Vision-based Discovery of Nonlinear Dynamics for 3D Moving Target
2404.17865
0
0
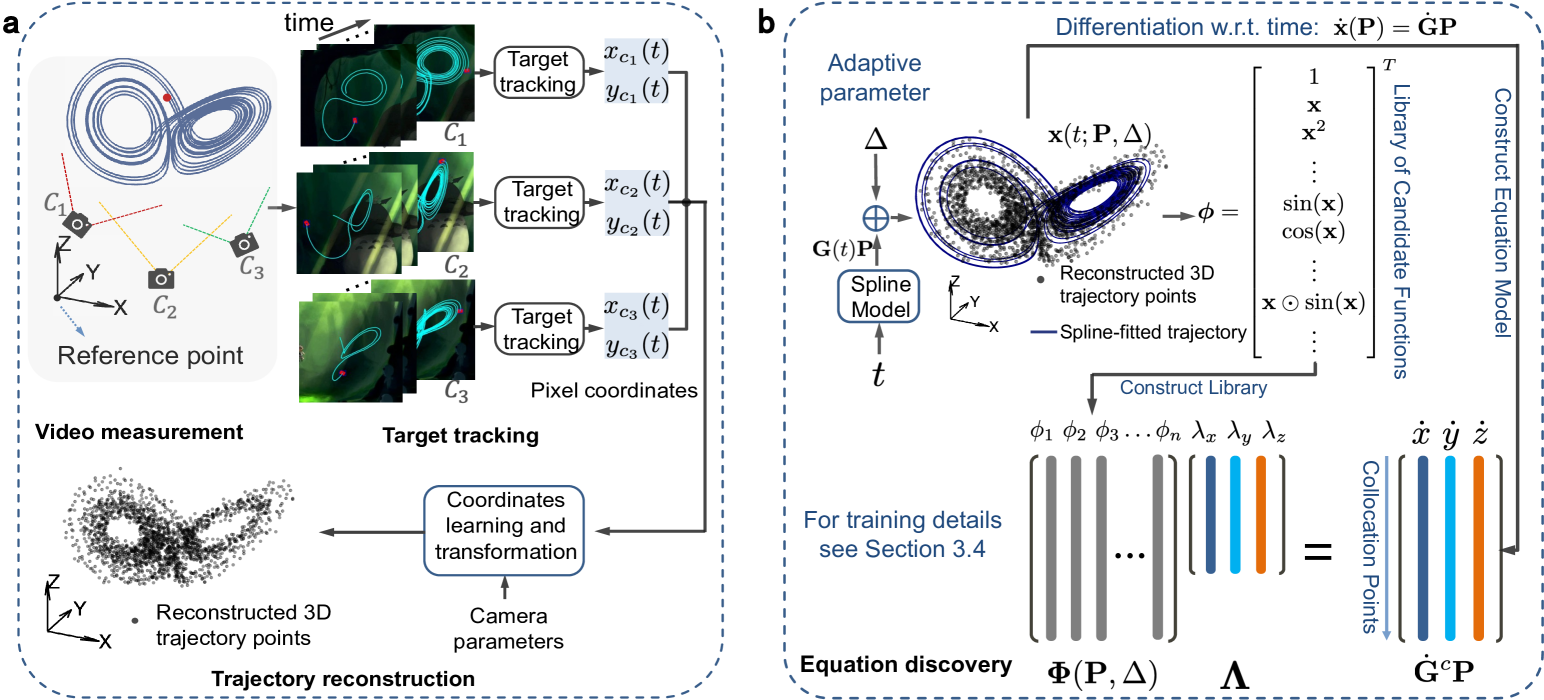
Abstract
Data-driven discovery of governing equations has kindled significant interests in many science and engineering areas. Existing studies primarily focus on uncovering equations that govern nonlinear dynamics based on direct measurement of the system states (e.g., trajectories). Limited efforts have been placed on distilling governing laws of dynamics directly from videos for moving targets in a 3D space. To this end, we propose a vision-based approach to automatically uncover governing equations of nonlinear dynamics for 3D moving targets via raw videos recorded by a set of cameras. The approach is composed of three key blocks: (1) a target tracking module that extracts plane pixel motions of the moving target in each video, (2) a Rodrigues' rotation formula-based coordinate transformation learning module that reconstructs the 3D coordinates with respect to a predefined reference point, and (3) a spline-enhanced library-based sparse regressor that uncovers the underlying governing law of dynamics. This framework is capable of effectively handling the challenges associated with measurement data, e.g., noise in the video, imprecise tracking of the target that causes data missing, etc. The efficacy of our method has been demonstrated through multiple sets of synthetic videos considering different nonlinear dynamics.
Create account to get full access
Overview
- This paper presents a vision-based approach for discovering the nonlinear dynamics of a 3D moving target.
- The method uses only visual input to learn the underlying dynamics without any prior knowledge or manual modeling.
- The authors demonstrate the approach on several simulated and real-world examples, showing its effectiveness in capturing complex nonlinear motions.
Plain English Explanation
The paper describes a new way to understand the movement of objects in 3D space using only camera footage, without any additional information. Typically, to model how an object moves, you would need to know details about the object's structure, the forces acting on it, and other technical details. However, this new approach can learn the patterns of an object's movement just by watching it, without any of that background knowledge.
The key insight is that even complex, unpredictable movements often follow underlying mathematical rules or "dynamics." By analyzing the visual data from a camera, the method can discover these hidden dynamics and use them to predict how the object will move in the future. This could be useful for applications like Pathfinder: Attention-driven Dynamic Non-Line-of-Sight, where understanding the movement of hidden objects is important.
The paper demonstrates the technique on both simulated examples and real-world scenarios, showing that it can capture a wide range of nonlinear motions, from bouncing balls to the flight of birds. By relying only on visual data, this approach provides a more flexible and practical way to model dynamic 3D objects compared to traditional methods that require detailed physical modeling.
Technical Explanation
The proposed method takes a sequence of 2D images of a 3D moving target and learns a nonlinear dynamical model to describe its motion. The key steps are:
-
Representation Learning: The algorithm first encodes each video frame into a low-dimensional latent representation using a convolutional neural network. This allows the complex visual input to be compactly represented.
-
Dynamics Learning: A recurrent neural network is then trained to predict the evolution of this latent representation over time. This captures the underlying nonlinear dynamics governing the target's motion.
-
State Inference: The trained model can then be used to infer the latent state of the target at any given time, even if the target is occluded or out of view. This allows the dynamics to be used for tasks like Learning to Predict 3D Rotational Dynamics from Videos.
The authors evaluate their approach on both simulated scenarios, like a bouncing ball, and real-world examples, such as a flying bird. They show that the method can accurately capture complex nonlinear motions that would be difficult to model using traditional physics-based approaches. The learned dynamics can also be used for downstream tasks like Learning Priors for Non-Rigid SfM from Casual Videos and Learning Governing Equations of Unobserved States in Dynamical Systems.
Critical Analysis
The paper presents a promising approach for learning the nonlinear dynamics of 3D moving targets from visual data alone. However, there are a few limitations and areas for further research:
-
Dependence on training data: The method relies on having a sufficient amount of representative training data to learn the dynamics. Its performance may degrade for targets or motions that are not well-covered in the training set.
-
Handling occlusions and partial observations: While the method can infer the latent state during occlusions, it assumes the target remains visible for some portion of the sequence. Handling long-term occlusions or partial observations remains a challenge.
-
Generalization to novel targets: The paper demonstrates the approach on a limited set of examples. Further research is needed to assess how well the learned dynamics can generalize to completely new objects or settings, especially in the real world.
-
Interpretability of learned dynamics: The paper does not provide much insight into the specific dynamical models learned by the approach. Improving the interpretability of the discovered dynamics could make the method more useful for scientific applications.
Despite these limitations, this work represents an important step towards more flexible and data-driven approaches for modeling the 3D motion of dynamic targets. Further research building on these ideas could lead to significant advancements in areas like Trailblazer: Trajectory Control for Diffusion-based Video Generation.
Conclusion
This paper presents a novel vision-based method for discovering the nonlinear dynamics of 3D moving targets. By learning a compact latent representation and the underlying dynamical model directly from video data, the approach can capture complex motions without requiring detailed physical modeling. The authors demonstrate its effectiveness on both simulated and real-world examples, showcasing its potential for a variety of applications that involve understanding and predicting the behavior of dynamic 3D objects. While the method has some limitations, this work represents an important advance in the field of video-based 3D motion modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Sync4D: Video Guided Controllable Dynamics for Physics-Based 4D Generation
Zhoujie Fu, Jiacheng Wei, Wenhao Shen, Chaoyue Song, Xiaofeng Yang, Fayao Liu, Xulei Yang, Guosheng Lin
0
0
In this work, we introduce a novel approach for creating controllable dynamics in 3D-generated Gaussians using casually captured reference videos. Our method transfers the motion of objects from reference videos to a variety of generated 3D Gaussians across different categories, ensuring precise and customizable motion transfer. We achieve this by employing blend skinning-based non-parametric shape reconstruction to extract the shape and motion of reference objects. This process involves segmenting the reference objects into motion-related parts based on skinning weights and establishing shape correspondences with generated target shapes. To address shape and temporal inconsistencies prevalent in existing methods, we integrate physical simulation, driving the target shapes with matched motion. This integration is optimized through a displacement loss to ensure reliable and genuine dynamics. Our approach supports diverse reference inputs, including humans, quadrupeds, and articulated objects, and can generate dynamics of arbitrary length, providing enhanced fidelity and applicability. Unlike methods heavily reliant on diffusion video generation models, our technique offers specific and high-quality motion transfer, maintaining both shape integrity and temporal consistency.
6/7/2024
🧪
Decoupling Dynamic Monocular Videos for Dynamic View Synthesis
Meng You, Junhui Hou
0
0
The challenge of dynamic view synthesis from dynamic monocular videos, i.e., synthesizing novel views for free viewpoints given a monocular video of a dynamic scene captured by a moving camera, mainly lies in accurately modeling the textbf{dynamic objects} of a scene using limited 2D frames, each with a varying timestamp and viewpoint. Existing methods usually require pre-processed 2D optical flow and depth maps by off-the-shelf methods to supervise the network, making them suffer from the inaccuracy of the pre-processed supervision and the ambiguity when lifting the 2D information to 3D. In this paper, we tackle this challenge in an unsupervised fashion. Specifically, we decouple the motion of the dynamic objects into object motion and camera motion, respectively regularized by proposed unsupervised surface consistency and patch-based multi-view constraints. The former enforces the 3D geometric surfaces of moving objects to be consistent over time, while the latter regularizes their appearances to be consistent across different viewpoints. Such a fine-grained motion formulation can alleviate the learning difficulty for the network, thus enabling it to produce not only novel views with higher quality but also more accurate scene flows and depth than existing methods requiring extra supervision.
6/3/2024
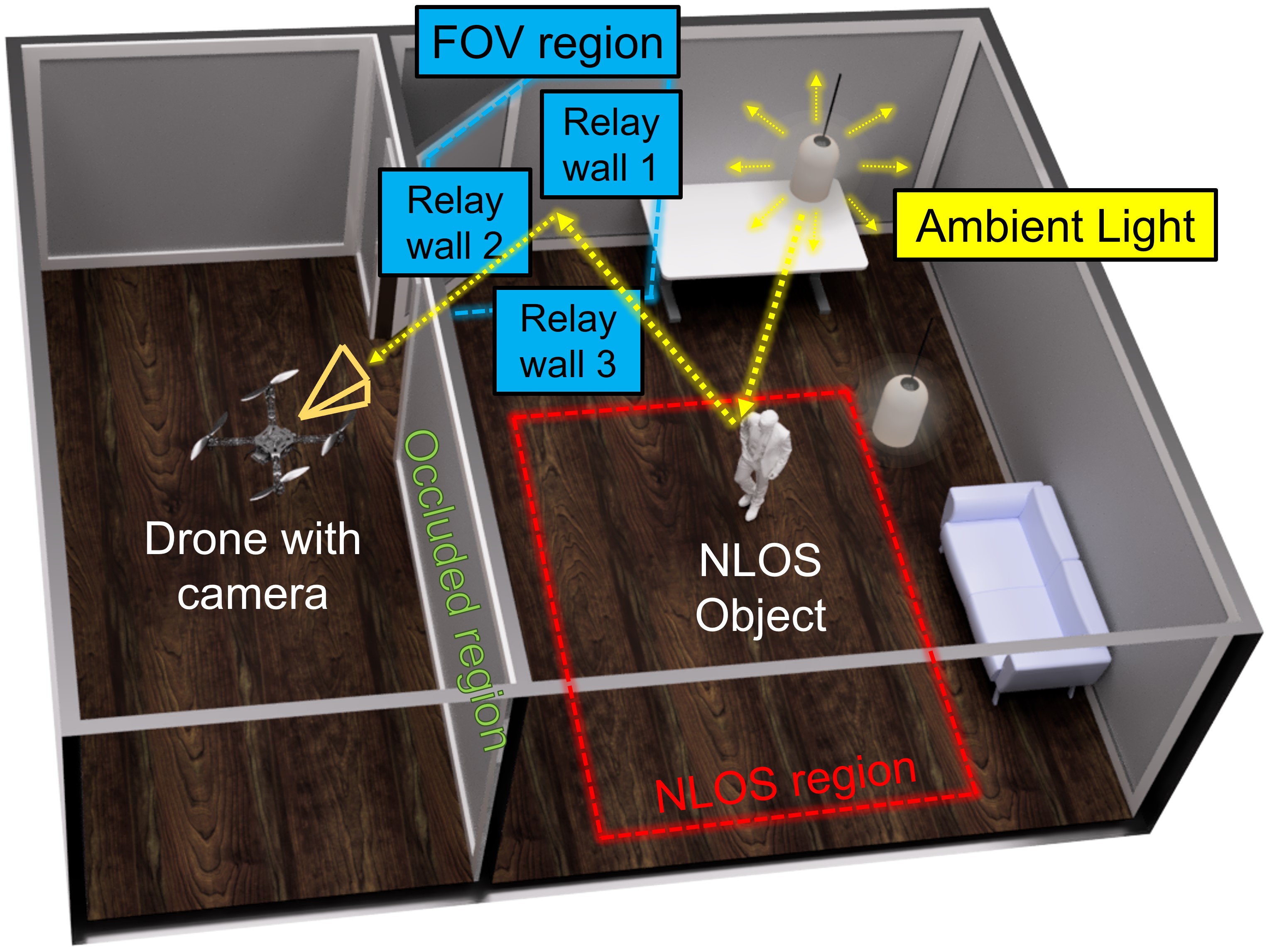
PathFinder: Attention-Driven Dynamic Non-Line-of-Sight Tracking with a Mobile Robot
Shenbagaraj Kannapiran, Sreenithy Chandran, Suren Jayasuriya, Spring Berman
0
0
The study of non-line-of-sight (NLOS) imaging is growing due to its many potential applications, including rescue operations and pedestrian detection by self-driving cars. However, implementing NLOS imaging on a moving camera remains an open area of research. Existing NLOS imaging methods rely on time-resolved detectors and laser configurations that require precise optical alignment, making it difficult to deploy them in dynamic environments. This work proposes a data-driven approach to NLOS imaging, PathFinder, that can be used with a standard RGB camera mounted on a small, power-constrained mobile robot, such as an aerial drone. Our experimental pipeline is designed to accurately estimate the 2D trajectory of a person who moves in a Manhattan-world environment while remaining hidden from the camera's field-of-view. We introduce a novel approach to process a sequence of dynamic successive frames in a line-of-sight (LOS) video using an attention-based neural network that performs inference in real-time. The method also includes a preprocessing selection metric that analyzes images from a moving camera which contain multiple vertical planar surfaces, such as walls and building facades, and extracts planes that return maximum NLOS information. We validate the approach on in-the-wild scenes using a drone for video capture, thus demonstrating low-cost NLOS imaging in dynamic capture environments.
4/9/2024
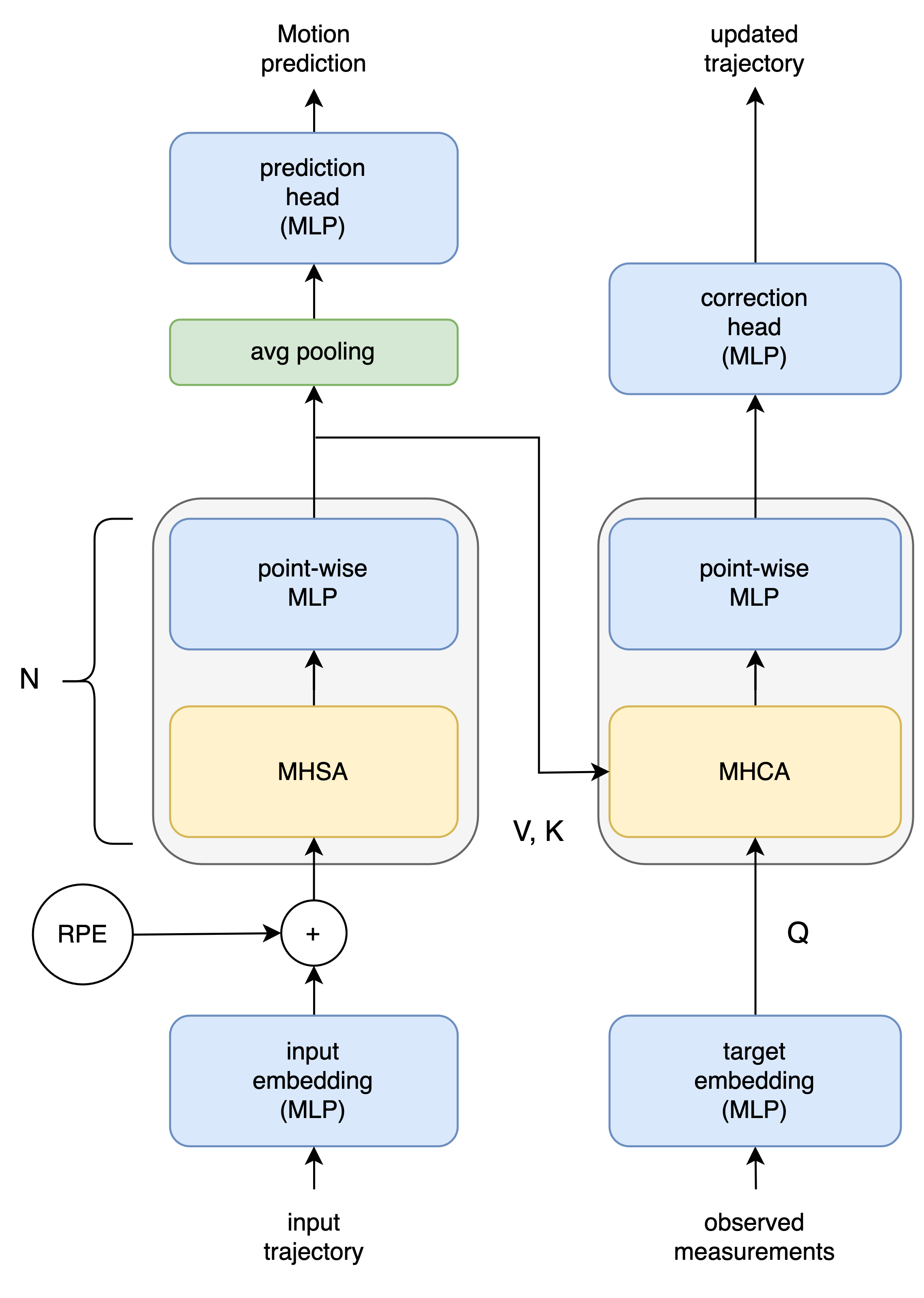
New!Engineering an Efficient Object Tracker for Non-Linear Motion
Momir Adv{z}emovi'c, Predrag Tadi'c, Andrija Petrovi'c, Mladen Nikoli'c
0
0
The goal of multi-object tracking is to detect and track all objects in a scene while maintaining unique identifiers for each, by associating their bounding boxes across video frames. This association relies on matching motion and appearance patterns of detected objects. This task is especially hard in case of scenarios involving dynamic and non-linear motion patterns. In this paper, we introduce DeepMoveSORT, a novel, carefully engineered multi-object tracker designed specifically for such scenarios. In addition to standard methods of appearance-based association, we improve motion-based association by employing deep learnable filters (instead of the most commonly used Kalman filter) and a rich set of newly proposed heuristics. Our improvements to motion-based association methods are severalfold. First, we propose a new transformer-based filter architecture, TransFilter, which uses an object's motion history for both motion prediction and noise filtering. We further enhance the filter's performance by careful handling of its motion history and accounting for camera motion. Second, we propose a set of heuristics that exploit cues from the position, shape, and confidence of detected bounding boxes to improve association performance. Our experimental evaluation demonstrates that DeepMoveSORT outperforms existing trackers in scenarios featuring non-linear motion, surpassing state-of-the-art results on three such datasets. We also perform a thorough ablation study to evaluate the contributions of different tracker components which we proposed. Based on our study, we conclude that using a learnable filter instead of the Kalman filter, along with appearance-based association is key to achieving strong general tracking performance.
7/2/2024