VideoPrism: A Foundational Visual Encoder for Video Understanding
2402.13217
2
0
Abstract
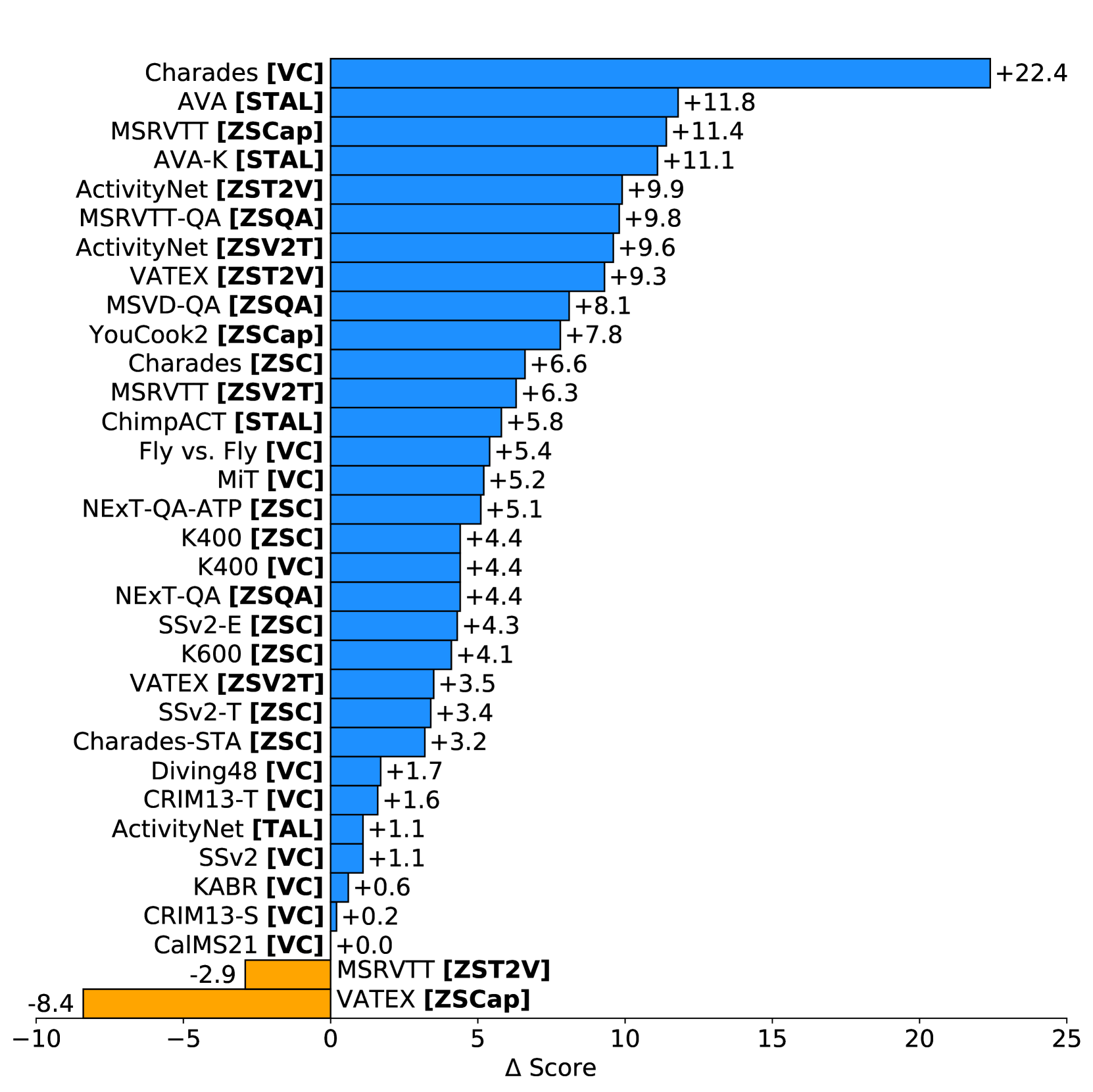
We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 31 out of 33 video understanding benchmarks.
Create account to get full access
Overview
- This paper introduces VideoPrism, a foundational visual encoder for video understanding tasks.
- VideoPrism is a self-supervised learning approach that leverages large-scale video data to build a powerful visual representation model.
- The model can be used as a general-purpose encoder for various video-related tasks, including action recognition, video retrieval, and video captioning.
Plain English Explanation
VideoPrism: A Foundational Visual Encoder for Video Understanding is a research paper that presents a new approach to building a powerful visual representation model for video data. The key idea is to use self-supervised learning, which means training the model to learn useful representations from the video data itself, without relying on manual labeling or annotations.
The researchers leveraged a large-scale collection of video data to train the VideoPrism model. The model is designed to be a "foundational" visual encoder, meaning it can be used as a general-purpose tool for a variety of video-related tasks, such as action recognition, video retrieval, and video captioning.
The benefit of this approach is that by learning rich visual representations from a large amount of video data, the VideoPrism model can be applied to many different video understanding problems, without the need to train a separate model for each task. This can save time and resources, and lead to better performance compared to task-specific models.
Technical Explanation
VideoPrism: A Foundational Visual Encoder for Video Understanding presents a self-supervised learning approach to build a powerful visual encoder for video data. The key idea is to leverage a large-scale video dataset to train the model to learn useful visual representations, without relying on manual annotations or labels.
The model architecture consists of a 3D convolutional neural network that takes a sequence of video frames as input and produces a compact feature representation. The researchers use a contrastive learning objective, where the model is trained to distinguish between positive and negative video samples. This encourages the model to learn representations that capture the underlying semantics and temporal structure of the video data.
The authors evaluate the VideoPrism model on a range of video understanding tasks, including action recognition, video retrieval, and video captioning. The results show that the self-supervised VideoPrism model outperforms previous task-specific approaches, demonstrating its effectiveness as a general-purpose visual encoder for video understanding.
Critical Analysis
The paper presents a promising approach to building a foundational visual encoder for video understanding tasks. The use of self-supervised learning to leverage large-scale video data is an effective strategy, as it allows the model to learn rich visual representations without the need for manual annotations.
However, the paper does not provide a detailed analysis of the model's limitations or potential issues. For example, it is unclear how the VideoPrism model might perform on video data with significant domain shifts or distributional differences compared to the training data. Additionally, the paper does not discuss the computational and memory requirements of the model, which could be an important consideration for real-world deployment.
Furthermore, the paper could have provided a more in-depth comparison to related work, such as video prediction models as general visual encoders or video-language models. This could have helped to better situate the contributions of the VideoPrism model within the broader context of video understanding research.
Conclusion
VideoPrism: A Foundational Visual Encoder for Video Understanding presents a novel self-supervised learning approach to build a powerful visual encoder for video data. The key innovation is the ability to leverage large-scale video datasets to learn rich visual representations that can be applied to a variety of video understanding tasks, such as action recognition, video retrieval, and video captioning.
The results demonstrate the effectiveness of the VideoPrism model as a general-purpose visual encoder, outperforming previous task-specific approaches. This work has the potential to significantly streamline the development of video understanding systems, as the foundational encoder can be easily integrated into various downstream applications.
While the paper highlights the strengths of the VideoPrism model, a more thorough critical analysis of its limitations and potential issues would have strengthened the overall contribution. Nevertheless, this research represents an important step forward in the quest to build more robust and versatile video understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Video Prediction Models as General Visual Encoders
James Maier, Nishanth Mohankumar
0
0
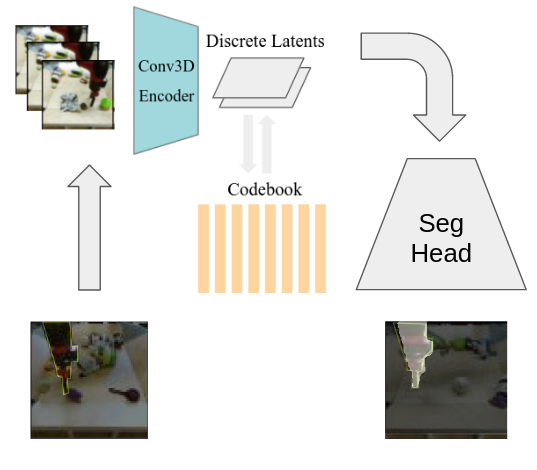
This study explores the potential of open-source video conditional generation models as encoders for downstream tasks, focusing on instance segmentation using the BAIR Robot Pushing Dataset. The researchers propose using video prediction models as general visual encoders, leveraging their ability to capture critical spatial and temporal information which is essential for tasks such as instance segmentation. Inspired by human vision studies, particularly Gestalts principle of common fate, the approach aims to develop a latent space representative of motion from images to effectively discern foreground from background information. The researchers utilize a 3D Vector-Quantized Variational Autoencoder 3D VQVAE video generative encoder model conditioned on an input frame, coupled with downstream segmentation tasks. Experiments involve adapting pre-trained video generative models, analyzing their latent spaces, and training custom decoders for foreground-background segmentation. The findings demonstrate promising results in leveraging generative pretext learning for downstream tasks, working towards enhanced scene analysis and segmentation in computer vision applications.
5/28/2024

Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krahenbuhl, Liangzhe Yuan
0
0
The recent advance in vision-language models is largely attributed to the abundance of image-text data. We aim to replicate this success for video-language models, but there simply is not enough human-curated video-text data available. We thus resort to fine-tuning a video-language model from a strong image-language baseline with synthesized instructional data. The resulting video model by video-instruction-tuning (VIIT) is then used to auto-label millions of videos to generate high-quality captions. We show the adapted video-language model performs well on a wide range of video-language benchmarks. For instance, it surpasses the best prior result on open-ended NExT-QA by 2.8%. Besides, our model generates detailed descriptions for previously unseen videos, which provide better textual supervision than existing methods. Experiments show that a video-language dual-encoder model contrastively trained on these auto-generated captions is 3.8% better than the strongest baseline that also leverages vision-language models. Our best model outperforms state-of-the-art methods on MSR-VTT zero-shot text-to-video retrieval by 6%. As a side product, we generate the largest video caption dataset to date.
4/17/2024
Prism: A Framework for Decoupling and Assessing the Capabilities of VLMs
Yuxuan Qiao, Haodong Duan, Xinyu Fang, Junming Yang, Lin Chen, Songyang Zhang, Jiaqi Wang, Dahua Lin, Kai Chen
0
0
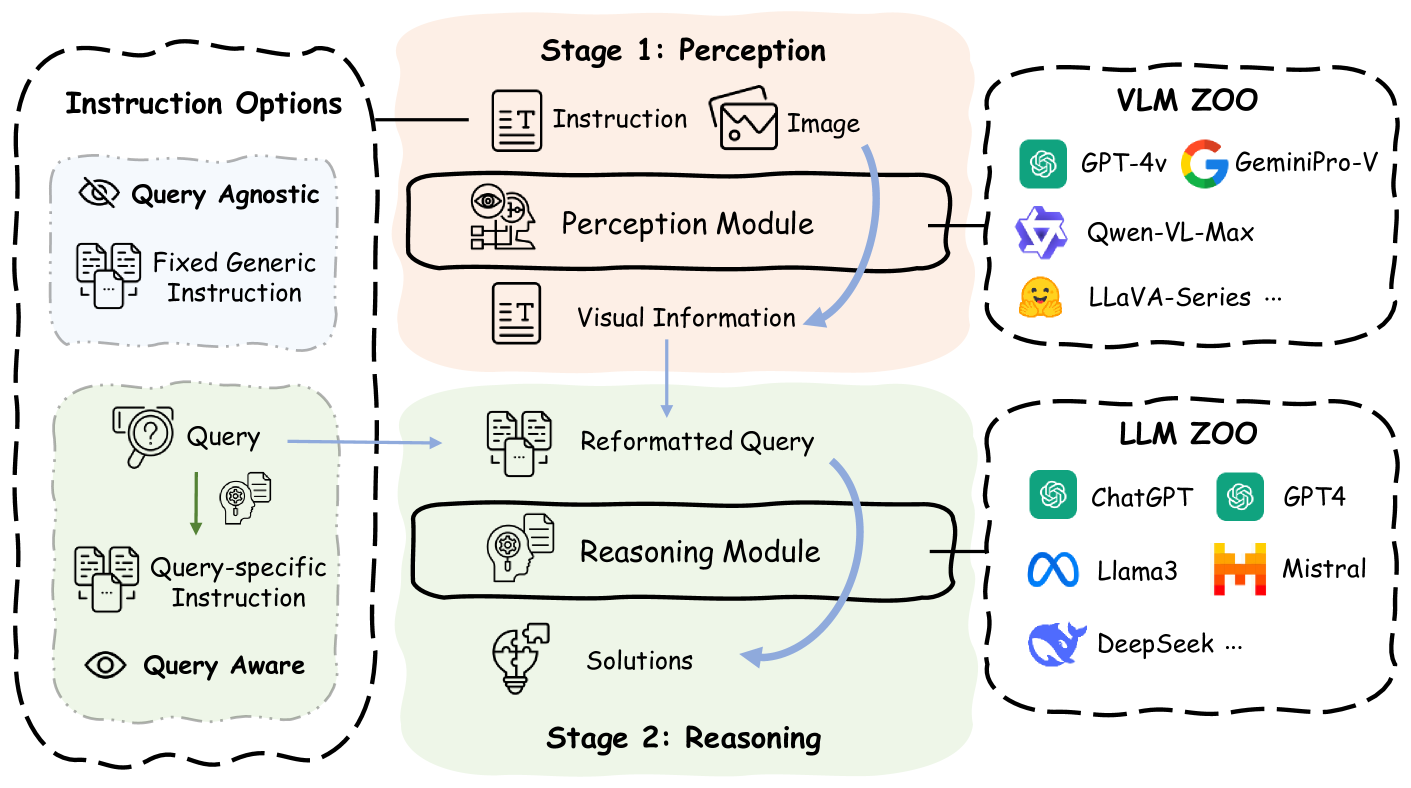
Vision Language Models (VLMs) demonstrate remarkable proficiency in addressing a wide array of visual questions, which requires strong perception and reasoning faculties. Assessing these two competencies independently is crucial for model refinement, despite the inherent difficulty due to the intertwined nature of seeing and reasoning in existing VLMs. To tackle this issue, we present Prism, an innovative framework designed to disentangle the perception and reasoning processes involved in visual question solving. Prism comprises two distinct stages: a perception stage that utilizes a VLM to extract and articulate visual information in textual form, and a reasoning stage that formulates responses based on the extracted visual information using a Large Language Model (LLM). This modular design enables the systematic comparison and assessment of both proprietary and open-source VLM for their perception and reasoning strengths. Our analytical framework provides several valuable insights, underscoring Prism's potential as a cost-effective solution for vision-language tasks. By combining a streamlined VLM focused on perception with a powerful LLM tailored for reasoning, Prism achieves superior results in general vision-language tasks while substantially cutting down on training and operational expenses. Quantitative evaluations show that Prism, when configured with a vanilla 2B LLaVA and freely accessible GPT-3.5, delivers performance on par with VLMs $10 times$ larger on the rigorous multimodal benchmark MMStar. The project is released at: https://github.com/SparksJoe/Prism.
6/21/2024
VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding
Muhammad Maaz, Hanoona Rasheed, Salman Khan, Fahad Khan
0
0
Building on the advances of language models, Large Multimodal Models (LMMs) have contributed significant improvements in video understanding. While the current video LMMs utilize advanced Large Language Models (LLMs), they rely on either image or video encoders to process visual inputs, each of which has its own limitations. Image encoders excel at capturing rich spatial details from frame sequences but lack explicit temporal context, which can be important in videos with intricate action sequences. On the other hand, video encoders provide temporal context but are often limited by computational constraints that lead to processing only sparse frames at lower resolutions, resulting in reduced contextual and spatial understanding. To this end, we introduce VideoGPT+, which combines the complementary benefits of the image encoder (for detailed spatial understanding) and the video encoder (for global temporal context modeling). The model processes videos by dividing them into smaller segments and applies an adaptive pooling strategy on features extracted by both image and video encoders. Our architecture showcases improved performance across multiple video benchmarks, including VCGBench, MVBench and Zero-shot question-answering. Further, we develop 112K video-instruction set using a novel semi-automatic annotation pipeline which further improves the model performance. Additionally, to comprehensively evaluate video LMMs, we present VCGBench-Diverse, covering 18 broad video categories such as lifestyle, sports, science, gaming, and surveillance videos. This benchmark with 4,354 question-answer pairs evaluates the generalization of existing LMMs on dense video captioning, spatial and temporal understanding, and complex reasoning, ensuring comprehensive assessment across diverse video types and dynamics. Code: https://github.com/mbzuai-oryx/VideoGPT-plus.
6/14/2024