Vision-and-Language Navigation via Causal Learning

0

Sign in to get full access
Overview
- This paper proposes a novel approach to Vision-and-Language Navigation (VLN) using causal learning.
- The key idea is to learn causal relationships between vision, language, and actions to improve the agent's navigation performance.
- The authors introduce a causal graph-based model and a training procedure that leverages causal interventions to learn these relationships.
- Experiments on standard VLN benchmarks show significant improvements over existing methods.
Plain English Explanation
The paper is about making it easier for AI systems to navigate through virtual environments based on instructions given in natural language. This is a challenging problem because the AI needs to understand the relationship between what it sees, what it's told to do, and the actions it should take.
The researchers propose a new approach that uses "causal learning" to model these relationships. Instead of just trying to memorize the instructions and visual cues, the AI system learns the underlying causes and effects that link language, vision, and actions. This allows it to better generalize to new situations and follow instructions more accurately.
For example, if the AI is told to "go to the red chair", it not only needs to recognize the red chair visually, but also understand that "going to" means moving towards that object. By learning these causal connections, the AI can better adapt when the instructions or environment change.
The paper demonstrates that this causal learning approach outperforms existing methods on standard benchmarks for vision-and-language navigation. This suggests it could be a promising direction for building more capable and flexible AI assistants that can understand and follow natural language instructions in complex environments.
Technical Explanation
The paper introduces a new framework for Vision-and-Language Navigation (VLN) that leverages causal learning. The key idea is to model the causal relationships between vision, language, and actions, rather than just learning a direct mapping from instructions to actions.
The authors propose a causal graph-based model that represents these relationships. During training, they use causal interventions - deliberately intervening on parts of the graph to learn the underlying causal structure. This allows the model to better generalize and follow instructions in novel environments, compared to previous approaches that relied more on memorization.
The training process involves several steps:
- Constructing the causal graph over the relevant variables (visual observations, language instructions, and navigation actions).
- Performing causal interventions by modifying parts of the graph and observing the effects on the agent's behavior.
- Updating the model parameters to align the causal structure with the observed effects of the interventions.
The authors evaluate their approach on standard VLN benchmarks, including Room-to-Room (R2R) and Touchdown. The results show significant improvements over previous state-of-the-art methods, demonstrating the benefits of the causal learning framework.
Critical Analysis
The paper presents a compelling approach to Vision-and-Language Navigation that addresses some key limitations of prior work. By explicitly modeling the causal relationships between vision, language, and actions, the proposed model is able to better generalize and follow natural language instructions, even in novel environments.
One potential limitation is the complexity of the causal graph and the challenges involved in learning the full causal structure. The authors mention that their current approach relies on some simplifying assumptions and may not capture all the nuances of the problem domain. Further research is needed to scale the causal modeling to more realistic and complex scenarios.
Additionally, the paper does not provide a deep analysis of the learned causal relationships or explore how they differ from the intuitions of human experts. Examining the interpretability and transparency of the causal models could be an interesting direction for future work.
Overall, the paper presents a promising step towards building more capable and flexible AI agents that can understand and follow natural language instructions in complex, multimodal environments. The causal learning approach could have broader implications for other areas of AI that involve reasoning about the relationships between different modalities of information.
Conclusion
This paper introduces a novel approach to Vision-and-Language Navigation that uses causal learning to model the relationships between vision, language, and actions. By explicitly learning the causal structure underlying the task, the proposed model is able to better generalize and follow natural language instructions, even in novel environments.
The results demonstrate significant improvements over existing methods on standard benchmarks, suggesting that the causal learning framework is a promising direction for building more capable and flexible AI assistants that can understand and follow natural language instructions in complex, multimodal settings. Further research is needed to scale the approach and explore the interpretability of the learned causal models, but this work represents an important step forward in the field of vision-and-language navigation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Vision-and-Language Navigation via Causal Learning
Liuyi Wang, Zongtao He, Ronghao Dang, Mengjiao Shen, Chengju Liu, Qijun Chen
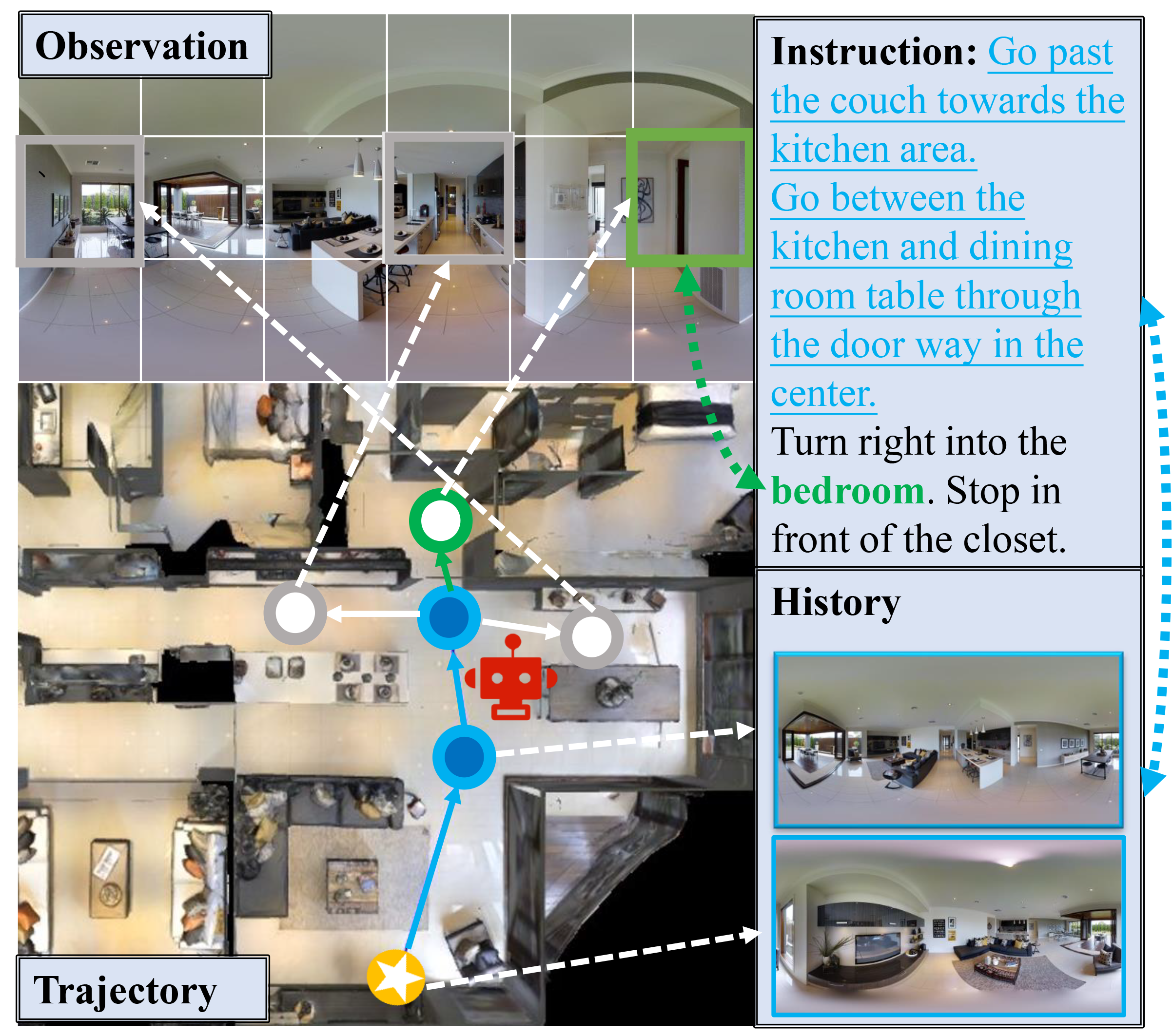
In the pursuit of robust and generalizable environment perception and language understanding, the ubiquitous challenge of dataset bias continues to plague vision-and-language navigation (VLN) agents, hindering their performance in unseen environments. This paper introduces the generalized cross-modal causal transformer (GOAT), a pioneering solution rooted in the paradigm of causal inference. By delving into both observable and unobservable confounders within vision, language, and history, we propose the back-door and front-door adjustment causal learning (BACL and FACL) modules to promote unbiased learning by comprehensively mitigating potential spurious correlations. Additionally, to capture global confounder features, we propose a cross-modal feature pooling (CFP) module supervised by contrastive learning, which is also shown to be effective in improving cross-modal representations during pre-training. Extensive experiments across multiple VLN datasets (R2R, REVERIE, RxR, and SOON) underscore the superiority of our proposed method over previous state-of-the-art approaches. Code is available at https://github.com/CrystalSixone/VLN-GOAT.
Read more4/17/2024
0
DELAN: Dual-Level Alignment for Vision-and-Language Navigation by Cross-Modal Contrastive Learning
Mengfei Du, Binhao Wu, Jiwen Zhang, Zhihao Fan, Zejun Li, Ruipu Luo, Xuanjing Huang, Zhongyu Wei
Vision-and-Language navigation (VLN) requires an agent to navigate in unseen environment by following natural language instruction. For task completion, the agent needs to align and integrate various navigation modalities, including instruction, observation and navigation history. Existing works primarily concentrate on cross-modal attention at the fusion stage to achieve this objective. Nevertheless, modality features generated by disparate uni-encoders reside in their own spaces, leading to a decline in the quality of cross-modal fusion and decision. To address this problem, we propose a Dual-levEL AligNment (DELAN) framework by cross-modal contrastive learning. This framework is designed to align various navigation-related modalities before fusion, thereby enhancing cross-modal interaction and action decision-making. Specifically, we divide the pre-fusion alignment into dual levels: instruction-history level and landmark-observation level according to their semantic correlations. We also reconstruct a dual-level instruction for adaptation to the dual-level alignment. As the training signals for pre-fusion alignment are extremely limited, self-supervised contrastive learning strategies are employed to enforce the matching between different modalities. Our approach seamlessly integrates with the majority of existing models, resulting in improved navigation performance on various VLN benchmarks, including R2R, R4R, RxR and CVDN.
Read more4/3/2024

0
Vision-Language Navigation with Continual Learning
Zhiyuan Li, Yanfeng Lv, Ziqin Tu, Di Shang, Hong Qiao
Vision-language navigation (VLN) is a critical domain within embedded intelligence, requiring agents to navigate 3D environments based on natural language instructions. Traditional VLN research has focused on improving environmental understanding and decision accuracy. However, these approaches often exhibit a significant performance gap when agents are deployed in novel environments, mainly due to the limited diversity of training data. Expanding datasets to cover a broader range of environments is impractical and costly. We propose the Vision-Language Navigation with Continual Learning (VLNCL) paradigm to address this challenge. In this paradigm, agents incrementally learn new environments while retaining previously acquired knowledge. VLNCL enables agents to maintain an environmental memory and extract relevant knowledge, allowing rapid adaptation to new environments while preserving existing information. We introduce a novel dual-loop scenario replay method (Dual-SR) inspired by brain memory replay mechanisms integrated with VLN agents. This method facilitates consolidating past experiences and enhances generalization across new tasks. By utilizing a multi-scenario memory buffer, the agent efficiently organizes and replays task memories, thereby bolstering its ability to adapt quickly to new environments and mitigating catastrophic forgetting. Our work pioneers continual learning in VLN agents, introducing a novel experimental setup and evaluation metrics. We demonstrate the effectiveness of our approach through extensive evaluations and establish a benchmark for the VLNCL paradigm. Comparative experiments with existing continual learning and VLN methods show significant improvements, achieving state-of-the-art performance in continual learning ability and highlighting the potential of our approach in enabling rapid adaptation while preserving prior knowledge.
Read more9/24/2024

0
Cog-GA: A Large Language Models-based Generative Agent for Vision-Language Navigation in Continuous Environments
Zhiyuan Li, Yanfeng Lu, Yao Mu, Hong Qiao
Vision Language Navigation in Continuous Environments (VLN-CE) represents a frontier in embodied AI, demanding agents to navigate freely in unbounded 3D spaces solely guided by natural language instructions. This task introduces distinct challenges in multimodal comprehension, spatial reasoning, and decision-making. To address these challenges, we introduce Cog-GA, a generative agent founded on large language models (LLMs) tailored for VLN-CE tasks. Cog-GA employs a dual-pronged strategy to emulate human-like cognitive processes. Firstly, it constructs a cognitive map, integrating temporal, spatial, and semantic elements, thereby facilitating the development of spatial memory within LLMs. Secondly, Cog-GA employs a predictive mechanism for waypoints, strategically optimizing the exploration trajectory to maximize navigational efficiency. Each waypoint is accompanied by a dual-channel scene description, categorizing environmental cues into 'what' and 'where' streams as the brain. This segregation enhances the agent's attentional focus, enabling it to discern pertinent spatial information for navigation. A reflective mechanism complements these strategies by capturing feedback from prior navigation experiences, facilitating continual learning and adaptive replanning. Extensive evaluations conducted on VLN-CE benchmarks validate Cog-GA's state-of-the-art performance and ability to simulate human-like navigation behaviors. This research significantly contributes to the development of strategic and interpretable VLN-CE agents.
Read more9/24/2024