TGS: Trajectory Generation and Selection using Vision Language Models in Mapless Outdoor Environments

0

Sign in to get full access
Overview
- Proposes a novel trajectory generation and selection approach using vision-language models for outdoor environments without maps
- Leverages pre-trained vision-language models to generate diverse trajectory proposals and select the most suitable one
- Demonstrated on challenging outdoor navigation tasks, outperforming traditional planning methods
Plain English Explanation
This paper introduces a new way to help robots navigate through outdoor environments without access to detailed maps. The key idea is to use [object Object], which are AI systems that can understand and describe images and scenes using natural language.
The researchers developed a system that can [object Object] for the robot to take, based on its current view of the environment. It then [object Object] by evaluating how well each one aligns with the robot's goals and constraints.
This approach allows the robot to navigate successfully even in unfamiliar outdoor areas where detailed maps may not be available. The researchers tested their system on challenging navigation tasks and found that it outperformed traditional planning methods.
Technical Explanation
The core of the proposed [object Object] system is the use of pre-trained [object Object] to generate and evaluate potential trajectories.
First, the system uses a vision-language model to [object Object] based on the robot's current visual input. These trajectories are represented as sequences of natural language descriptions that capture the intended path.
Next, the system [object Object] using a second vision-language model that assesses how well the trajectory aligns with the robot's goal and constraints, such as avoiding obstacles or maintaining a certain speed.
The trajectory with the highest evaluation score is then [selected and executed] by the robot to navigate the environment.
The researchers demonstrated the effectiveness of their TGS approach on several challenging outdoor navigation tasks, showing that it can outperform traditional planning methods that rely on detailed maps or hand-crafted heuristics.
Critical Analysis
The researchers acknowledge several limitations of the TGS approach. First, the performance of the system depends heavily on the quality and robustness of the pre-trained vision-language models used. If these models struggle to accurately understand the robot's visual input or generate appropriate trajectory descriptions, the overall system performance may suffer.
Additionally, the [object Object] can be computationally expensive, especially as the number of candidate trajectories increases. This may limit the real-time applicability of the system in some scenarios.
The researchers also note that their evaluation was primarily conducted in simulated environments, and further testing in real-world outdoor settings would be valuable to assess the system's robustness and generalization capabilities.
Conclusion
The TGS system proposed in this paper represents an innovative approach to autonomous navigation in outdoor environments without access to detailed maps. By leveraging [object Object], the system can generate diverse trajectory proposals and select the most suitable one based on the robot's goals and constraints.
This work demonstrates the potential of combining computer vision and natural language processing techniques to tackle complex robotic navigation challenges, particularly in unstructured environments where traditional planning methods may struggle. Further research and real-world validation could lead to more robust and adaptable navigation solutions for a wide range of robotics applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
TGS: Trajectory Generation and Selection using Vision Language Models in Mapless Outdoor Environments
Daeun Song, Jing Liang, Xuesu Xiao, Dinesh Manocha
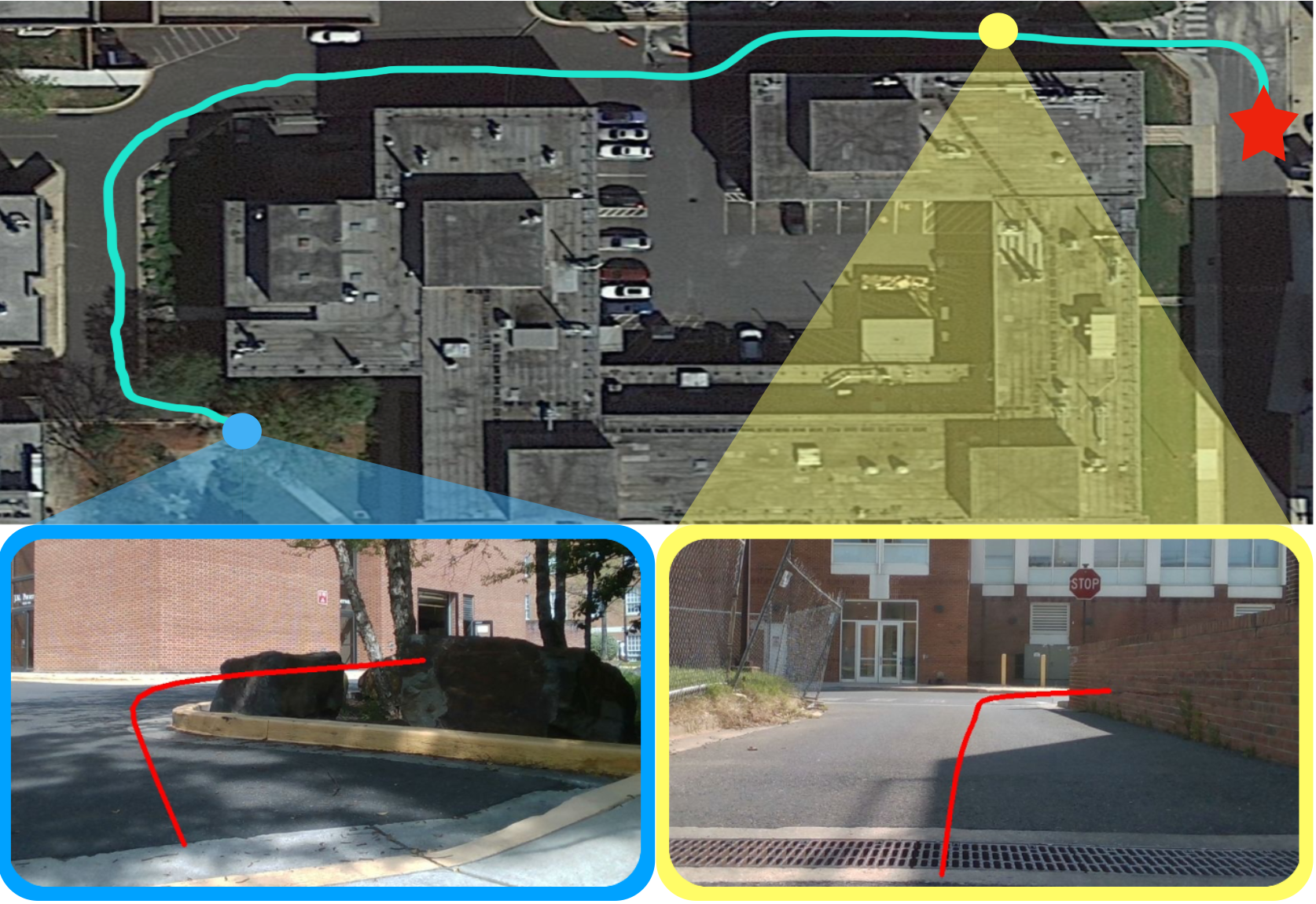
We present a multi-modal trajectory generation and selection algorithm for real-world mapless outdoor navigation in challenging scenarios with unstructured off-road features like buildings, grass, and curbs. Our goal is to compute suitable trajectories that (1) satisfy the environment-specific traversability constraints and (2) generate human-like paths while navigating in crosswalks, sidewalks, etc. Our formulation uses a Conditional Variational Autoencoder (CVAE) generative model enhanced with traversability constraints to generate multiple candidate trajectories for global navigation. We use VLMs and a visual prompting approach with their zero-shot ability of semantic understanding and logical reasoning to choose the best trajectory given the contextual information about the task. We evaluate our methods in various outdoor scenes with wheeled robots and compare the performance with other global navigation algorithms. In practice, we observe at least 3.35% improvement in traversability and 20.61% improvement in terms of human-like navigation in generated trajectories in challenging outdoor navigation scenarios.
Read more8/9/2024
0
DTG : Diffusion-based Trajectory Generation for Mapless Global Navigation
Jing Liang, Amirreza Payandeh, Daeun Song, Xuesu Xiao, Dinesh Manocha
We present a novel end-to-end diffusion-based trajectory generation method, DTG, for mapless global navigation in challenging outdoor scenarios with occlusions and unstructured off-road features like grass, buildings, bushes, etc. Given a distant goal, our approach computes a trajectory that satisfies the following goals: (1) minimize the travel distance to the goal; (2) maximize the traversability by choosing paths that do not lie in undesirable areas. Specifically, we present a novel Conditional RNN(CRNN) for diffusion models to efficiently generate trajectories. Furthermore, we propose an adaptive training method that ensures that the diffusion model generates more traversable trajectories. We evaluate our methods in various outdoor scenes and compare the performance with other global navigation algorithms on a Husky robot. In practice, we observe at least a 15% improvement in traveling distance and around a 7% improvement in traversability.
Read more9/4/2024

0
VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual Descriptions
Seokha Moon, Hyun Woo, Hongbeen Park, Haeji Jung, Reza Mahjourian, Hyung-gun Chi, Hyerin Lim, Sangpil Kim, Jinkyu Kim
Predicting future trajectories for other road agents is an essential task for autonomous vehicles. Established trajectory prediction methods primarily use agent tracks generated by a detection and tracking system and HD map as inputs. In this work, we propose a novel method that also incorporates visual input from surround-view cameras, allowing the model to utilize visual cues such as human gazes and gestures, road conditions, vehicle turn signals, etc, which are typically hidden from the model in prior methods. Furthermore, we use textual descriptions generated by a Vision-Language Model (VLM) and refined by a Large Language Model (LLM) as supervision during training to guide the model on what to learn from the input data. Despite using these extra inputs, our method achieves a latency of 53 ms, making it feasible for real-time processing, which is significantly faster than that of previous single-agent prediction methods with similar performance. Our experiments show that both the visual inputs and the textual descriptions contribute to improvements in trajectory prediction performance, and our qualitative analysis highlights how the model is able to exploit these additional inputs. Lastly, in this work we create and release the nuScenes-Text dataset, which augments the established nuScenes dataset with rich textual annotations for every scene, demonstrating the positive impact of utilizing VLM on trajectory prediction. Our project page is at https://moonseokha.github.io/VisionTrap/
Read more7/18/2024
📉
0
Wild Visual Navigation: Fast Traversability Learning via Pre-Trained Models and Online Self-Supervision
Mat'ias Mattamala, Jonas Frey, Piotr Libera, Nived Chebrolu, Georg Martius, Cesar Cadena, Marco Hutter, Maurice Fallon
Natural environments such as forests and grasslands are challenging for robotic navigation because of the false perception of rigid obstacles from high grass, twigs, or bushes. In this work, we present Wild Visual Navigation (WVN), an online self-supervised learning system for visual traversability estimation. The system is able to continuously adapt from a short human demonstration in the field, only using onboard sensing and computing. One of the key ideas to achieve this is the use of high-dimensional features from pre-trained self-supervised models, which implicitly encode semantic information that massively simplifies the learning task. Further, the development of an online scheme for supervision generator enables concurrent training and inference of the learned model in the wild. We demonstrate our approach through diverse real-world deployments in forests, parks, and grasslands. Our system is able to bootstrap the traversable terrain segmentation in less than 5 min of in-field training time, enabling the robot to navigate in complex, previously unseen outdoor terrains. Code: https://bit.ly/498b0CV - Project page:https://bit.ly/3M6nMHH
Read more4/11/2024