Vague Preference Policy Learning for Conversational Recommendation

0
🐍
Sign in to get full access
Overview
- Conversational recommendation systems (CRS) often assume users have clear preferences, leading to potential over-filtering of relevant alternatives.
- Users frequently exhibit vague, non-binary preferences, which CRS struggle to accommodate.
- The Vague Preference Multi-round Conversational Recommendation (VPMCR) scenario introduces a soft estimation mechanism to handle users' vague and dynamic preferences while mitigating over-filtering.
- The Vague Preference Policy Learning (VPPL) approach includes Ambiguity-aware Soft Estimation (ASE) and Dynamism-aware Policy Learning (DPL) to address preference vagueness and dynamism.
Plain English Explanation
When people are looking for recommendations, such as for products or services, they often have a general idea of what they want, but their preferences may not be completely clear or fixed. Conversational recommendation systems try to provide personalized recommendations by engaging in a dialogue with the user.
However, these systems often assume that users have well-defined preferences, which can lead to them only showing the user a limited set of options that match their perceived preferences. In reality, people's preferences are often vague and can change over time. The Vague Preference Multi-round Conversational Recommendation (VPMCR) scenario addresses this by using a "soft" approach to estimate the user's preferences, allowing for more flexibility and a broader set of relevant recommendations.
The key components of this approach are:
-
Ambiguity-aware Soft Estimation (ASE): This component captures the vagueness of the user's preferences by estimating scores for both the options the user clicks on and the ones they don't. It uses a choice-based approach and takes into account how preferences change over time.
-
Dynamism-aware Policy Learning (DPL): This component uses the preference distribution information from ASE to guide the conversation and adapt the recommendations or attribute queries as the user's preferences change.
By accommodating the inherent ambiguity and dynamic nature of user preferences, this approach aims to provide more relevant and useful recommendations in real-world settings.
Technical Explanation
The Vague Preference Multi-round Conversational Recommendation (VPMCR) scenario introduces a soft estimation mechanism to handle users' vague and dynamic preferences, in contrast to the common assumption of clear user preferences in conversational recommendation systems (CRS).
The key components of the Vague Preference Policy Learning (VPPL) approach are:
-
Ambiguity-aware Soft Estimation (ASE): ASE captures preference vagueness by estimating scores for both clicked and non-clicked options using a choice-based approach. It also incorporates time-aware preference decay to account for changes in user preferences over time.
-
Dynamism-aware Policy Learning (DPL): DPL leverages the preference distribution information from ASE to guide the conversation and adapt the recommendations or attribute queries as the user's preferences change.
Extensive experiments demonstrate the effectiveness of VPPL within the VPMCR scenario, outperforming existing methods and setting a new benchmark. This work advances CRS by accommodating users' inherent ambiguity and relative decision-making processes, improving real-world applicability.
Critical Analysis
The VPMCR and VPPL approach addresses an important limitation of existing conversational recommendation systems, which often assume users have clear and static preferences. By introducing a soft estimation mechanism to handle vague and dynamic preferences, the researchers aim to provide more relevant and useful recommendations in real-world settings.
However, the paper does not fully explore the potential limitations or caveats of this approach. For example, it would be valuable to understand how the VPPL system performs when users' preferences are truly random or unpredictable, rather than just vague and dynamic. Additionally, the paper does not discuss the computational complexity or scalability of the VPPL approach, which could be an important consideration for real-world deployment.
Further research could also explore the interplay between the user's preference vagueness and other factors, such as their level of domain knowledge, decision-making style, or trust in the recommendation system. Understanding these nuances could lead to even more effective and personalized conversational recommendation experiences.
Conclusion
The Vague Preference Multi-round Conversational Recommendation (VPMCR) scenario and the Vague Preference Policy Learning (VPPL) approach represent an important advancement in conversational recommendation systems. By accommodating users' inherent preference ambiguity and dynamism, this work aims to provide more relevant and useful recommendations in real-world settings, where users' preferences are often vague and changing.
The key innovations of VPPL, including Ambiguity-aware Soft Estimation (ASE) and Dynamism-aware Policy Learning (DPL), demonstrate the potential for conversational recommendation systems to better accommodate the nuances of human decision-making. As this field continues to evolve, integrating a more nuanced understanding of user preferences can lead to significant improvements in the real-world applicability and user satisfaction of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
Vague Preference Policy Learning for Conversational Recommendation
Gangyi Zhang, Chongming Gao, Wenqiang Lei, Xiaojie Guo, Shijun Li, Hongshen Chen, Zhuozhi Ding, Sulong Xu, Lingfei Wu
Conversational recommendation systems (CRS) commonly assume users have clear preferences, leading to potential over-filtering of relevant alternatives. However, users often exhibit vague, non-binary preferences. We introduce the Vague Preference Multi-round Conversational Recommendation (VPMCR) scenario, employing a soft estimation mechanism to accommodate users' vague and dynamic preferences while mitigating over-filtering. In VPMCR, we propose Vague Preference Policy Learning (VPPL), consisting of Ambiguity-aware Soft Estimation (ASE) and Dynamism-aware Policy Learning (DPL). ASE captures preference vagueness by estimating scores for clicked and non-clicked options, using a choice-based approach and time-aware preference decay. DPL leverages ASE's preference distribution to guide the conversation and adapt to preference changes for recommendations or attribute queries. Extensive experiments demonstrate VPPL's effectiveness within VPMCR, outperforming existing methods and setting a new benchmark. Our work advances CRS by accommodating users' inherent ambiguity and relative decision-making processes, improving real-world applicability.
Read more9/4/2024
🔍
0
Chain-of-Choice Hierarchical Policy Learning for Conversational Recommendation
Wei Fan, Weijia Zhang, Weiqi Wang, Yangqiu Song, Hao Liu
Conversational Recommender Systems (CRS) illuminate user preferences via multi-round interactive dialogues, ultimately navigating towards precise and satisfactory recommendations. However, contemporary CRS are limited to inquiring binary or multi-choice questions based on a single attribute type (e.g., color) per round, which causes excessive rounds of interaction and diminishes the user's experience. To address this, we propose a more realistic and efficient conversational recommendation problem setting, called Multi-Type-Attribute Multi-round Conversational Recommendation (MTAMCR), which enables CRS to inquire about multi-choice questions covering multiple types of attributes in each round, thereby improving interactive efficiency. Moreover, by formulating MTAMCR as a hierarchical reinforcement learning task, we propose a Chain-of-Choice Hierarchical Policy Learning (CoCHPL) framework to enhance both the questioning efficiency and recommendation effectiveness in MTAMCR. Specifically, a long-term policy over options (i.e., ask or recommend) determines the action type, while two short-term intra-option policies sequentially generate the chain of attributes or items through multi-step reasoning and selection, optimizing the diversity and interdependence of questioning attributes. Finally, extensive experiments on four benchmarks demonstrate the superior performance of CoCHPL over prevailing state-of-the-art methods.
Read more4/4/2024
0
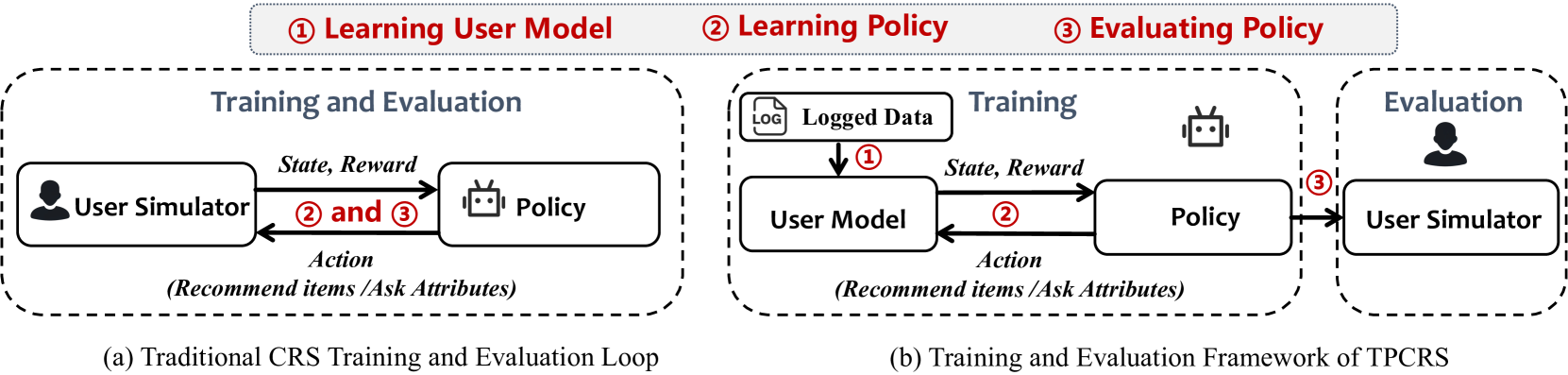
Reformulating Conversational Recommender Systems as Tri-Phase Offline Policy Learning
Gangyi Zhang, Chongming Gao, Hang Pan, Runzhe Teng, Ruizhe Li
Existing Conversational Recommender Systems (CRS) predominantly utilize user simulators for training and evaluating recommendation policies. These simulators often oversimplify the complexity of user interactions by focusing solely on static item attributes, neglecting the rich, evolving preferences that characterize real-world user behavior. This limitation frequently leads to models that perform well in simulated environments but falter in actual deployment. Addressing these challenges, this paper introduces the Tri-Phase Offline Policy Learning-based Conversational Recommender System (TCRS), which significantly reduces dependency on real-time interactions and mitigates overfitting issues prevalent in traditional approaches. TCRS integrates a model-based offline learning strategy with a controllable user simulation that dynamically aligns with both personalized and evolving user preferences. Through comprehensive experiments, TCRS demonstrates enhanced robustness, adaptability, and accuracy in recommendations, outperforming traditional CRS models in diverse user scenarios. This approach not only provides a more realistic evaluation environment but also facilitates a deeper understanding of user behavior dynamics, thereby refining the recommendation process.
Read more9/10/2024

0
Advancing Process Verification for Large Language Models via Tree-Based Preference Learning
Mingqian He, Yongliang Shen, Wenqi Zhang, Zeqi Tan, Weiming Lu
Large Language Models (LLMs) have demonstrated remarkable potential in handling complex reasoning tasks by generating step-by-step rationales.Some methods have proven effective in boosting accuracy by introducing extra verifiers to assess these paths. However, existing verifiers, typically trained on binary-labeled reasoning paths, fail to fully utilize the relative merits of intermediate steps, thereby limiting the effectiveness of the feedback provided. To overcome this limitation, we propose Tree-based Preference Learning Verifier (Tree-PLV), a novel approach that constructs reasoning trees via a best-first search algorithm and collects step-level paired data for preference training. Compared to traditional binary classification, step-level preferences more finely capture the nuances between reasoning steps, allowing for a more precise evaluation of the complete reasoning path. We empirically evaluate Tree-PLV across a range of arithmetic and commonsense reasoning tasks, where it significantly outperforms existing benchmarks. For instance, Tree-PLV achieved substantial performance gains over the Mistral-7B self-consistency baseline on GSM8K (67.55% to 82.79%), MATH (17.00% to 26.80%), CSQA (68.14% to 72.97%), and StrategyQA (82.86% to 83.25%).Additionally, our study explores the appropriate granularity for applying preference learning, revealing that step-level guidance provides feedback that better aligns with the evaluation of the reasoning process.
Read more7/2/2024