Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention

0

Sign in to get full access
Overview
- Introduces a new attention mechanism called "Lightning Attention" that can efficiently model sequences of arbitrary length
- Demonstrates that Lightning Attention outperforms existing attention mechanisms in terms of speed and memory consumption
- Applies Lightning Attention to large language model training and shows its effectiveness at reducing computational costs
Plain English Explanation
Attention mechanisms are a crucial component of many modern language models, helping them understand the relationships between different parts of a given text. However, traditional attention approaches can become computationally expensive and memory-intensive, especially when working with very long sequences of text.
The paper introduces a new type of attention called "Lightning Attention" that addresses these limitations. Lightning Attention is designed to be fast and efficient, allowing language models to process text of any length without a significant increase in resource requirements.
The key idea behind Lightning Attention is to use a constant-time algorithm to compute attention scores, rather than the typical approach that scales linearly with sequence length. This means that the time and memory needed to apply attention doesn't grow as the input text gets longer, enabling the model to handle even very long sequences efficiently.
The authors demonstrate the effectiveness of Lightning Attention by applying it to the task of training large language models. They show that using Lightning Attention can significantly reduce the computational costs and memory requirements of language model training, without sacrificing performance. This could lead to more efficient and accessible large language models that can be deployed on a wider range of hardware, including edge devices.
Technical Explanation
The paper introduces a new attention mechanism called "Lightning Attention" that can efficiently handle sequences of arbitrary length. Traditional attention mechanisms, such as those used in Transformers, have a computational and memory cost that scales linearly with the length of the input sequence. This can become a major bottleneck when working with very long sequences, as is common in language modeling tasks.
To address this issue, the authors propose Lightning Attention, which uses a constant-time algorithm to compute attention scores. Instead of attending to the entire input sequence, Lightning Attention only attends to a fixed-size "context window" around each token. This allows the attention computation to be performed in constant time, regardless of the overall sequence length.
The authors demonstrate the effectiveness of Lightning Attention through a series of experiments on language modeling tasks. They show that models using Lightning Attention can achieve comparable or better performance to those using traditional attention, while requiring significantly less computational resources and memory. This includes experiments on both standard language modeling benchmarks as well as the task of training large language models.
The paper also includes an analysis of the theoretical properties of Lightning Attention, showing that it can be applied to sequences of arbitrary length without sacrificing performance. This makes it a promising approach for building efficient and scalable language models, particularly for use cases that require processing long sequences of text.
Critical Analysis
The paper makes a convincing case for the effectiveness of Lightning Attention in improving the efficiency of language modeling, particularly for large-scale language models. The authors provide a clear explanation of the key ideas behind Lightning Attention and demonstrate its advantages through thorough experimental evaluation.
One potential limitation of the approach, as mentioned in the paper, is that it may not be as effective for tasks that require attending to very distant parts of the input sequence. The fixed-size context window used by Lightning Attention could miss important long-range dependencies in the text. The authors suggest that Lightning Attention could be combined with other attention mechanisms to address this, but further research would be needed to explore this.
Additionally, while the paper focuses on the application of Lightning Attention to language modeling, it would be interesting to see how the technique performs on other sequence-to-sequence tasks, such as machine translation or summarization. Expanding the evaluation to a broader range of applications could help further validate the generalizability of the approach.
Overall, the paper presents a promising new attention mechanism that could lead to more efficient and accessible large language models. The focus on reducing computational costs and memory requirements is particularly important, as it could enable the deployment of powerful language models on a wider range of hardware, including edge devices. Continued research and development in this area could have significant impacts on the accessibility and real-world application of large-scale language models.
Conclusion
The paper introduces a novel attention mechanism called "Lightning Attention" that addresses the computational and memory limitations of traditional attention approaches, particularly when working with long sequences of text. By using a constant-time algorithm to compute attention scores, Lightning Attention can efficiently handle sequences of arbitrary length without a significant increase in resource requirements.
The authors demonstrate the effectiveness of Lightning Attention through experiments on language modeling tasks, showing that it can match or outperform existing attention mechanisms while requiring fewer computational resources. This could lead to more efficient and accessible large language models that can be deployed on a wider range of hardware, including edge devices.
Overall, the paper presents a promising approach to improving the efficiency of language modeling and other sequence-to-sequence tasks. By addressing the scalability challenges of attention, Lightning Attention opens up new possibilities for the development and deployment of powerful natural language processing models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention
Zhen Qin, Weigao Sun, Dong Li, Xuyang Shen, Weixuan Sun, Yiran Zhong
We present Lightning Attention, the first linear attention implementation that maintains a constant training speed for various sequence lengths under fixed memory consumption. Due to the issue with cumulative summation operations (cumsum), previous linear attention implementations cannot achieve their theoretical advantage in a casual setting. However, this issue can be effectively solved by utilizing different attention calculation strategies to compute the different parts of attention. Specifically, we split the attention calculation into intra-blocks and inter-blocks and use conventional attention computation for intra-blocks and linear attention kernel tricks for inter-blocks. This eliminates the need for cumsum in the linear attention calculation. Furthermore, a tiling technique is adopted through both forward and backward procedures to take full advantage of the GPU hardware. To enhance accuracy while preserving efficacy, we introduce TransNormerLLM (TNL), a new architecture that is tailored to our lightning attention. We conduct rigorous testing on standard and self-collected datasets with varying model sizes and sequence lengths. TNL is notably more efficient than other language models. In addition, benchmark results indicate that TNL performs on par with state-of-the-art LLMs utilizing conventional transformer structures. The source code is released at github.com/OpenNLPLab/TransnormerLLM.
Read more6/21/2024
27
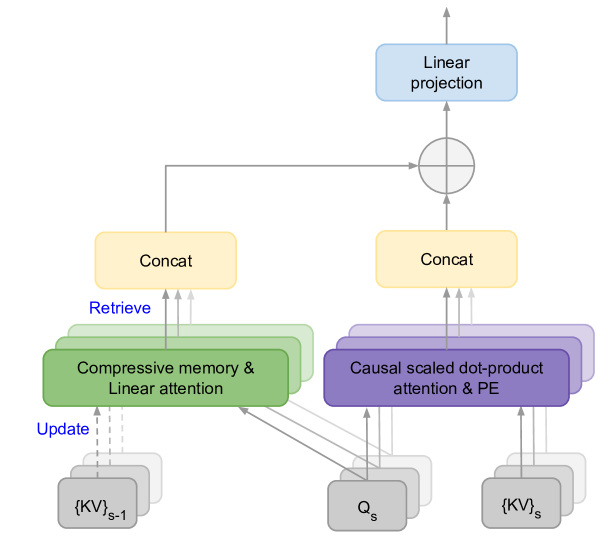
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
Read more8/13/2024
1
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
Read more6/6/2024

0
Lean Attention: Hardware-Aware Scalable Attention Mechanism for the Decode-Phase of Transformers
Rya Sanovar, Srikant Bharadwaj, Renee St. Amant, Victor Ruhle, Saravan Rajmohan
Transformer-based models have emerged as one of the most widely used architectures for natural language processing, natural language generation, and image generation. The size of the state-of-the-art models has increased steadily reaching billions of parameters. These huge models are memory hungry and incur significant inference latency even on cutting edge AI-accelerators, such as GPUs. Specifically, the time and memory complexity of the attention operation is quadratic in terms of the total context length, i.e., prompt and output tokens. Thus, several optimizations such as key-value tensor caching and FlashAttention computation have been proposed to deliver the low latency demands of applications relying on such large models. However, these techniques do not cater to the computationally distinct nature of different phases during inference. To that end, we propose LeanAttention, a scalable technique of computing self-attention for the token-generation phase (decode-phase) of decoder-only transformer models. LeanAttention enables scaling the attention mechanism implementation for the challenging case of long context lengths by re-designing the execution flow for the decode-phase. We identify that the associative property of online softmax can be treated as a reduction operation thus allowing us to parallelize the attention computation over these large context lengths. We extend the stream-K style reduction of tiled calculation to self-attention to enable parallel computation resulting in an average of 2.6x attention execution speedup over FlashAttention-2 and up to 8.33x speedup for 512k context lengths.
Read more5/20/2024