Value Approximation for Two-Player General-Sum Differential Games with State Constraints
2311.16520
0
0
📊
Abstract
Solving Hamilton-Jacobi-Isaacs (HJI) PDEs numerically enables equilibrial feedback control in two-player differential games, yet faces the curse of dimensionality (CoD). While physics-informed neural networks (PINNs) have shown promise in alleviating CoD in solving PDEs, vanilla PINNs fall short in learning discontinuous solutions due to their sampling nature, leading to poor safety performance of the resulting policies when values are discontinuous due to state or temporal logic constraints. In this study, we explore three potential solutions to this challenge: (1) a hybrid learning method that is guided by both supervisory equilibria and the HJI PDE, (2) a value-hardening method where a sequence of HJIs are solved with increasing Lipschitz constant on the constraint violation penalty, and (3) the epigraphical technique that lifts the value to a higher dimensional state space where it becomes continuous. Evaluations through 5D and 9D vehicle and 13D drone simulations reveal that the hybrid method outperforms others in terms of generalization and safety performance by taking advantage of both the supervisory equilibrium values and costates, and the low cost of PINN loss gradients.
Create account to get full access
Overview
- Solving Hamilton-Jacobi-Isaacs (HJI) partial differential equations (PDEs) numerically enables equilibrial feedback control in two-player differential games, but faces the curse of dimensionality (CoD)
- Physics-informed neural networks (PINNs) have shown promise in alleviating CoD in solving PDEs, but vanilla PINNs struggle with learning discontinuous solutions
- This study explores three potential solutions to address the challenge of learning discontinuous solutions: a hybrid learning method, a value-hardening method, and the epigraphical technique
Plain English Explanation
Differential games are a type of strategic decision-making problem where two players, often with conflicting objectives, make decisions that affect each other. Solving these games numerically using Hamilton-Jacobi-Isaacs (HJI) partial differential equations (PDEs) can enable equilibrial feedback control, but the complexity of these equations increases dramatically as the number of dimensions (e.g., state variables) grows, a phenomenon known as the curse of dimensionality.
To address this challenge, the researchers explored using physics-informed neural networks (PINNs), which have shown promise in solving PDEs efficiently. However, vanilla PINNs struggle with learning discontinuous solutions, which can occur when there are state or temporal logic constraints in the problem. This can lead to poor safety performance of the resulting policies.
The researchers propose three potential solutions to address this issue:
- A hybrid learning method that is guided by both supervisory equilibria and the HJI PDE
- A value-hardening method where a sequence of HJIs are solved with increasing Lipschitz constant on the constraint violation penalty
- The epigraphical technique that lifts the value to a higher dimensional state space where it becomes continuous
By evaluating these approaches through simulations of 5D and 9D vehicles and a 13D drone, the researchers found that the hybrid method outperforms the others in terms of generalization and safety performance, as it takes advantage of both the supervisory equilibrium values and costates, as well as the low cost of PINN loss gradients.
Technical Explanation
The researchers address the challenge of solving Hamilton-Jacobi-Isaacs (HJI) partial differential equations (PDEs) numerically, which is essential for enabling equilibrial feedback control in two-player differential games. However, this task faces the curse of dimensionality (CoD), where the complexity of the equations increases dramatically as the number of dimensions (e.g., state variables) grows.
To alleviate CoD in solving PDEs, the researchers explore the use of physics-informed neural networks (PINNs), which have shown promise in this area. However, vanilla PINNs fall short in learning discontinuous solutions, which can occur due to state or temporal logic constraints in the problem. This leads to poor safety performance of the resulting policies when values are discontinuous.
The researchers propose three potential solutions to address this challenge:
- Hybrid learning method: This approach is guided by both supervisory equilibria and the HJI PDE, leveraging the strengths of both to improve generalization and safety performance.
- Value-hardening method: In this method, a sequence of HJIs are solved with increasing Lipschitz constant on the constraint violation penalty, gradually hardening the value function to discontinuities.
- Epigraphical technique: This method lifts the value to a higher dimensional state space, where it becomes continuous, addressing the discontinuity issue.
The researchers evaluate these approaches through 5D and 9D vehicle and 13D drone simulations. The results show that the hybrid method outperforms the others in terms of generalization and safety performance, as it can take advantage of both the supervisory equilibrium values and costates, as well as the low cost of PINN loss gradients.
Critical Analysis
The researchers have presented a compelling approach to addressing the challenge of learning discontinuous solutions when solving Hamilton-Jacobi-Isaacs (HJI) PDEs using physics-informed neural networks (PINNs). The proposed hybrid learning method, value-hardening method, and epigraphical technique all offer promising avenues for improving the safety and performance of the resulting policies.
One potential limitation of the study is the reliance on simulation-based evaluations. While these provide a valuable testbed, it would be interesting to see how the methods perform on real-world differential game scenarios, where the dynamics and constraints may be more complex and unpredictable.
Additionally, the researchers mention that the hybrid method outperforms the other approaches, but it would be helpful to understand the specific trade-offs and performance characteristics of each method in more detail. This could inform the selection of the most appropriate technique for a given problem or application.
Further research could also explore the integration of these methods with other techniques for solving optimal control problems or quantifying uncertainty in HJI PDEs. By combining complementary approaches, the researchers may be able to develop even more robust and versatile solutions for this challenging class of problems.
Conclusion
This study presents a novel approach to addressing the challenge of learning discontinuous solutions when solving Hamilton-Jacobi-Isaacs (HJI) partial differential equations (PDEs) numerically using physics-informed neural networks (PINNs). The researchers explore three potential solutions: a hybrid learning method, a value-hardening method, and the epigraphical technique.
Through extensive simulations, the hybrid method emerges as the top performer, demonstrating superior generalization and safety performance by leveraging both supervisory equilibrium values and costates, as well as the efficiency of PINN loss gradients. This work represents a significant advancement in the field of differential game theory and control, with the potential to enable more robust and reliable decision-making in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
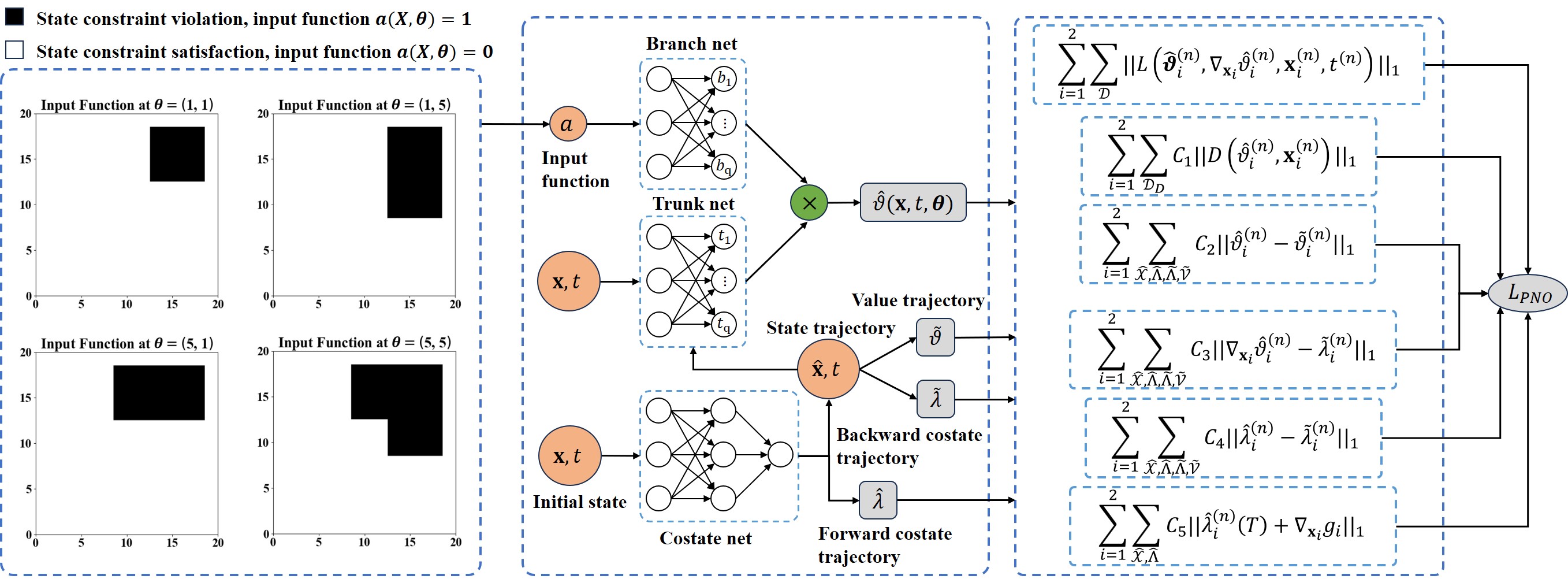
Pontryagin Neural Operator for Solving Parametric General-Sum Differential Games
Lei Zhang, Mukesh Ghimire, Zhe Xu, Wenlong Zhang, Yi Ren
0
0
The values of two-player general-sum differential games are viscosity solutions to Hamilton-Jacobi-Isaacs (HJI) equations. Value and policy approximations for such games suffer from the curse of dimensionality (CoD). Alleviating CoD through physics-informed neural networks (PINN) encounters convergence issues when differentiable values with large Lipschitz constants are present due to state constraints. On top of these challenges, it is often necessary to learn generalizable values and policies across a parametric space of games, e.g., for game parameter inference when information is incomplete. To address these challenges, we propose in this paper a Pontryagin-mode neural operator that outperforms the current state-of-the-art hybrid PINN model on safety performance across games with parametric state constraints. Our key contribution is the introduction of a costate loss defined on the discrepancy between forward and backward costate rollouts, which are computationally cheap. We show that the costate dynamics, which can reflect state constraint violation, effectively enables the learning of differentiable values with large Lipschitz constants, without requiring manually supervised data as suggested by the hybrid PINN model. More importantly, we show that the close relationship between costates and policies makes the former critical in learning feedback control policies with generalizable safety performance.
6/4/2024
🌿
Leveraging Hamilton-Jacobi PDEs with time-dependent Hamiltonians for continual scientific machine learning
Paula Chen, Tingwei Meng, Zongren Zou, J'er^ome Darbon, George Em Karniadakis
0
0
We address two major challenges in scientific machine learning (SciML): interpretability and computational efficiency. We increase the interpretability of certain learning processes by establishing a new theoretical connection between optimization problems arising from SciML and a generalized Hopf formula, which represents the viscosity solution to a Hamilton-Jacobi partial differential equation (HJ PDE) with time-dependent Hamiltonian. Namely, we show that when we solve certain regularized learning problems with integral-type losses, we actually solve an optimal control problem and its associated HJ PDE with time-dependent Hamiltonian. This connection allows us to reinterpret incremental updates to learned models as the evolution of an associated HJ PDE and optimal control problem in time, where all of the previous information is intrinsically encoded in the solution to the HJ PDE. As a result, existing HJ PDE solvers and optimal control algorithms can be reused to design new efficient training approaches for SciML that naturally coincide with the continual learning framework, while avoiding catastrophic forgetting. As a first exploration of this connection, we consider the special case of linear regression and leverage our connection to develop a new Riccati-based methodology for solving these learning problems that is amenable to continual learning applications. We also provide some corresponding numerical examples that demonstrate the potential computational and memory advantages our Riccati-based approach can provide.
5/8/2024
📊
Constrained or Unconstrained? Neural-Network-Based Equation Discovery from Data
Grant Norman, Jacqueline Wentz, Hemanth Kolla, Kurt Maute, Alireza Doostan
0
0
Throughout many fields, practitioners often rely on differential equations to model systems. Yet, for many applications, the theoretical derivation of such equations and/or accurate resolution of their solutions may be intractable. Instead, recently developed methods, including those based on parameter estimation, operator subset selection, and neural networks, allow for the data-driven discovery of both ordinary and partial differential equations (PDEs), on a spectrum of interpretability. The success of these strategies is often contingent upon the correct identification of representative equations from noisy observations of state variables and, as importantly and intertwined with that, the mathematical strategies utilized to enforce those equations. Specifically, the latter has been commonly addressed via unconstrained optimization strategies. Representing the PDE as a neural network, we propose to discover the PDE by solving a constrained optimization problem and using an intermediate state representation similar to a Physics-Informed Neural Network (PINN). The objective function of this constrained optimization problem promotes matching the data, while the constraints require that the PDE is satisfied at several spatial collocation points. We present a penalty method and a widely used trust-region barrier method to solve this constrained optimization problem, and we compare these methods on numerical examples. Our results on the Burgers' and the Korteweg-De Vreis equations demonstrate that the latter constrained method outperforms the penalty method, particularly for higher noise levels or fewer collocation points. For both methods, we solve these discovered neural network PDEs with classical methods, such as finite difference methods, as opposed to PINNs-type methods relying on automatic differentiation. We briefly highlight other small, yet crucial, implementation details.
6/6/2024
🗣️
State-Constrained Zero-Sum Differential Games with One-Sided Information
Mukesh Ghimire, Lei Zhang, Zhe Xu, Yi Ren
0
0
We study zero-sum differential games with state constraints and one-sided information, where the informed player (Player 1) has a categorical payoff type unknown to the uninformed player (Player 2). The goal of Player 1 is to minimize his payoff without violating the constraints, while that of Player 2 is to violate the state constraints if possible, or to maximize the payoff otherwise. One example of the game is a man-to-man matchup in football. Without state constraints, Cardaliaguet (2007) showed that the value of such a game exists and is convex to the common belief of players. Our theoretical contribution is an extension of this result to games with state constraints and the derivation of the primal and dual subdynamic principles necessary for computing behavioral strategies. Different from existing works that are concerned about the scalability of no-regret learning in games with discrete dynamics, our study reveals the underlying structure of strategies for belief manipulation resulting from information asymmetry and state constraints. This structure will be necessary for scalable learning on games with continuous actions and long time windows. We use a simplified football game to demonstrate the utility of this work, where we reveal player positions and belief states in which the attacker should (or should not) play specific random deceptive moves to take advantage of information asymmetry, and compute how the defender should respond.
6/5/2024