Video-LLaVA: Learning United Visual Representation by Alignment Before Projection

0
📈
Sign in to get full access
Overview
- This paper introduces a new large vision-language model (LVLM) called Video-LLaVA that can learn from a mixed dataset of images and videos.
- Existing approaches encode images and videos into separate feature spaces, which can make it challenging for a language model to learn multi-modal interactions.
- Video-LLaVA unifies visual representation into the language feature space to create a robust LVLM baseline.
- Video-LLaVA achieves superior performance on a range of image and video benchmarks, outperforming models designed specifically for images or videos.
Plain English Explanation
The researchers have developed a new large vision-language model (LVLM) called Video-LLaVA that can learn from a mix of images and videos.
Traditionally, image and video data have been encoded into separate feature spaces, which can make it challenging for a large language model (LLM) to understand the connections between them. This is like trying to put together a puzzle when the pieces are in different boxes.
To address this, the researchers have unified the visual representation into the language feature space. This creates a more unified and robust LVLM baseline that can learn from both images and videos.
The resulting Video-LLaVA model outperforms other models that are designed specifically for either images or videos, showing the benefits of this unified approach. It achieves top results on a wide range of image and video benchmarks, demonstrating its versatility and power.
Technical Explanation
The key innovation in this work is the unification of visual representation into the language feature space to create a robust LVLM baseline called Video-LLaVA.
Existing approaches typically encode images and videos into separate feature spaces, which can make it challenging for a large language model (LLM) to learn multi-modal interactions due to misalignment before projection.
To address this, the researchers unify the visual representation into the language feature space, allowing Video-LLaVA to learn from a mixed dataset of images and videos, mutually enhancing each other's representations.
Through extensive experiments, the researchers demonstrate that Video-LLaVA outperforms models designed specifically for images or videos on a broad range of benchmarks, including 9 image benchmarks across 5 image question-answering datasets and 4 image benchmark toolkits. It also outperforms Video-ChatGPT on several video understanding tasks.
The key insight is that unifying the visual representation into the language feature space allows Video-LLaVA to effectively leverage the complementary information from images and videos, leading to superior performance across a wide range of visual-language understanding tasks.
Critical Analysis
The researchers provide a thorough evaluation of Video-LLaVA, demonstrating its strong performance on a broad range of image and video benchmarks. However, the paper does not delve into the potential limitations or caveats of their approach.
For example, it would be helpful to understand the computational and memory requirements of Video-LLaVA compared to other LVLM models or specialized image/video models. This could inform the trade-offs between model complexity and performance in practical applications.
Additionally, the paper does not address potential biases or fairness issues that may arise from training on a mixed dataset of images and videos. It would be valuable to explore how Video-LLaVA handles diverse visual inputs and whether it exhibits any demographic or content biases.
Further research could also investigate the transferability of Video-LLaVA's learned representations to other downstream tasks or domains beyond the benchmarks covered in this study. This could help assess the broader applicability and generalization of the proposed approach.
Conclusion
This paper introduces a novel large vision-language model called Video-LLaVA that unifies visual representation into the language feature space, allowing it to effectively learn from a mixed dataset of images and videos.
The key contribution is the unified visual representation, which enables Video-LLaVA to outperform models designed specifically for images or videos on a wide range of benchmarks. This suggests that the unified approach can lead to more robust and versatile visual-language understanding models.
The findings in this paper provide valuable insights into the potential of large vision-language models and highlight the benefits of unifying multi-modal representations. As the field of visual-language understanding continues to evolve, this work offers a promising direction for developing more powerful and generalizable models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
New!Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, Li Yuan
The Large Vision-Language Model (LVLM) has enhanced the performance of various downstream tasks in visual-language understanding. Most existing approaches encode images and videos into separate feature spaces, which are then fed as inputs to large language models. However, due to the lack of unified tokenization for images and videos, namely misalignment before projection, it becomes challenging for a Large Language Model (LLM) to learn multi-modal interactions from several poor projection layers. In this work, we unify visual representation into the language feature space to advance the foundational LLM towards a unified LVLM. As a result, we establish a simple but robust LVLM baseline, Video-LLaVA, which learns from a mixed dataset of images and videos, mutually enhancing each other. Video-LLaVA achieves superior performances on a broad range of 9 image benchmarks across 5 image question-answering datasets and 4 image benchmark toolkits. Additionally, our Video-LLaVA also outperforms Video-ChatGPT by 5.8%, 9.9%, 18.6%, and 10.1% on MSRVTT, MSVD, TGIF, and ActivityNet, respectively. Notably, extensive experiments demonstrate that Video-LLaVA mutually benefits images and videos within a unified visual representation, outperforming models designed specifically for images or videos. We aim for this work to provide modest insights into the multi-modal inputs for the LLM. Code address: href{https://github.com/PKU-YuanGroup/Video-LLaVA}
Read more10/2/2024
📊
0
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
Yang Jin, Zhicheng Sun, Kun Xu, Kun Xu, Liwei Chen, Hao Jiang, Quzhe Huang, Chengru Song, Yuliang Liu, Di Zhang, Yang Song, Kun Gai, Yadong Mu
In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos. Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions. These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content. Our proposed framework is both capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation. Our code and models are available at https://video-lavit.github.io.
Read more6/4/2024
💬
0
u-LLaVA: Unifying Multi-Modal Tasks via Large Language Model
Jinjin Xu, Liwu Xu, Yuzhe Yang, Xiang Li, Fanyi Wang, Yanchun Xie, Yi-Jie Huang, Yaqian Li
Recent advancements in multi-modal large language models (MLLMs) have led to substantial improvements in visual understanding, primarily driven by sophisticated modality alignment strategies. However, predominant approaches prioritize global or regional comprehension, with less focus on fine-grained, pixel-level tasks. To address this gap, we introduce u-LLaVA, an innovative unifying multi-task framework that integrates pixel, regional, and global features to refine the perceptual faculties of MLLMs. We commence by leveraging an efficient modality alignment approach, harnessing both image and video datasets to bolster the model's foundational understanding across diverse visual contexts. Subsequently, a joint instruction tuning method with task-specific projectors and decoders for end-to-end downstream training is presented. Furthermore, this work contributes a novel mask-based multi-task dataset comprising 277K samples, crafted to challenge and assess the fine-grained perception capabilities of MLLMs. The overall framework is simple, effective, and achieves state-of-the-art performance across multiple benchmarks. We also make our model, data, and code publicly accessible at https://github.com/OPPOMKLab/u-LLaVA.
Read more8/29/2024
0
Fewer Tokens and Fewer Videos: Extending Video Understanding Abilities in Large Vision-Language Models
Shimin Chen, Yitian Yuan, Shaoxiang Chen, Zequn Jie, Lin Ma
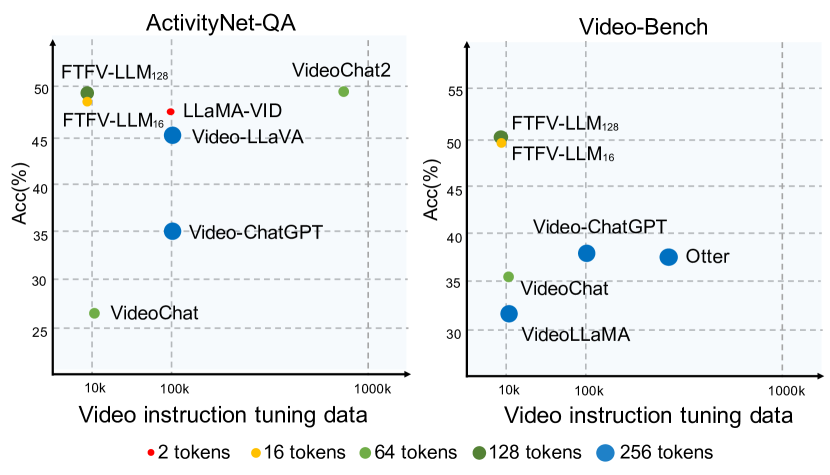
Amidst the advancements in image-based Large Vision-Language Models (image-LVLM), the transition to video-based models (video-LVLM) is hindered by the limited availability of quality video data. This paper addresses the challenge by leveraging the visual commonalities between images and videos to efficiently evolve image-LVLMs into video-LVLMs. We present a cost-effective video-LVLM that enhances model architecture, introduces innovative training strategies, and identifies the most effective types of video instruction data. Our innovative weighted token sampler significantly compresses the visual token numbers of each video frame, effectively cutting computational expenses. We also find that judiciously using just 10% of the video data, compared to prior video-LVLMs, yields impressive results during various training phases. Moreover, we delve into the influence of video instruction data in limited-resource settings, highlighting the significance of incorporating video training data that emphasizes temporal understanding to enhance model performance. The resulting Fewer Tokens and Fewer Videos LVLM (FTFV-LVLM) exhibits exceptional performance across video and image benchmarks, validating our model's design and training approaches.
Read more6/13/2024