On Vision Transformers for Classification Tasks in Side-Scan Sonar Imagery

0

Sign in to get full access
Overview
- This paper examines the use of vision transformers for classification tasks on side-scan sonar imagery.
- The researchers evaluate the performance of vision transformers compared to convolutional neural networks (CNNs) on a side-scan sonar dataset.
- They also investigate how different architectural choices and training strategies impact the vision transformer's effectiveness.
Plain English Explanation
Side-scan sonar is a type of underwater imaging technology that captures detailed pictures of the seafloor. These images can be used to identify objects, structures, and other features on the ocean bottom. Vision transformers are a relatively new type of deep learning model that have shown promise for a variety of computer vision tasks.
In this paper, the researchers wanted to see how well vision transformers would perform on the task of classifying objects in side-scan sonar images, compared to more traditional convolutional neural networks (CNNs). They tested different variations of the vision transformer architecture and training approaches to understand which factors led to the best performance.
The results suggest that vision transformers can be effective for classifying objects in side-scan sonar imagery, and may even outperform CNN-based models in some cases. The researchers provide insights into how the architectural choices and training strategies impact the vision transformer's capabilities on this type of data.
Technical Explanation
The paper evaluates the use of vision transformers for object classification in side-scan sonar imagery. The researchers compare the performance of vision transformers to convolutional neural networks (CNNs), which have been the dominant model architecture for computer vision tasks.
The authors experiment with different vision transformer configurations, including variations in the number of transformer layers, patch sizes, and training strategies. They assess the models' classification accuracy on a dataset of side-scan sonar images containing various seabed objects.
The results show that vision transformers can achieve competitive or even superior performance compared to CNN-based models on this task. The researchers provide insights into how design choices, such as patch size and the number of transformer layers, impact the vision transformer's effectiveness. They also find that pre-training the vision transformer on a large general image dataset can improve its performance on the side-scan sonar classification task.
Critical Analysis
The paper provides a thorough evaluation of vision transformers for side-scan sonar image classification, exploring several architectural variations and training strategies. The results suggest that vision transformers can be a promising alternative to CNNs for this type of underwater imaging task.
However, the authors acknowledge that their experiments are limited to a single dataset, and further research is needed to verify the generalizability of their findings to other side-scan sonar datasets and scenarios. Additionally, the paper does not delve into potential limitations or failure cases of the vision transformer approach, which would be valuable for understanding its practical applicability and future research directions.
Comparative studies on the use of vision transformers for other types of remote sensing and texture analysis tasks could provide additional insights into the strengths and weaknesses of this model architecture compared to CNNs.
Conclusion
This paper explores the potential of vision transformers for object classification tasks in side-scan sonar imagery. The results suggest that vision transformers can achieve competitive or even superior performance compared to convolutional neural networks (CNNs) on this type of underwater imaging data.
The researchers provide valuable insights into how architectural choices and training strategies impact the vision transformer's effectiveness, which can inform future work on applying these models to side-scan sonar and other remote sensing applications. Further research is needed to verify the generalizability of these findings and explore the limitations of vision transformers for underwater image analysis tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!On Vision Transformers for Classification Tasks in Side-Scan Sonar Imagery
BW Sheffield, Jeffrey Ellen, Ben Whitmore
Side-scan sonar (SSS) imagery presents unique challenges in the classification of man-made objects on the seafloor due to the complex and varied underwater environments. Historically, experts have manually interpreted SSS images, relying on conventional machine learning techniques with hand-crafted features. While Convolutional Neural Networks (CNNs) significantly advanced automated classification in this domain, they often fall short when dealing with diverse seafloor textures, such as rocky or ripple sand bottoms, where false positive rates may increase. Recently, Vision Transformers (ViTs) have shown potential in addressing these limitations by utilizing a self-attention mechanism to capture global information in image patches, offering more flexibility in processing spatial hierarchies. This paper rigorously compares the performance of ViT models alongside commonly used CNN architectures, such as ResNet and ConvNext, for binary classification tasks in SSS imagery. The dataset encompasses diverse geographical seafloor types and is balanced between the presence and absence of man-made objects. ViT-based models exhibit superior classification performance across f1-score, precision, recall, and accuracy metrics, although at the cost of greater computational resources. CNNs, with their inductive biases, demonstrate better computational efficiency, making them suitable for deployment in resource-constrained environments like underwater vehicles. Future research directions include exploring self-supervised learning for ViTs and multi-modal fusion to further enhance performance in challenging underwater environments.
Read more9/19/2024
0
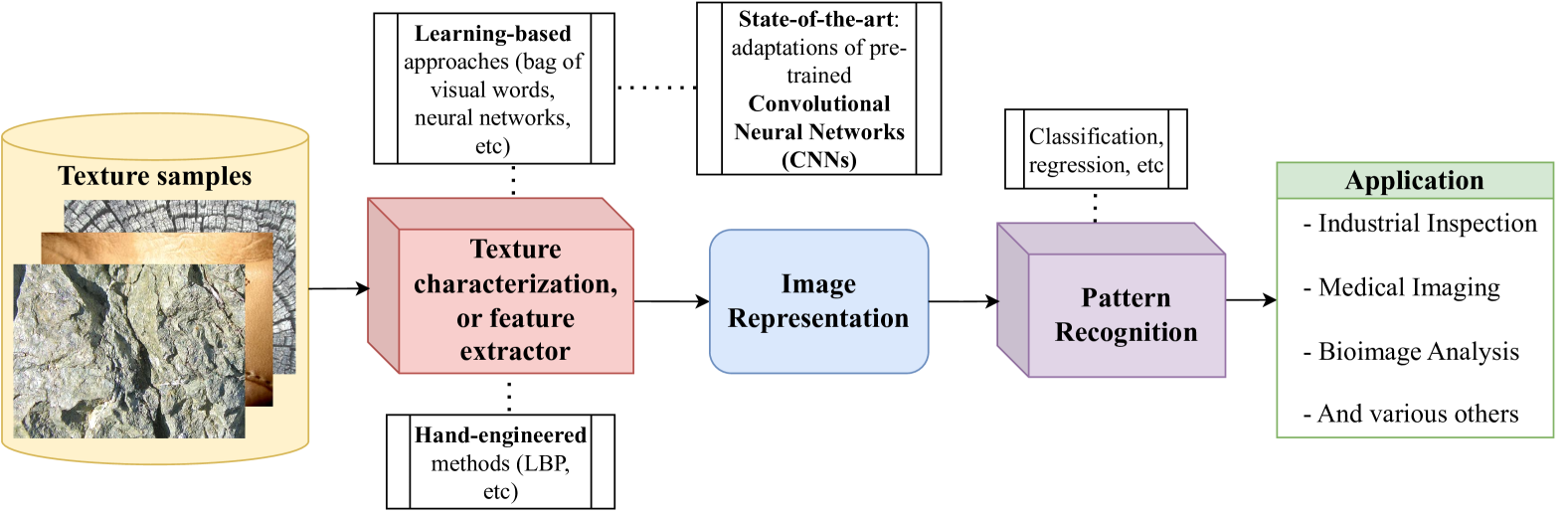
A Comparative Survey of Vision Transformers for Feature Extraction in Texture Analysis
Leonardo Scabini, Andre Sacilotti, Kallil M. Zielinski, Lucas C. Ribas, Bernard De Baets, Odemir M. Bruno
Texture, a significant visual attribute in images, has been extensively investigated across various image recognition applications. Convolutional Neural Networks (CNNs), which have been successful in many computer vision tasks, are currently among the best texture analysis approaches. On the other hand, Vision Transformers (ViTs) have been surpassing the performance of CNNs on tasks such as object recognition, causing a paradigm shift in the field. However, ViTs have so far not been scrutinized for texture recognition, hindering a proper appreciation of their potential in this specific setting. For this reason, this work explores various pre-trained ViT architectures when transferred to tasks that rely on textures. We review 21 different ViT variants and perform an extensive evaluation and comparison with CNNs and hand-engineered models on several tasks, such as assessing robustness to changes in texture rotation, scale, and illumination, and distinguishing color textures, material textures, and texture attributes. The goal is to understand the potential and differences among these models when directly applied to texture recognition, using pre-trained ViTs primarily for feature extraction and employing linear classifiers for evaluation. We also evaluate their efficiency, which is one of the main drawbacks in contrast to other methods. Our results show that ViTs generally outperform both CNNs and hand-engineered models, especially when using stronger pre-training and tasks involving in-the-wild textures (images from the internet). We highlight the following promising models: ViT-B with DINO pre-training, BeiTv2, and the Swin architecture, as well as the EfficientFormer as a low-cost alternative. In terms of efficiency, although having a higher number of GFLOPs and parameters, ViT-B and BeiT(v2) can achieve a lower feature extraction time on GPUs compared to ResNet50.
Read more6/11/2024
👀
0
Vision Transformers: From Semantic Segmentation to Dense Prediction
Li Zhang, Jiachen Lu, Sixiao Zheng, Xinxuan Zhao, Xiatian Zhu, Yanwei Fu, Tao Xiang, Jianfeng Feng, Philip H. S. Torr
The emergence of vision transformers (ViTs) in image classification has shifted the methodologies for visual representation learning. In particular, ViTs learn visual representation at full receptive field per layer across all the image patches, in comparison to the increasing receptive fields of CNNs across layers and other alternatives (e.g., large kernels and atrous convolution). In this work, for the first time we explore the global context learning potentials of ViTs for dense visual prediction (e.g., semantic segmentation). Our motivation is that through learning global context at full receptive field layer by layer, ViTs may capture stronger long-range dependency information, critical for dense prediction tasks. We first demonstrate that encoding an image as a sequence of patches, a vanilla ViT without local convolution and resolution reduction can yield stronger visual representation for semantic segmentation. For example, our model, termed as SEgmentation TRansformer (SETR), excels on ADE20K (50.28% mIoU, the first position in the test leaderboard on the day of submission) and performs competitively on Cityscapes. However, the basic ViT architecture falls short in broader dense prediction applications, such as object detection and instance segmentation, due to its lack of a pyramidal structure, high computational demand, and insufficient local context. For tackling general dense visual prediction tasks in a cost-effective manner, we further formulate a family of Hierarchical Local-Global (HLG) Transformers, characterized by local attention within windows and global-attention across windows in a pyramidal architecture. Extensive experiments show that our methods achieve appealing performance on a variety of dense prediction tasks (e.g., object detection and instance segmentation and semantic segmentation) as well as image classification.
Read more8/6/2024

0
Multi-Modal Vision Transformers for Crop Mapping from Satellite Image Time Series
Theresa Follath, David Mickisch, Jan Hemmerling, Stefan Erasmi, Marcel Schwieder, Begum Demir
Using images acquired by different satellite sensors has shown to improve classification performance in the framework of crop mapping from satellite image time series (SITS). Existing state-of-the-art architectures use self-attention mechanisms to process the temporal dimension and convolutions for the spatial dimension of SITS. Motivated by the success of purely attention-based architectures in crop mapping from single-modal SITS, we introduce several multi-modal multi-temporal transformer-based architectures. Specifically, we investigate the effectiveness of Early Fusion, Cross Attention Fusion and Synchronized Class Token Fusion within the Temporo-Spatial Vision Transformer (TSViT). Experimental results demonstrate significant improvements over state-of-the-art architectures with both convolutional and self-attention components.
Read more6/26/2024