VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual Descriptions

0

Sign in to get full access
Overview
- Introduces VisionTrap, a system for improving trajectory prediction using vision and textual descriptions
- Leverages the nuScenes-Text dataset, which provides natural language descriptions for driving scenes
- Aims to enhance autonomous driving capabilities by incorporating visual and language information
Plain English Explanation
VisionTrap is a new approach for predicting the future paths of objects, like vehicles, in a driving scene. Traditional trajectory prediction models only use sensor data like camera images and lidar. VisionTrap adds another important piece: textual descriptions of the driving scene.
By combining vision and language, VisionTrap can better understand the context and intention behind the movements of objects. For example, if a text description mentions a pedestrian crossing the street, VisionTrap can use that information to more accurately predict the trajectory of the nearby vehicles.
The researchers trained and evaluated VisionTrap using the nuScenes-Text dataset, which provides natural language descriptions for driving scenes. This dataset helps VisionTrap learn how to connect visual cues with semantic understanding of the environment.
Improving trajectory prediction is crucial for autonomous driving systems to safely navigate complex real-world scenarios. VisionTrap's ability to leverage both vision and language represents an important step towards more robust and capable self-driving cars.
Technical Explanation
VisionTrap is a novel approach for trajectory prediction that combines visual inputs from cameras with textual descriptions of the driving scene. The system is trained and evaluated using the nuScenes-Text dataset, which provides natural language annotations for driving scenes.
The core architecture of VisionTrap consists of three main components:
- Vision Encoder: A convolutional neural network that encodes visual information from camera images.
- Language Encoder: A transformer-based language model that encodes the textual descriptions of the driving scene.
- Trajectory Prediction Head: A module that combines the encoded visual and language features to predict the future trajectories of objects in the scene.
During training, VisionTrap learns to associate the visual cues with the corresponding textual descriptions, allowing it to develop a richer understanding of the driving context. This contextual awareness is then leveraged to produce more accurate trajectory predictions compared to vision-only models.
The researchers evaluate VisionTrap on several autonomous driving benchmarks and demonstrate significant performance improvements over state-of-the-art baselines. The system also shows promising results in generating controllable video predictions based on the provided textual descriptions.
Critical Analysis
The key strength of VisionTrap is its ability to leverage both visual and language information to enhance trajectory prediction. By incorporating textual descriptions, the system can better capture the semantic context of the driving scene, which is crucial for anticipating the future movements of objects.
However, the paper does not provide a detailed analysis of the system's performance under different environmental conditions or edge cases. It would be helpful to understand how VisionTrap handles challenging scenarios, such as occlusions, unexpected events, or unseen situations not covered in the training data.
Additionally, the paper does not discuss the computational overhead and real-time inference capabilities of VisionTrap, which are crucial factors for deploying such systems in autonomous driving applications. Further research is needed to assess the system's suitability for practical, large-scale deployment.
Conclusion
VisionTrap represents an important step towards more robust and reliable trajectory prediction for autonomous driving systems. By leveraging both visual and language information, the system can better understand the context and intention behind the movements of objects in a driving scene, leading to more accurate predictions.
The use of the nuScenes-Text dataset is a valuable contribution, as it provides a rich source of natural language annotations that can help advance the field of vision-language integration for various applications, including autonomous driving and video prediction.
As the research in this area continues, it will be important to further explore the limitations and practical considerations of systems like VisionTrap, ensuring they can be deployed safely and effectively in real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual Descriptions
Seokha Moon, Hyun Woo, Hongbeen Park, Haeji Jung, Reza Mahjourian, Hyung-gun Chi, Hyerin Lim, Sangpil Kim, Jinkyu Kim
Predicting future trajectories for other road agents is an essential task for autonomous vehicles. Established trajectory prediction methods primarily use agent tracks generated by a detection and tracking system and HD map as inputs. In this work, we propose a novel method that also incorporates visual input from surround-view cameras, allowing the model to utilize visual cues such as human gazes and gestures, road conditions, vehicle turn signals, etc, which are typically hidden from the model in prior methods. Furthermore, we use textual descriptions generated by a Vision-Language Model (VLM) and refined by a Large Language Model (LLM) as supervision during training to guide the model on what to learn from the input data. Despite using these extra inputs, our method achieves a latency of 53 ms, making it feasible for real-time processing, which is significantly faster than that of previous single-agent prediction methods with similar performance. Our experiments show that both the visual inputs and the textual descriptions contribute to improvements in trajectory prediction performance, and our qualitative analysis highlights how the model is able to exploit these additional inputs. Lastly, in this work we create and release the nuScenes-Text dataset, which augments the established nuScenes dataset with rich textual annotations for every scene, demonstrating the positive impact of utilizing VLM on trajectory prediction. Our project page is at https://moonseokha.github.io/VisionTrap/
Read more7/18/2024

0
TGS: Trajectory Generation and Selection using Vision Language Models in Mapless Outdoor Environments
Daeun Song, Jing Liang, Xuesu Xiao, Dinesh Manocha
We present a multi-modal trajectory generation and selection algorithm for real-world mapless outdoor navigation in challenging scenarios with unstructured off-road features like buildings, grass, and curbs. Our goal is to compute suitable trajectories that (1) satisfy the environment-specific traversability constraints and (2) generate human-like paths while navigating in crosswalks, sidewalks, etc. Our formulation uses a Conditional Variational Autoencoder (CVAE) generative model enhanced with traversability constraints to generate multiple candidate trajectories for global navigation. We use VLMs and a visual prompting approach with their zero-shot ability of semantic understanding and logical reasoning to choose the best trajectory given the contextual information about the task. We evaluate our methods in various outdoor scenes with wheeled robots and compare the performance with other global navigation algorithms. In practice, we observe at least 3.35% improvement in traversability and 20.61% improvement in terms of human-like navigation in generated trajectories in challenging outdoor navigation scenarios.
Read more8/9/2024
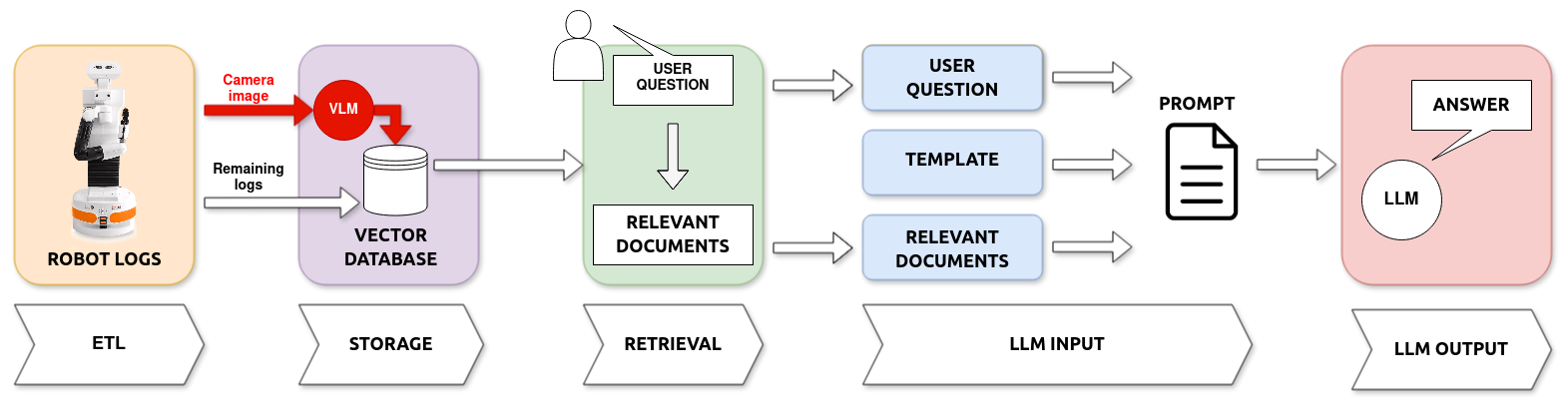
0
Enhancing Robot Explanation Capabilities through Vision-Language Models: a Preliminary Study by Interpreting Visual Inputs for Improved Human-Robot Interaction
David Sobr'in-Hidalgo, Miguel 'Angel Gonz'alez-Santamarta, 'Angel Manuel Guerrero-Higueras, Francisco Javier Rodr'iguez-Lera, Vicente Matell'an-Olivera
This paper presents an improved system based on our prior work, designed to create explanations for autonomous robot actions during Human-Robot Interaction (HRI). Previously, we developed a system that used Large Language Models (LLMs) to interpret logs and produce natural language explanations. In this study, we expand our approach by incorporating Vision-Language Models (VLMs), enabling the system to analyze textual logs with the added context of visual input. This method allows for generating explanations that combine data from the robot's logs and the images it captures. We tested this enhanced system on a basic navigation task where the robot needs to avoid a human obstacle. The findings from this preliminary study indicate that adding visual interpretation improves our system's explanations by precisely identifying obstacles and increasing the accuracy of the explanations provided.
Read more4/16/2024
🔮
0
Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models
Zhengxing Lan, Hongbo Li, Lingshan Liu, Bo Fan, Yisheng Lv, Yilong Ren, Zhiyong Cui
Predicting the future trajectories of dynamic traffic actors is a cornerstone task in autonomous driving. Though existing notable efforts have resulted in impressive performance improvements, a gap persists in scene cognitive and understanding of the complex traffic semantics. This paper proposes Traj-LLM, the first to investigate the potential of using Large Language Models (LLMs) without explicit prompt engineering to generate future motion from agents' past/observed trajectories and scene semantics. Traj-LLM starts with sparse context joint coding to dissect the agent and scene features into a form that LLMs understand. On this basis, we innovatively explore LLMs' powerful comprehension abilities to capture a spectrum of high-level scene knowledge and interactive information. Emulating the human-like lane focus cognitive function and enhancing Traj-LLM's scene comprehension, we introduce lane-aware probabilistic learning powered by the pioneering Mamba module. Finally, a multi-modal Laplace decoder is designed to achieve scene-compliant multi-modal predictions. Extensive experiments manifest that Traj-LLM, fortified by LLMs' strong prior knowledge and understanding prowess, together with lane-aware probability learning, outstrips state-of-the-art methods across evaluation metrics. Moreover, the few-shot analysis further substantiates Traj-LLM's performance, wherein with just 50% of the dataset, it outperforms the majority of benchmarks relying on complete data utilization. This study explores equipping the trajectory prediction task with advanced capabilities inherent in LLMs, furnishing a more universal and adaptable solution for forecasting agent motion in a new way.
Read more5/9/2024