-assisted alignment.
6/6/2024